
训练速度远超3D CNN,提速3倍!Facebook首发「时空版」Transformer

新智元报道
【新智元导读】Facebook AI推出了全新的视频理解架构TimeSformer,这也是第一个完全基于Transformer的视频架构。视频剪辑上限可达几分钟,远远超过当下最好的3D CNN,且成本更低。

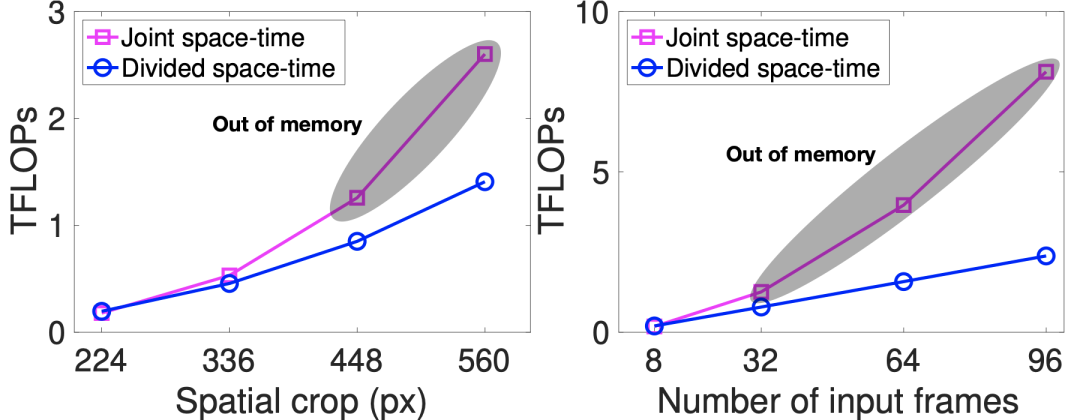
分时空注意力

例如,看一段演示如何制作法式吐司的视频。人工智能模型一次分析几秒钟可能会识别一些原子动作(例如,打鸡蛋或者把牛奶倒进碗里)。但是对每个个体行为进行分类并不足以对复杂的活动进行分类(许多食谱都涉及到打蛋)。TimeSformer 可以在更长的时间范围内分析视频,揭示原子动作之间的清晰的依赖关系(例如,将牛奶和打碎的鸡蛋混合)。

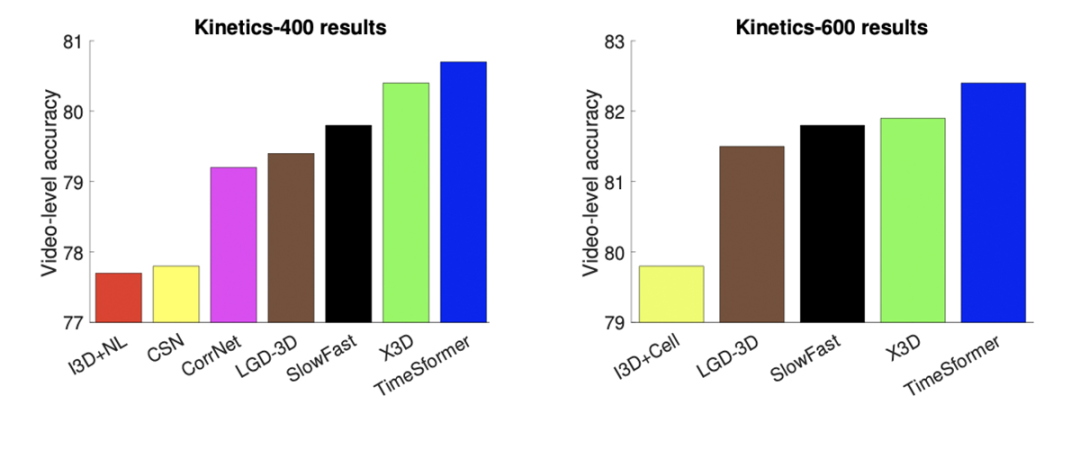
TimeSformer视频剪辑上限可达几分钟

评论