
网络爬虫法即将出台!!!小爬怡情,大爬over
作者:王小敏 联席合伙人,聂昊 律师助理
前言
2018年10月20日,一篇《独家|估值175亿的旅游独角兽,是一座僵尸和水军构成的鬼城?》的文章一出世便走红网络。文中称百亿体量的马蜂窝,其中2100万条“真实点评”中有1800万条是通过机器人从大众点评和携程等竞争对手抄袭而来。通过语义分析、数据挖掘,发现了7454个抄袭账号,平均每个账号抄袭搬运了数千条点评,合计抄袭572万条餐饮点评和1221万条酒店点评,占官网声称点评数85%。
马蜂窝回应称,点评内容在马蜂窝整体数据量中仅占比2.91%,涉嫌虚假点评的账号数量更是微乎其微,并已经进行清理。但恐怕已无法洗脱自己存在爬虫行为的嫌疑。
在2019年5月28日国家互联网信息办公室发布的《数据安全管理办法(征求意见稿)》第十六条中首次出现了对网络爬虫规制的法律条文。
恶意爬虫是什么?
在回答这个问题之前,首先应当明确网络爬虫是什么?
网络爬虫就如同一只小蚂蚁,它的作用是搜集网页上的信息或数据,然后把搜集到的信息或数据搬运到小窝(数据库)里。所以爬虫不生产数据,它只是搬运数据。
而网络爬虫又分为善意爬虫和恶意爬虫,搜索引擎的爬虫就属于善意爬虫,比如百度搜索引擎的爬虫叫做百度蜘蛛(Baiduspider)。善意爬虫严格遵守Robots协议规范爬取网页数据(如URL),它的存在能够增加网站的曝光度,给网站带来流量。
与之相对的是恶意爬虫,它无视Robots协议,对网站中某些深层次的、不愿意公开的数据肆意爬取,其中不乏个人隐私或者商业秘密等重要信息。并且恶意爬虫的使用方希望从网站多次、大量的获取信息,所以其通常会向目标网站投放大量的爬虫。如果大量的爬虫在同一时间对网站进行访问,很容易导致网站服务器过载或崩溃,造成网站经营者的损失。
恶意爬虫的现状
据统计,我国2017年互联网流量有42.2%是由网络机器人创造的,其中恶意机器(主要为恶意爬虫)流量占到了21.80%。
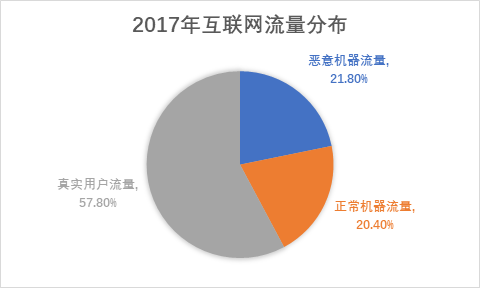
(数据来源:腾讯安全云鼎实验室)
在出行领域,恶意爬虫的主要目标是12306网站。我们日常使用的很多抢票软件上的票务信息就是由恶意爬虫不断的爬取12306网站的信息而来的。它们对12306网站的票务信息进行暴力爬取,不断的对网站提出刷新请求,于是12306网站时常因负载过大而崩溃,对我们的网络购票造成了严重的影响。
在社交领域,恶意爬虫的主要目标是在各类点评App及网站,前文所述的“马蜂窝抄袭点评”就是恶意爬虫应用在点评方面最好的例证。
而在电商领域,我们熟知的价格比对平台就是通过爬虫爬取诸如淘宝、京东等大型电商的商品价格数据,之后将数据整合,放在比对网站上供用户对比。
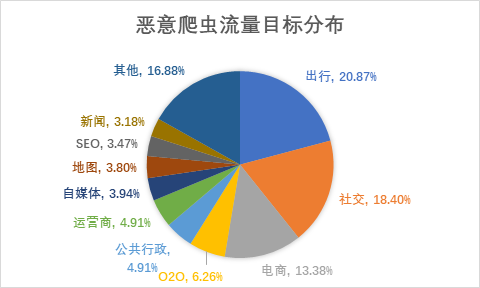
(数据来源:腾讯安全云鼎实验室)
恶意爬虫带来的法律问题
1.侵犯著作权
恶意爬虫会爬取某些网站(尤其是小说网站)上的文章、图片等信息,并将爬取到的文章或图片发布在自己的网站上以此获利,此种方式可能侵犯著作权中的信息网络传播权。例如我们在各类盗版网站中搜索到的小说或文章,就是盗版网站的运营方通过恶意爬虫从版权方网站所爬取的内容。
除开公司使用的爬虫之外,还有很多个人使用的爬虫,例如毕业年级的大学生为了搜集论文所需的各类数据,但是依靠人工搜集的方法费时费力,此时他们可能会使用爬虫帮助他们进行搜集。相对于公司的爬虫来说,个人对于爬虫的使用更为随意,他们中的大多数都不会遵守网站的Robots协议,而是根据自己的需求进行暴力爬取,这同样会引起著作权侵权问题。
2.侵犯商业秘密
如果恶意爬虫在爬取信息的过程中,无视网站经营者设置的Robots协议及各类保护措施,接触、保存甚至披露了一般用户无法访问的信息,而该信息又构成商业秘密,则恶意爬虫的行为存在侵犯他人商业秘密的可能。
3.侵犯个人隐私或个人信息
同样如果网络爬虫突破了网站经营者设置的保护措施,不仅可能接触到商业秘密,还可能接触到存储于后台服务器中的用户个人隐私或个人信息。
例如2017年3月24日,58同城简历数据泄露事件。某些淘宝电商在淘宝按照0.2到0.3元一条的价格售卖“58同城简历数据”,并且700元可以购买一套采集58数据的软件。而这些被泄露资料的求职者均在58同城上投递了简历。多家安全机构表示,该采集软件是一个恶意爬虫工具,爬虫软件可利用漏洞爬取个人信息。
如果网站或软件对我们的个人信息没有采取专门的安全保护措施或者采取的安全保护措施不够,那么我们的个人信息将容易被恶意爬虫所爬取并利用。
4.构成不正当竞争
恶意爬虫对网站数据的爬取很可能会触犯《反不正当竞争法》第二条、第十二条等条文的规定,构成不正当竞争。例如在2016年12月30日,北京知识产权法院作出的判决中((2016)京73民终588号),非法抓取使用“新浪微博”用户信息的“脉脉”被判赔200万元。
而在2016年5月26日上海知识产权法院宣判的“大众点评诉百度案”((2016)沪73民终242号)中,法官认为“百度”通过技术手段,从“大众点评”获取点评信息,并大量、全文使用用于充实自己的经营内容。此种使用方式,实质上是替代其他经营者向用户提供信息,其使用行为具有明显的“搭便车”、“不劳而获”的特点,给“大众点评”造成损害。故“百度”的上述行为,具有不正当性,构成不正当竞争。
5.侵入计算机系统,构成刑事犯罪
如果恶意爬虫强行突破某些特定被爬方的技术措施,则可能构成刑事犯罪行为。
《刑法》第二百八十五条规定,违反规定侵入国家事务、国防建设、尖端科学技术领域的计算机信息系统的,不论情节严重与否,构成非法侵入计算机信息系统罪。违反国家规定,侵入前款规定以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,或者对该计算机信息系统实施非法控制,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。提供专门用于侵入、非法控制计算机信息系统的程序、工具,或者明知他人实施侵入、非法控制计算机信息系统的违法犯罪行为而为其提供程序、工具,情节严重的,依照前款的规定处罚。
《刑法》第二百八十六条还规定,违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,构成犯罪,处五年以下有期徒刑或者拘役;后果特别严重的,处五年以上有期徒刑。而违反国家规定,对计算机信息系统中存储、处理或者传输的数据和应用程序进行删除、修改、增加的操作,后果严重的,也构成犯罪,依照前款的规定处罚。
《刑法》第二百五十三条之一规定,违反国家有关规定,向他人出售或者提供公民个人信息,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。违反国家有关规定,将在履行职责或者提供服务过程中获得的公民个人信息,出售或者提供给他人的,依照前款的规定从重处罚。窃取或者以其他方法非法获取公民个人信息的,依照第一款的规定处罚。单位犯前三款罪的,对单位判处罚金,并对其直接负责的主管人员和其他直接责任人员,依照各该款的规定处罚,即构成“侵犯公民个人信息罪”。
本文观点
我国目前对于网络爬虫的规制集中在《刑法》有关计算机信息系统犯罪的法律条文之中,对于《刑法》之外的网络爬虫行政规制或民事侵权救济,我国并未作出针对性的规定。大部分时候对于恶意爬虫侵权问题,法院适用的是《反不正当竞争法》来对被侵权人进行救济。但是《反不正当竞争法》属于事后追责的法律,对于网络爬虫问题更应该在事前予以规制。而我国目前对于网络爬虫规制的现状是等到网络爬虫造成了损失,再想办法去弥补。但是很多损害是没有办法弥补的,比如个人隐私或商业秘密的泄露,所以总是寄希望于《反不正当竞争法》能够帮助我们挽回损失是不现实的。
所以,笔者认为我国应当制定针对网络爬虫的相关标准,将Robots协议中的要求吸纳进标准之中,完善相关的数据安全法律法规,将网络爬虫引向合法轨道。明确网络爬虫应当按照何种规则行动,何种行为可为,何种行为不可为,从而抑制目前我国网络爬虫野蛮生长的态势。
最后,想提醒大家:爬虫有风险,下手需谨慎!不要直接商用抓取的数据(供学习技术即可),不要涉及用户隐私数据。总之,记住一个原则,小爬怡情,大爬over,一定要把握住度。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
- EOF -
回复关键字“简明python ”,立即获取入门必备书籍《简明python教程》电子版
回复关键字“爬虫”,立即获取爬虫学习资料
推荐阅读: