
【机器学习】推荐一个开源机器学习可解释仓库-AutoX-Interpreter
机器学习在金融、零售、工业预测性维护等众多场景已得到较为普遍的应用。然而,在具体业务场景中,机器学习仍然常被视为一个“黑盒”,如果不对模型进行合理的解释,业务人员就无法完全信任和理解模型的决策,使得模型的使用受到限制。
可解释机器学习的目的就在于让用户理解并信任我们的模型。在建模阶段,可解释能力可以辅助开发人员理解模型,进行模型的对比选择、优化和调整。在模型上线运行后,可解释能力可以用于向业务人员解释模型的内部机制,对模型的预测结果进行解释。
第四范式开源了一个自动机器学习的代码库AutoX,其中AutoX-Interpreter内置了丰富的机器学习可解释算法以及对应的使用案例。
主要功能包括:
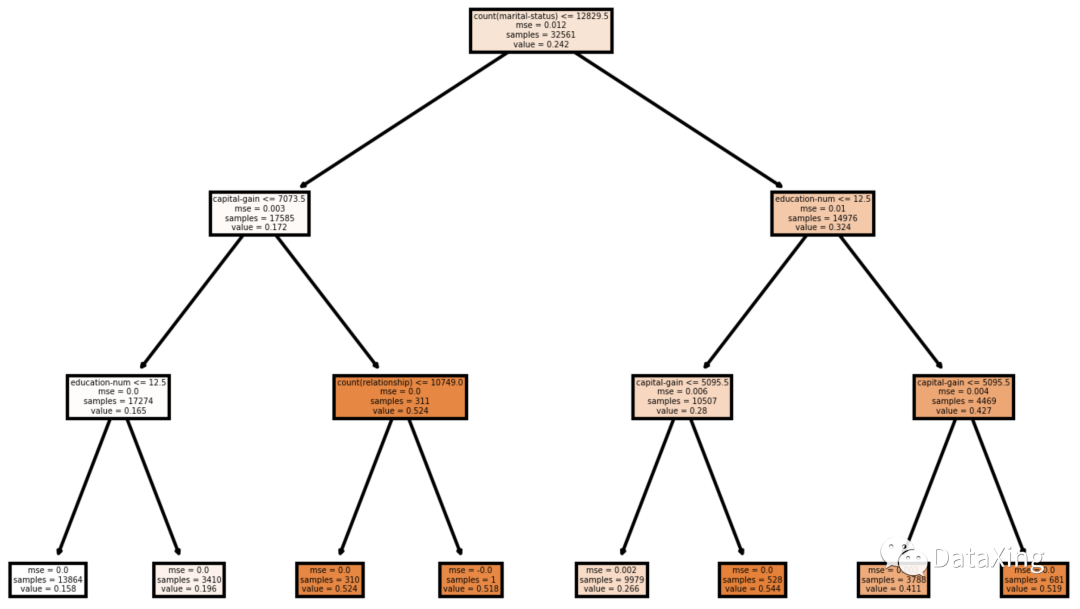
全局代理模型
用一个相对容易解释的模型拟合原模型,用拟合出来的模型来解释原模型的全貌。
- 树模型
局部代理模型
解释在局部样本点上,模型是基于哪些特征做出的预测结果。
LIME,Local interpretable model-agnostic explanations,一种与模型无关的可解释方法。
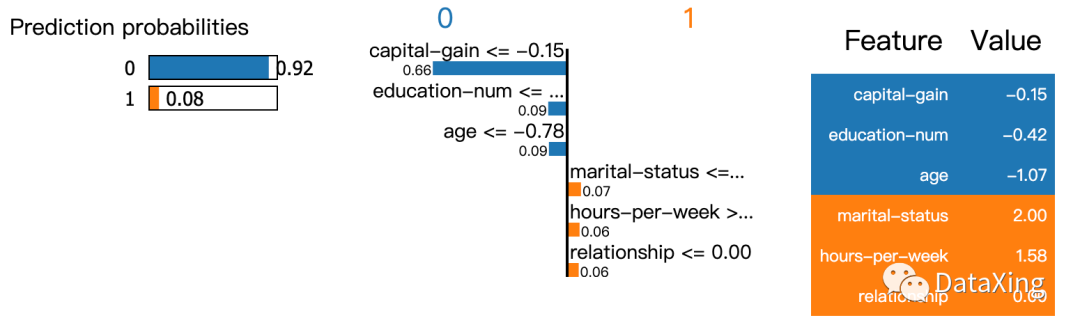
SHAP,Shapley Additive Explanation,核心是计算其中每个特征变量对模型预测值的边际贡献。

影响力样本
找出在模型训练过程中对训练结果有影响力的样本。核心在于如果删除某些样本进行训练,模型参数或预测结果变化较大。
- nn
基于ICML'17,Understanding black-box predictions via influence functions的方法。
- nn_sgd
基于NeurIPS'19,Data Cleansing for Models Trained with SGD的方法。
代表性样本和非代表性样本
- MMD-critic
找到全体样本中有代表性的样本。
- ProtoDash algorithm
给定局部样本点和模型,在预测结果一致(或相近)的样本中,找到模型决策因素一致(或相近)的样本点。
项目地址
https://github.com/4paradigm/AutoX/tree/master/autox/interpreter