
更简单的掩码图像建模框架SimMIM介绍和PyTorch代码实现

来源:DeepHub IMBA 本文约4000字,建议阅读10+分钟 本文中我们介绍了 SimMIM,这是一种受掩码建模启发的强大 SSL 算法,其中一部分输入数据被掩码,模型的目标是最小化重建损失。
图像中的掩码技术

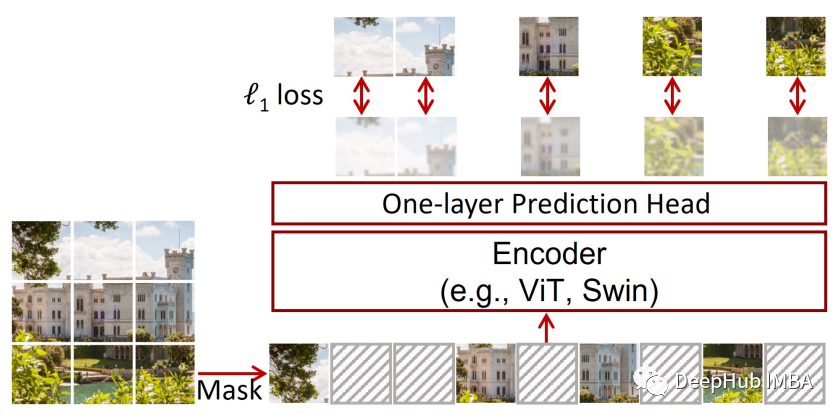
Pytorch实现
from torch import (
randn,
)
# tokens is currently a dummy tensor.
# Later, it will be replaced by the actual tokens
tokens = randn(batch_size, n_tokens, token_dim)from torch import (
randn,
)
tokens = randn(batch_size, n_tokens, token_dim)
indices_to_mask = randn(batch_size, n_tokens)
# Number of tokens to mask
# 50% of the total number of tokens performs well on average.
# However, for smaller patch sizes, a higher masking ratio is generally better.
# For example, for a patch size of 32, 0.5 performs well but for
# a patch size of 16, it would be worthwhile to increase it to 0.8.
n_masked_tokens = int(0.5*n_tokens)
# topk returns the k largest elements as well as their indices
# dim=1 tells it to find the maximum values and their indices
# on a per-row basis
# The indices of the tokens that are to be masked is going
# to be the indices of the n_masked_tokens largest values
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
# The largest values can be accesses via indices_to_mask.values,
# and their indices can be accessed via indices_to_mask.indices
indices_to_mask = indices_to_mask.indicesfrom torch import (
randn,
zeros,
)
tokens = randn(batch_size, n_tokens, token_dim)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
# Initially, bitmask is simply full of zeros (i.e., False)
bitmask = zeros(batch_size, n_tokens)
# What this line does is as follows:
# For every row i, bitmask[i][j] is replaced
# by the value argument (in this case 1), where j takes every value
# in indices_to_mask[i].
# For example, if indices_to_mask[3] is
# [2, 4, 7], then bitmask[3][2], bitmask[3][4], and bitmask[3][7]
# are all set to 1.
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()from torch import (
randn,
zeros,
)
# vit is assumed to be a vision transformer from timm
# To get tokens from a timm ViT, one must call its patch_embed method
# tokens is now of shape batch_size X n_tokens X token_dim
# Keep in mind that input is image data and of size
# batch_size X n_channels X height X width
tokens = vit.patch_embed(input)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()from torch import (
randn,
zeros,
)
from torch.nn import (
Parameter,
)
tokens = vit.patch_embed(input)
# The mask token itself is simply a vector of dimension token_dim
mask_token = Parameter(randn(token_dim))
# mask_token is repeated to make it the same shape as tokens
# mask_tokens is now of size batch_size X n_tokens X token_dim
mask_tokens = mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()from torch import (
randn,
zeros,
)
from torch.nn import (
Parameter,
)
tokens = vit.patch_embed(input)
mask_token = Parameter(randn(token_dim))
mask_tokens = mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()
# bitmask must have the same number of axes as tokens and mask_tokens
# Therefore, unsqueeze(2) adds an axis to it and it is now of shape batch_size X n_tokens X 1
bitmask = bitmask.unsqueeze(2)
# ~bitmask turns True to False and False to True
# Here, all that is taking place is (~bitmask) is multiplied by tokens
# to zero out every token that is supposed to be masked, and the result is added
# to bitmask*mask_tokens, in which everything is 0 except the tokens that are
# supposed to mask.
tokens = (~bitmask)*tokens + bitmask*mask_tokens然后就是位置嵌入
from torch import (
randn,
zeros,
)
from torch.nn import (
Parameter,
)
tokens = vit.patch_embed(input)
mask_token = Parameter(randn(token_dim))
mask_tokens = mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()
bitmask = bitmask.unsqueeze(2)
tokens = (~bitmask)*tokens + bitmask*mask_tokens
# In timm, a ViT's position embedding is accessible via vit.pos_embed
# The reason for vit.pos_embed[:, 1:] in place of simply vit.pos_embed
# is that the first position embedding vector is for the class token,
# which is not used for self-supervised learning.
tokens = tokens+vit.pos_embed[:, 1:]令牌可以被输入到 ViT获得它的编码表示。
from torch import (
randn,
zeros,
)
from torch.nn import (
Parameter,
)
tokens = vit.patch_embed(input)
mask_token = Parameter(randn(token_dim))
mask_tokens = mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()
bitmask = bitmask.unsqueeze(2)
tokens = (~bitmask)*tokens + bitmask*mask_tokens
tokens = tokens+vit.pos_embed[:, 1:]
# The encoded representation of tokens
encoded = vit.blocks(tokens)被屏蔽的令牌将从编码中获取,然后它们通过线性层来重建像素值。
from torch import (
randn,
zeros,
)
from torch.nn import (
Linear,
Parameter,
)
tokens = vit.patch_embed(input)
mask_token = Parameter(randn(token_dim))
mask_tokens = mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()
bitmask = bitmask.unsqueeze(2)
tokens = (~bitmask)*tokens + bitmask*mask_tokens
tokens = tokens+vit.pos_embed[:, 1:]
encoded = vit.blocks(tokens)
# To index input and encoded with bitmask,
# the axis that was added must be removed.
# This reverts bit_mask to a size of batch_size X n_tokens
bitmask = bitmask.squeeze(2)
# The encoded mask tokens, of shape batch_size X n_masked_tokens X token_dim
masked_tokens_encoded = encoded[bitmask]
# In timm, A ViT's patch height and width are vit.patch_embed.patch_size
patch_height = patch_width = vit.patch_embed.patch_size
# The input is the tokens,
# the output is the reconstructed raw pixel values.
# Therefore, the output shape is 3 (for 3 channels)
# multiplied by patch_height*patch_width, which is the original shape
# of the patches before they were tokenized
decoder_out_dim = 3*patch_height*patch_width
decoder = Linear(
in_features=token_dim,
out_features=decoder_out_dim,
)
# The reconstructed pixels, of shape batch_size X n_masked_tokens X 3*patch_height*patch_width
masked_patches_reconstructed = decoder(masked_tokens_encoded)from einops import (
rearrange,
)
from torch import (
randn,
zeros,
)
from torch.nn import (
Linear,
Parameter,
)
tokens = vit.patch_embed(input)
mask_token = torch.nn.Parameter(torch.randn(token_dim))
mask_tokens = self.mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()
bitmask = bitmask.unsqueeze(2)
tokens = (~bitmask)*tokens + bitmask*mask_tokens
tokens = tokens+vit.pos_embed[:, 1:]
encoded = vit.blocks(tokens)
bitmask = bitmask.squeeze(2)
masked_tokens_encoded = encoded[bitmask]
patch_height = patch_width = vit.patch_embed.patch_size
decoder_out_dim = 3*patch_height*patch_width
decoder = Linear(
in_features=token_dim,
out_features=decoder_out_dim,
)
masked_patches_reconstructed = decoder(masked_tokens_encoded)
# patterns tells einops how to rearrange the tensor
# Its layout is as follows: 'shape_before -> shape_after'
# In this case, the shape before would be batch_size X n_channels X height X width,
# and the shape after would be batch_size X n_tokens X n_channels*patch_height*patch_width
# However, in einops, variables that are in shape_before must be in shape_after as well and vice versa
# For example, in this case, height is in shape_before but not shape_after.
# Therefore, shape_before and shape_after must be restructured.
# Particularly, two new variables can be introduced, n_patches_height and n_patches_width,
# that say how many patches are along the height and width axes respectively.
# Thus, height = n_patches_height * patch_height,
# width = n_patches_width * patch_width, and
# n_tokens = n_patches_height * n_patches width
# Multiplying two variables in einops is denoted by (x y).
pattern = (
'batch_size n_channels (n_patches_height patch_height) (n_patches_width patch_width) -> '
'batch_size (n_patches_height n_patches_width) (n_channels patch_height patch_width)'
)
# einops.rearrange is like torch.reshape
# einops cannot infer patch_height and patch_width,
# so they must be passed manually
# patches is now of shape batch_size X n_tokens X 3*patch_height*patch_width
patches = rearrange(
tensor=input,
pattern=pattern,
patch_height=patch_height,
patch_width=patch_width,
)得对应于 masked_patches_reconstructed 的patche部分,
from einops import (
rearrange,
)
from torch import (
randn,
zeros,
)
from torch.nn import (
Linear,
Parameter,
)
tokens = vit.patch_embed(input)
mask_token = torch.nn.Parameter(torch.randn(token_dim))
mask_tokens = self.mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()
bitmask = bitmask.unsqueeze(2)
tokens = (~bitmask)*tokens + bitmask*mask_tokens
tokens = tokens+vit.pos_embed[:, 1:]
encoded = vit.blocks(tokens)
bitmask = bitmask.squeeze(2)
masked_tokens_encoded = encoded[bitmask]
patch_height = patch_width = vit.patch_embed.patch_size
decoder_out_dim = 3*patch_height*patch_width
decoder = Linear(
in_features=token_dim,
out_features=decoder_out_dim,
)
masked_patches_reconstructed = decoder(masked_tokens_encoded)
pattern = (
'batch_size n_channels (n_patches_height patch_height) (n_patches_width patch_width) -> '
'batch_size (n_patches_height n_patches_width) (n_channels patch_height patch_width)'
)
patches = einops.rearrange(
tensor=input,
pattern=pattern,
patch_height=patch_height,
patch_width=patch_width,
)
# Similar to how masked_tokens_encoded was computed
maskes_patches_original = patches[bitmask]评估损失。
from einops import (
rearrange,
)
from torch import (
randn,
zeros,
)
from torch.nn import (
Linear,
Parameter,
)
from torch.nn.functional import (
l1_loss,
)
tokens = vit.patch_embed(input)
mask_token = torch.nn.Parameter(torch.randn(token_dim))
mask_tokens = self.mask_token.repeat(batch_size, n_tokens, 1)
indices_to_mask = randn(batch_size, n_tokens)
n_masked_tokens = int(0.5*n_tokens)
indices_to_mask = indices_to_mask.topk(
k=n_masked_tokens,
dim=1,
)
indices_to_mask = indices_to_mask.indices
bitmask = zeros(batch_size, n_tokens)
bitmask = bitmask.scatter(
dim=1,
index=indices_to_mask,
value=1,
)
bitmask = bitmask.bool()
bitmask = bitmask.unsqueeze(2)
tokens = (~bitmask)*tokens + bitmask*mask_tokens
tokens = tokens+vit.pos_embed[:, 1:]
encoded = vit.blocks(tokens)
bitmask = bitmask.squeeze(2)
masked_tokens_encoded = encoded[bitmask]
patch_height = patch_width = vit.patch_embed.patch_size
decoder_out_dim = 3*patch_height*patch_width
decoder = Linear(
in_features=token_dim,
out_features=decoder_out_dim,
)
masked_patches_reconstructed = decoder(masked_tokens_encoded)
pattern = (
'batch_size n_channels (n_patches_height patch_height) (n_patches_width patch_width) -> '
'batch_size (n_patches_height n_patches_width) (n_channels patch_height patch_width)'
)
patches = einops.rearrange(
tensor=input,
pattern=pattern,
patch_height=patch_height,
patch_width=patch_width,
)
maskes_patches_original = patches[bitmask]
# The loss is the L1 difference between
# the predicted pixel values and the ground truth,
# divided by the number of masked patches
loss = l1_loss(
input=masked_patches_reconstructed,
target=maskes_patches_original,
)/n_masked_tokens
把上面的代码封装成类并增加一些辅助函数,这里就不贴了有兴趣的看下最后的源代码。然后使用的时候如下:
from timm import (
create_model,
)
from torch.nn.functional import (
l1_loss,
)
from torch.optim import (
AdamW,
)
vit = create_model(
'vit_small_patch32_224',
num_classes=0,
)
simmim = SimMIM(
vit=vit,
masking_ratio=0.5,
)
optimizer = AdamW(
params=simmim.parameters(),
lr=1e-4,
weight_decay=5e-2,
)
for epoch in range(n_epochs):
for input in dataloader:
n_masked_tokens, masked_patches_reconstructed, masked_patches_original = simmim(input)
loss = l1_loss(
input=masked_patches_reconstructed,
target=maskes_patches_original,
)
loss /= n_masked_tokens
loss.backward()
optimizer.backward()
optimizer.zero_grad()总结
引用:
A Simple Framework for Contrastive Learning of Visual Representations
https://arxiv.org/abs/2002.05709
Exploring Simple Siamese Representation Learning
https://arxiv.org/abs/2011.10566
SimMIM: A Simple Framework for Masked Image Modeling
https://arxiv.org/abs/2111.09886
本文代码:
https://github.com/BobMcDear/PyTorch-SimMIM
编辑:王菁
校对:林亦霖
评论