
计算机视觉是否已经进入瓶颈期?
链接:https://www.zhihu.com/question/51863955 编辑:深度学习与计算机视觉 声明:仅做学术分享,侵删

近些年来在机器学习(深度学习)的支持下,计算机视觉迅速发展,并且与ML的发展在图像数据处理的交集上绑定在了一起。但CV领域自身的理论发展仿佛速度在放缓,那么未来CV的发展会不会因为自身发展的不足而只能依托其他领域发展的支持,计算机视觉领域是否会产生饱和甚至萎缩。不论兴趣,单从时机考虑,现在进入这个领域还来得及吗?

作者:HeptaAI
先说结论:不,能做的方向太多了,但是比起以前需要能力或者更多时间:图像理解卷,但是是基础,要学但是可以不作为研究方向,图像理解的小样本学习、持续学习、医疗影像理解倒是比较乐观,3D也相对2D好一些;图像生成在大实验室,算力足,可以做;检索不推荐;Robotics建议大佬做,很有前景;图像序列的多目标跟踪、步态识别等建议专业Lab做;跨学科多模态很适合做,但是要学多个学科的知识。我们来看一下细致的分析:
图像理解(目标检测、图像分类、图像分割)这边,三个子领域都由于benchmark非常成熟,总体呈内卷态势,做的人很多,优秀的工作很少。仔细调查发现,这是行业的正常情况,因为这个领域和深度学习结合起来的发展时间是最长的,从李飞飞2009的ImageNet开始发展到现在,已经有13年的历史了,而ImageNet的benchmark已经相当完善,所以缺乏活力。我们总结了图像理解的突破口:一个是小样本学习的benchmark,建立一个有规模的迁移学习数据集;另一个是持续学习的benchmark。这两块,最近的会议都开始大量征稿,属于是热点方向。还有一个是医疗图像理解特别是MRI,这一块属于是造福人类的领域,世界各国给的Funding都很足。1个点在通用领域没什么价值,但在手术台上可能就直接决定一个人的生命。有研究指出多目标的工作还差点火候,可以继续做;但我们自己调查了论文的数量和质量,认为其实这也属于卷的比较严重的一边,厉害的模型像是YOLO,已经做到了非常好的效果,之后基本没有让人耳目一新的模型出现。另外,3D领域相对2D会好一些。 图像生成(超分辨率、文本to图像、图像去噪、风格迁移)这一块,超分辨率基本已经做烂了,而且因为本身就是个比较简单的task,内卷非常严重;文本to图像这一块卷倒是不卷,经常有好的工作出来,问题是好的工作都是几千亿算力的大公司例如Google在做,例如前段时间的DALL-E,如果在一般的实验室不建议入坑,很容易做完实验写paper的时候突然发现已经被大厂做完了,沦成同期工作;图像去噪是一个相对小众的分支,想入门看这个综述,主要与在MRI结合的方向比较有实用价值,所以可以预计这一块前景不错。风格迁移这边谈不上卷,但是跟艺术结合的领域Funding明显不够,就业面也窄,所以目前阶段各种评价都偏娱乐向。 图像检索(以图搜图、以文搜图)其实本质还是图像理解,而且算是一个已经比较成熟的区域了,例如搜索引擎、相似度推荐等,10年左右开始技术飞跃就困难重重了。现在这一块很少有Lab在做了,慎入。 Robotics(计算机视觉在无人车、无人机、机械臂上的应用)这一块,能做的还有太多。这一块用到深度学习(基于统计的方法)的还很少,基本都是基于规则的方法,其实计算机图形学更多一些。最热门的算法像是SLAM,都是被规则方法统治的。问题是,想要把计算机视觉用到这些科目上的难度非常大,改模型调参的结果没有规则方法好。所以做这个方向数学一定要好,否则很容易变成做横向,我们隔壁Lab就大量接横向,研究性质的paper发的不多。 图像序列(目标跟踪、图像序列分类、步态识别)其实就是一串图片拼起来,多了个时间维度,这块总体就业面稍窄,无外乎安防监控、无人驾驶两个领域,这三个子领域相对更有前景。目标跟踪推荐多目标跟踪,应用价值最高,Funding也不错;热点在落地可行性,也就是实时监测和降低算力门槛。序列分类最火的是事件监测,在交通方面有比较大应用。步态识别属于偏小众的方向,但是图像序列的Lab一般都会涉猎,如果Lab是专做图像序列的,例如导师专门做这块,可以考虑入坑。图像序列工作总体上聚集程度高,在专业实验室会比较吃香。 与NLP的组合(特别是视频理解、视频生成、视频搜索,也就是上面三个经典图像命题的视频版本)这一块,基本上还在蓝海期。视频其实就是图像序列加上音频和文字信息。视频理解像是概括视频的内容、提取视频中的事件这些,跟图像序列主要多一个音频和文字,属于图像序列的超集。远机位视频理解的benchmark实在太少了,很缺苦干做数据集的人,现在风气太浮躁。视频理解里面,视频分类现在是大瓶颈,两三年了还是那个模型。视频生成像是从一幅图片生成一整个视频,研究算是非常火爆的,可以用作推理专家系统,从一幅图片里面进行有端联想。视频生成里面视频质量也是一个很值得做的方向,现在很多视频内容是优质的但分辨率太低,视频超分效率感人,这边的研究实在是少的可怜。视频搜索可以用来做视频推荐算法,作为视频除了标题的一个文本参照,在标题党越来越多的情况下提升推荐质量。视频这一块总体来说难度都比较大,需要对CV和NLP都有涉猎,所以你光会CV还是容易陷入内卷,博采众长才是王道。 多模态。这个学科就是大量知识的杂糅,其实也是一个跨学科的方向,还是很容易出paper的。其实视频方向也是一种多模态,但是和NLP的关系最大,也是多模态里面最火的一个方向,所以放到上面一条单独讲。因为我们并不认为多模态是CV的一个部分,而是CV的超集,因此没有做重点survey。
作者:陀飞轮
https://www.zhihu.com/question/51863955/answer/1879155038
先说结论:从2021年时间节点看,计算机视觉已经进入了瓶颈期。
最近计算机视觉入了Transformer,热度空前高涨,我觉得CV用Transformer我还能理解,这对于多模态统一架构来说是有意义的。
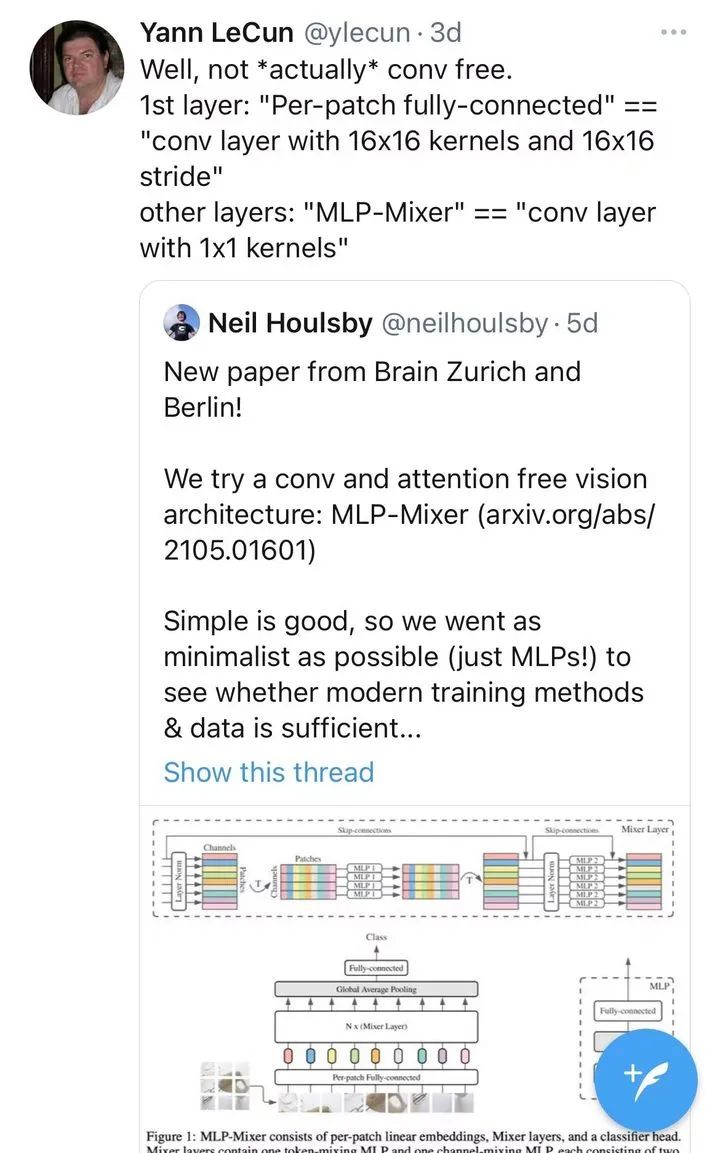
在我的认知里,大组应该利用好自身的资源人才影响力做一些推动领域发展的工作,现在已经沦落到把MLP翻出来炒冷饭的地步了吗?
种种怪异的现象足以说明计算机视觉已经进入了瓶颈期。
作者:凤舞九天
https://www.zhihu.com/question/51863955/answer/1794052854
前面讲得已经挺好了,不过我作为一线的开发人员,我主要从工业界应用角度出发,说下自己的看法。
作者:CW不要無聊的風格
https://www.zhihu.com/question/51863955/answer/1844945081
揭露一个事实:
最大的瓶颈就是人心,来自于该领域下的研究/工作者,而非领域本身。
一直以来,无论是哪个领域,在发展了一定程度之后,总会有大部分人理所當然地觉得到了瓶颈期而放弃,但仍会有一小部分善于发现问题、认真观察与体验生活并且坚持不懈地尝试解决问题的人。
往期精彩:
完结!《机器学习 公式推导与代码实现》全书1-26章PPT下载
时隔一年!深度学习语义分割理论与代码实践指南.pdf第二版来了!