
Python网络爬虫,爬取某非法网贷系统
今天从群里看到一个朋友的任务
本着学习的心开始研究
上任务

给的文件 
打开这个web.exe文件 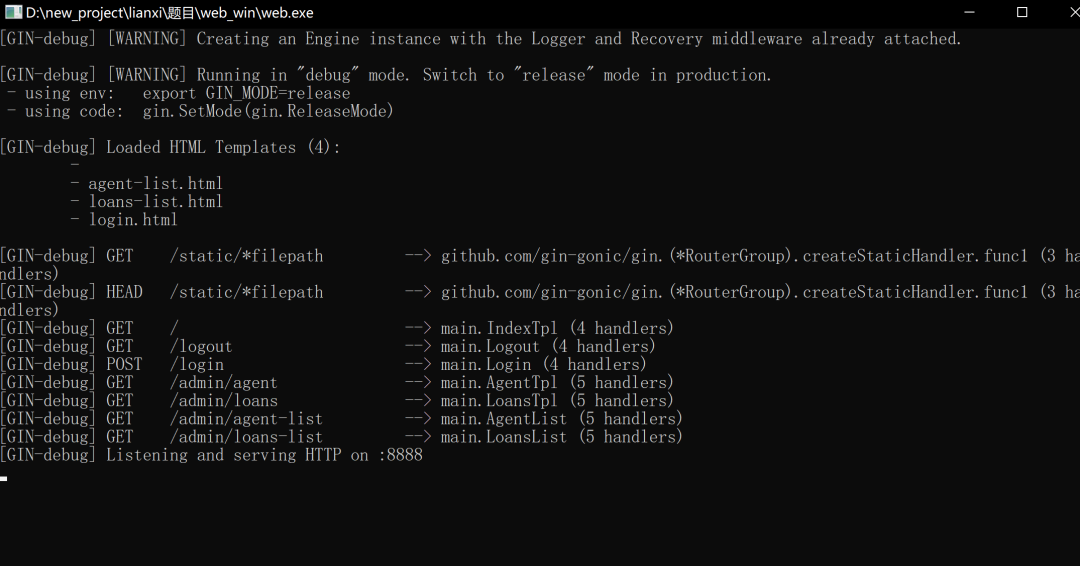
只有这样才能打开目标网页,这个好像一个爬虫作业,不是直接联网的那种网站 最后爬取的url是:http://127.0.0.1/8888 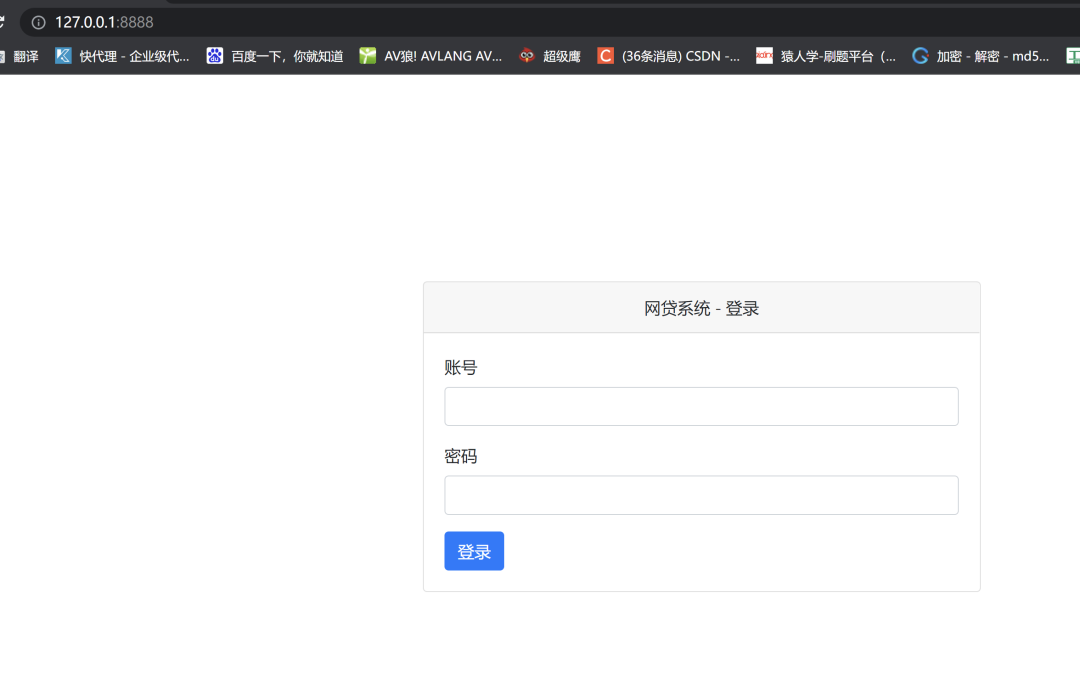
我也不懂是什么原理,继续 打开网页直接就是登录,打开F12登录一次试试,看看密码有没有加密 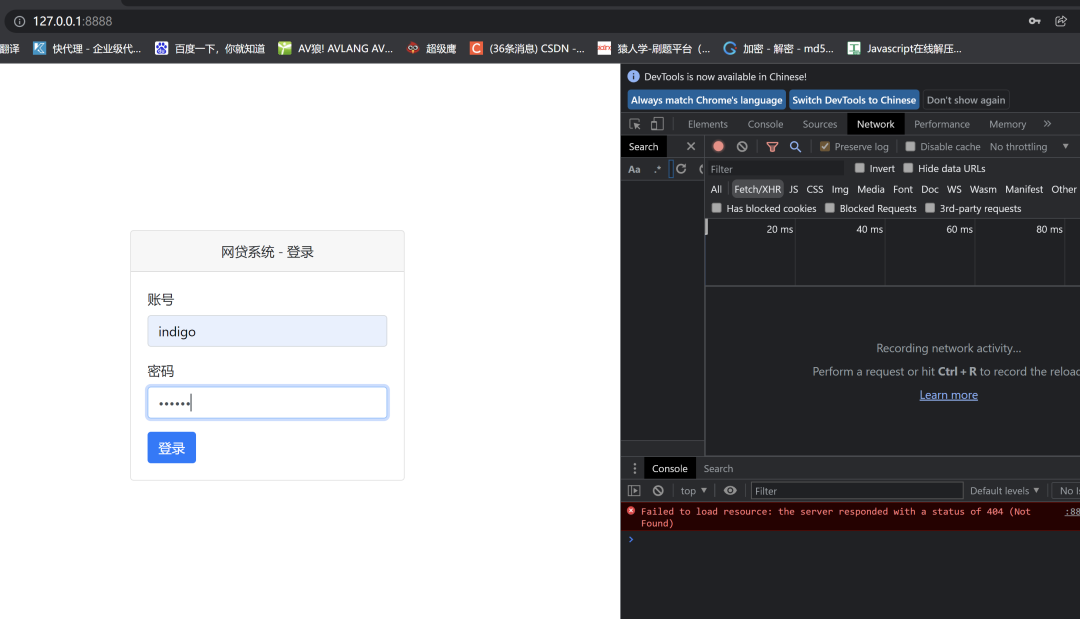
密码随便写的,只为了抓个包 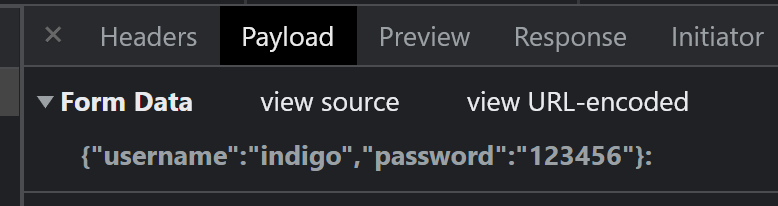
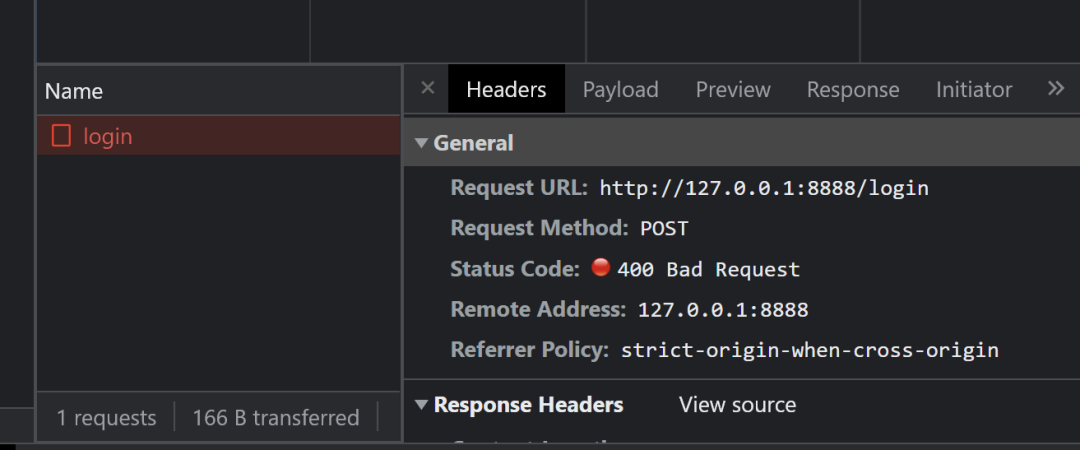
明文的密码,他还给了个密码本需要自己尝试密码是什么 
用上面抓到的包发送请求,找到真的账号密码
import requests
url = 'http://127.0.0.1:8888/login'
#抓包得到的url
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.9 Safari/537.36'
}
#自己ua,最简单的设置
with open('账号密码弱口令字典.txt','r',encoding='utf-8')as f:
#读取密码本
for line in f:
a = line.strip('\n').split(' ')
#去除每行最后的换行符,账号密码中间和有一个空格,用空格切割得到一个列表
#列表里两个元素,就是账号和密码
username = a[0]
password = a[1]
params = {"username": username, "password": password}
#设置参数
r = requests.post(url=url, headers=headers, json=params).json()
#发送请求
print(username,password,r)
#打印账号密码和返回内容
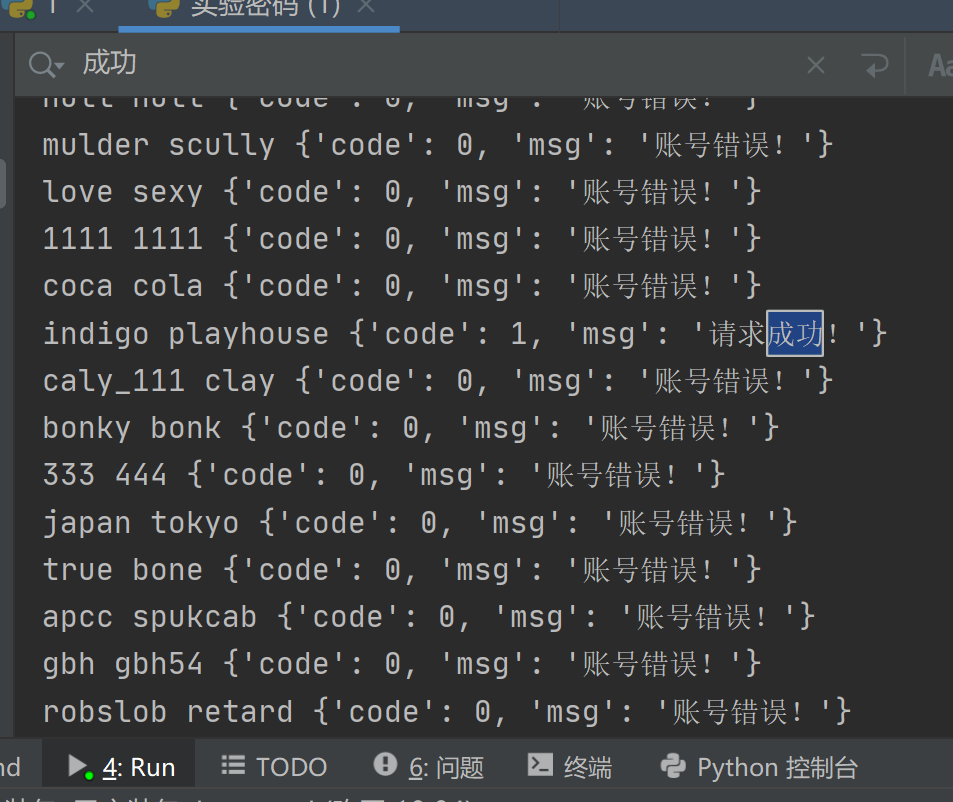
得到的结果显示indigo是账号,playhouse是密码,登录进去 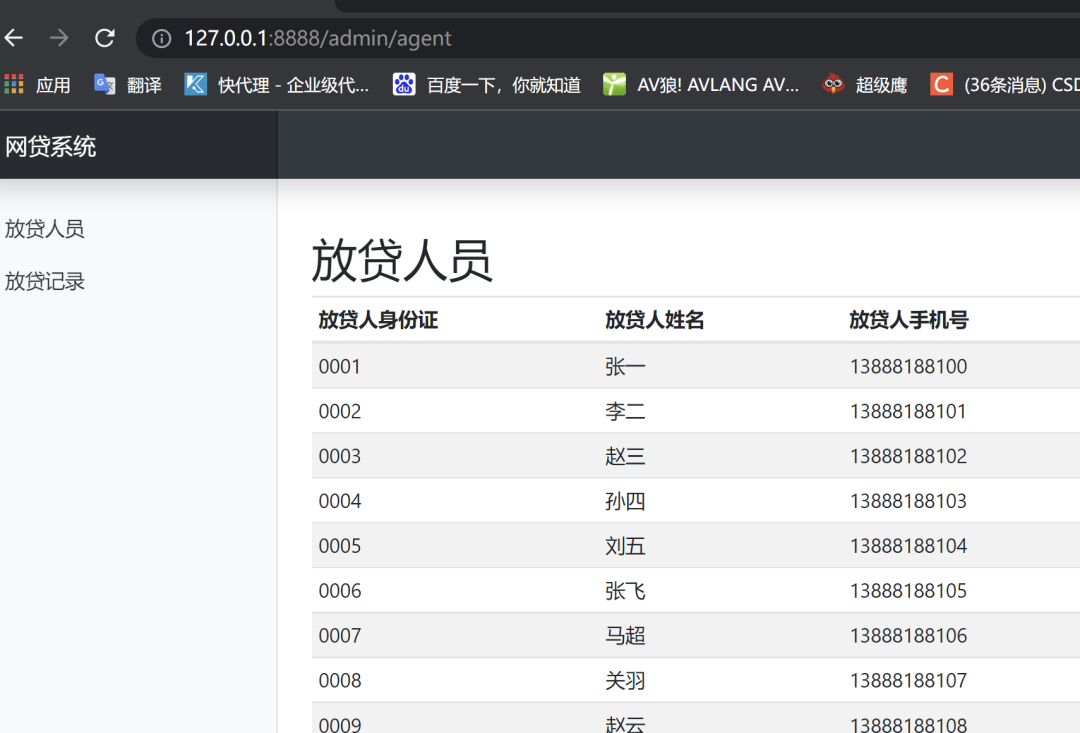
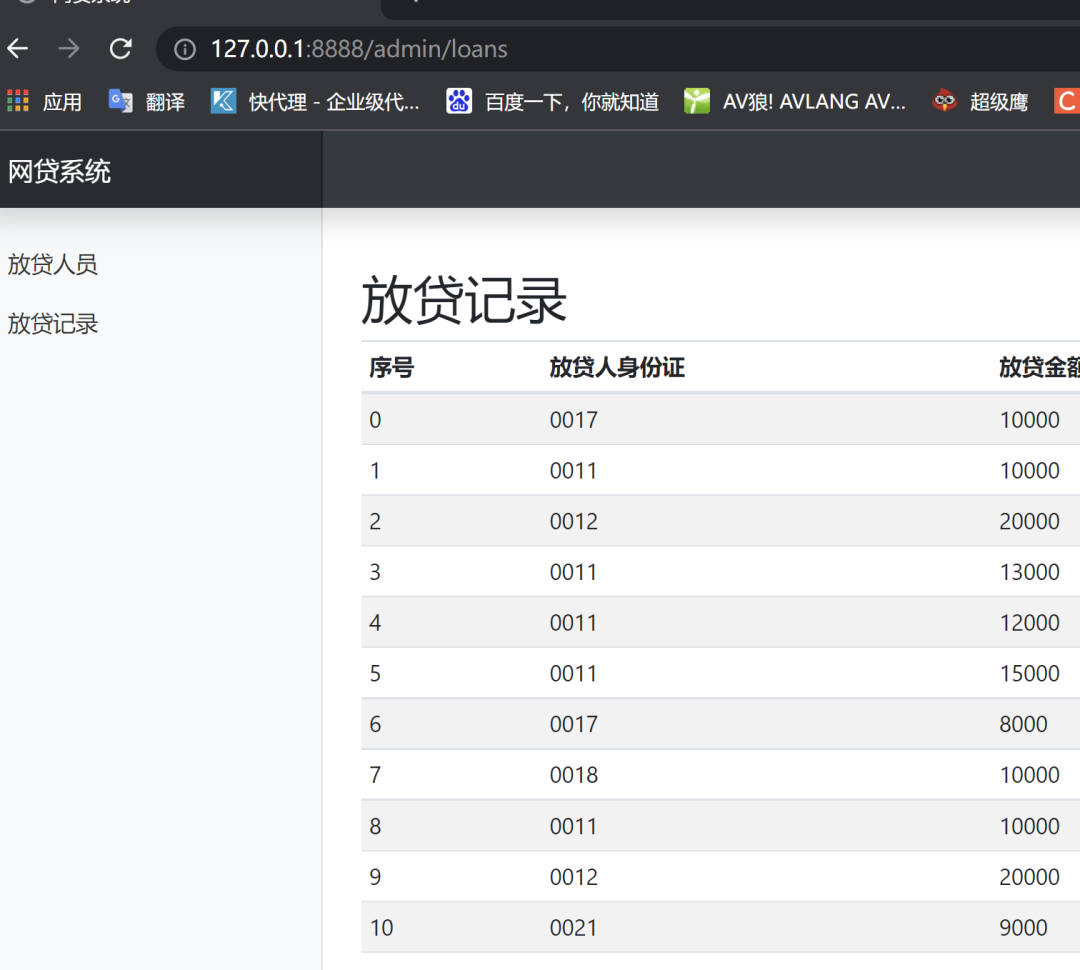
里面两个列表就是要爬取的内容,发现url后面带了个后缀 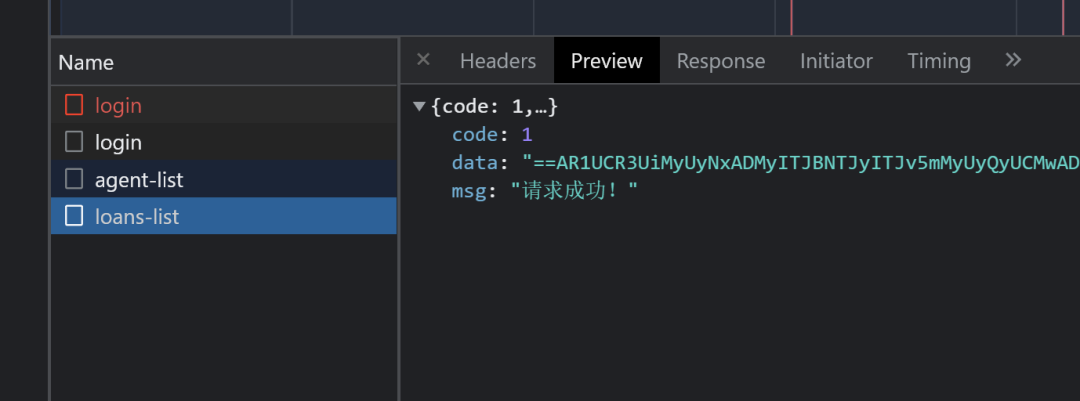
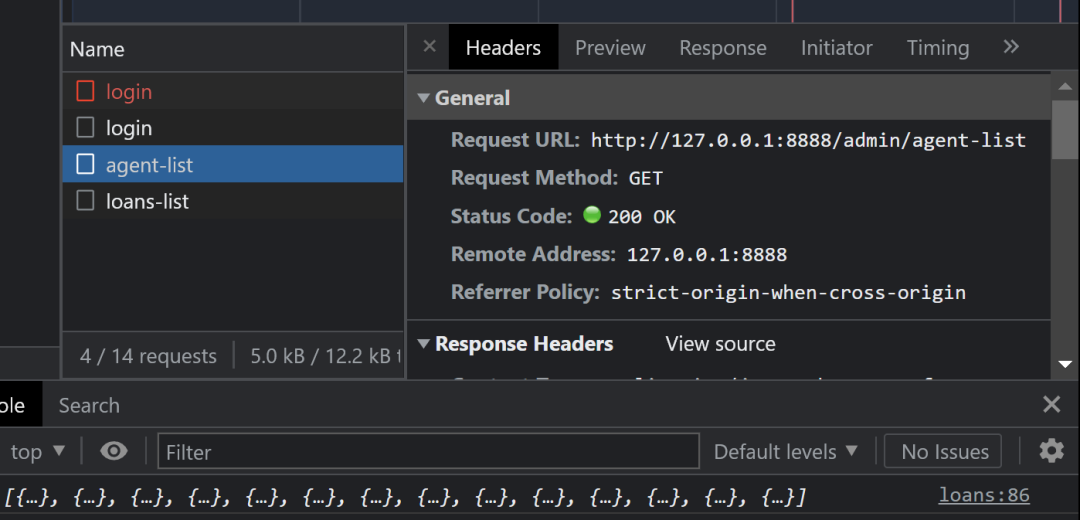
跟抓到的包正好对上了,开始写代码
import requests
#导入包
url = 'http://127.0.0.1:8888/login'
#登录的url,为了保存cookies
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.9 Safari/537.36'
}
#ua设置
params={"username":"indigo","password":"playhouse"}
#账号密码参数
session = requests.session()
#requests里的一个函数吧 不知道叫什么
#可以保存cookies,方便后面访问
r = session.post(url=url,headers=headers,json=params).json()
#获取cookies
agent_url = 'http://127.0.0.1:8888/admin/agent-list'
#放贷人员的url
res = session.get(url=agent_url,headers=headers)
datas = res.json()['data']
print(datas)
返回的结果如下图 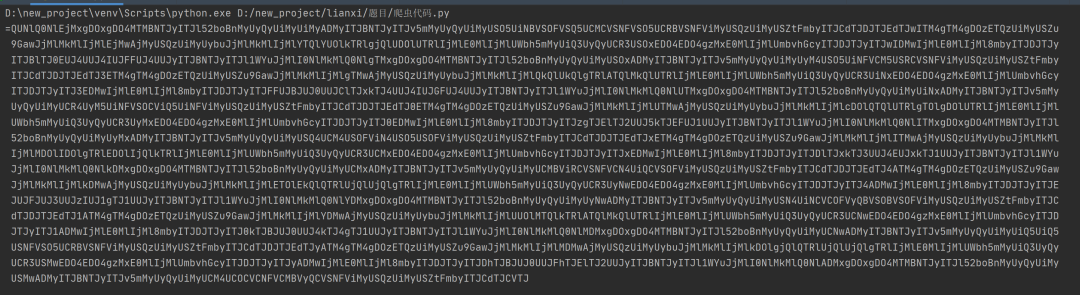
前不久刚看了一个js逆向的文章,乱七八糟带=,是base64加密 但是等号是在结尾,这个等号在开头 大胆猜测这个是base64加密并且把顺序颠倒了一下
data =datas[::-1]
# 重新排序,输出结果就是a = '1234'
# b = a[::-1]
# print(b)
# 输出'4321'
得到了等号在屁股的乱七八糟的东西,继续用base64解密
import base64
a=base64.b64decode(data.encode('utf-8'))
好像真的蒙对了,返回了有点接近的内容 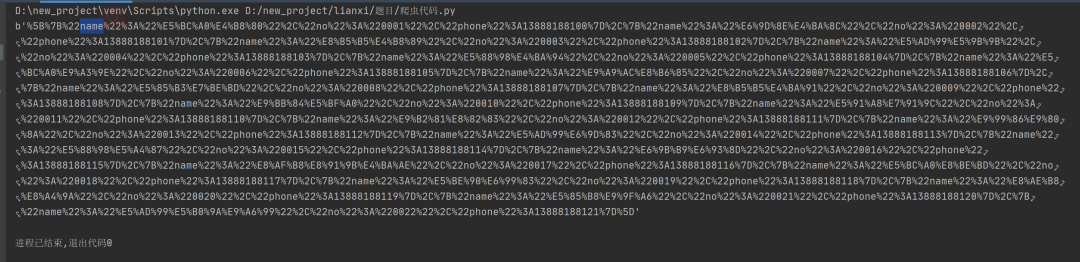
看第一行我选中的地方有个name,后面不远有个phone,大概在中间位置 而且好像还有电话号码似的数字 感觉要胜利了,可是发现其他那些%22啊什么的不认识,问了问群里大佬 说是url编码,找了半天解码方式,倒是也简单
from urllib.parse import unquote
b = unquote(a.decode())
这一步结束后打印了一下结果,让人开心 
这样后面就是转一下json,然后再从里面取值了,最后写入csv 后面的步骤过于基础,这里不细说了 这样就获得了贷款人员的内容 放款记录跟着个是一样的 个人感觉大部分一个网站的同一种内容不会写两种方法 下面是完整代码
import requests
import base64
from urllib.parse import unquote
import csv
import json
url = 'http://127.0.0.1:8888/login'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.9 Safari/537.36'
}
params={"username":"indigo","password":"playhouse"}
session = requests.session()
r = session.post(url=url,headers=headers,json=params).json()
#获取cookies
agent_url = 'http://127.0.0.1:8888/admin/agent-list'
#放贷人员的url
loans_url = 'http://127.0.0.1:8888/admin/loans-list'
#放贷记录的url
res = session.get(url=agent_url,headers=headers)
datas = res.json()['data']
#请求回的内容是一串倒叙的base64加密
data =datas[::-1]
# 重新排序
a=base64.b64decode(data.encode('utf-8'))
#解密
b = unquote(a.decode())
#解密后得到的内容是16进制的再次转换
c = json.loads(b)
# 转成json格式
head = ('name','no','phone')
# 设置csv文件头
with open('放贷人员.csv','a',encoding='utf-8',newline='')as f:
writer = csv.DictWriter(f,fieldnames=head)
writer.writeheader()
for i in c:
writer.writerow(i)
res = session.get(url=loans_url,headers=headers)
datas = res.json()['data']
data =datas[::-1]
a=base64.b64decode(data.encode('utf-8'))
b = unquote(a.decode())
c = json.loads(b)
head = ('money','no')
with open('放贷记录.csv','a',encoding='utf-8',newline='')as f:
writer = csv.DictWriter(f,fieldnames=head)
writer.writeheader()
for i in c:
writer.writerow(i)
最后,推荐蚂蚁老师的Python零基础到爬虫到数据分析实战课
评论