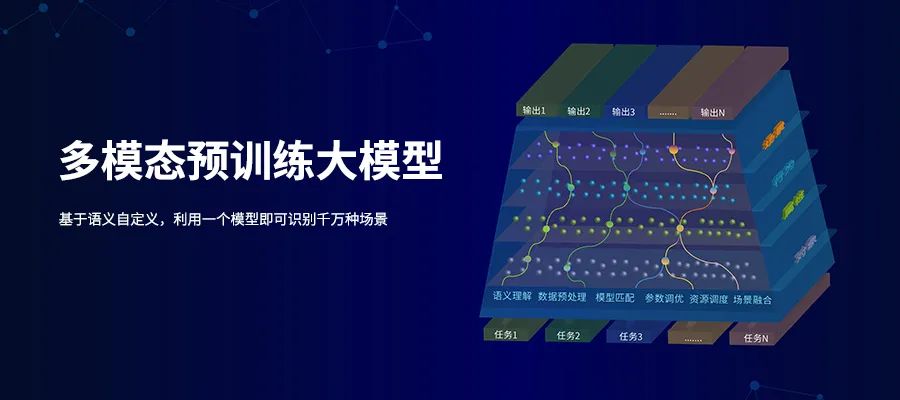
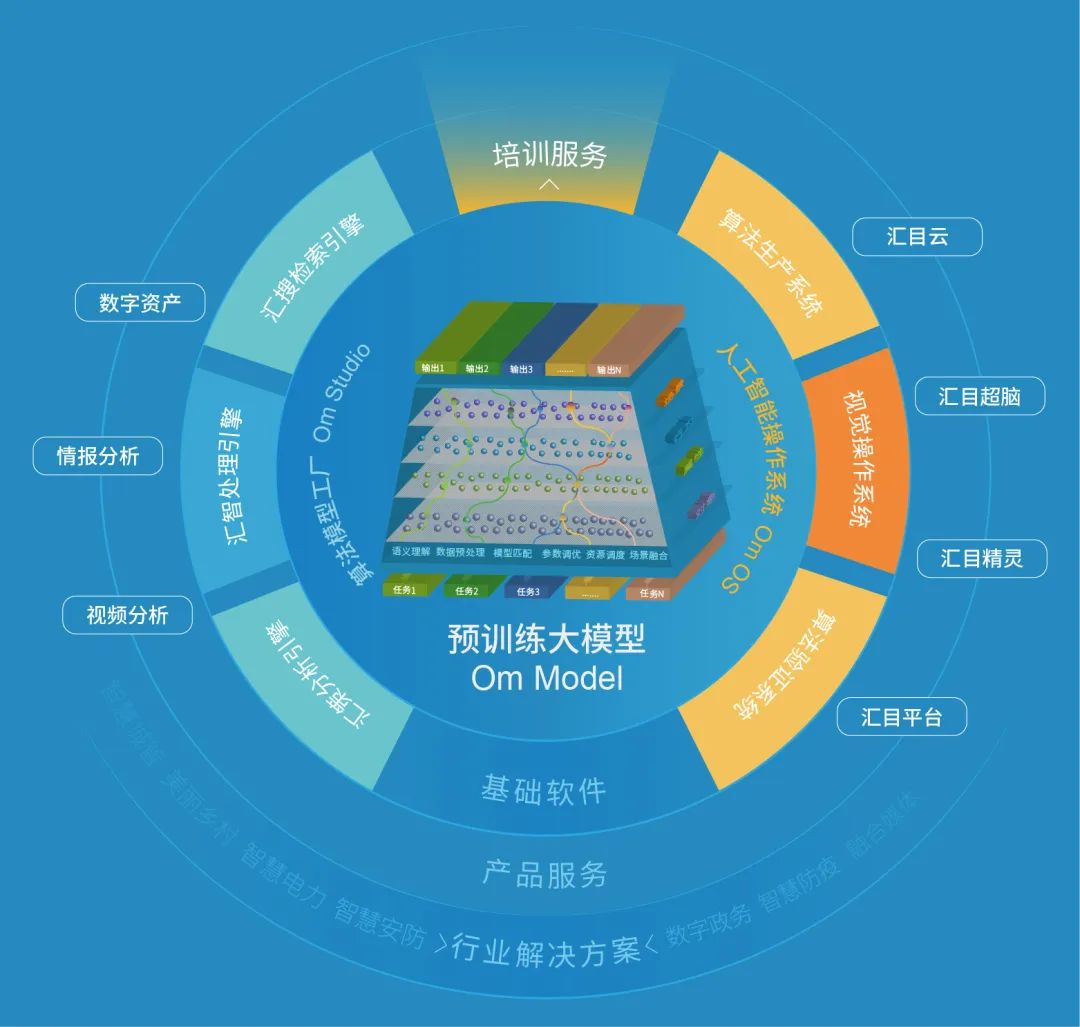
”2021年是大规模预训练模型的爆发之年,掀起了人工智能又一波热潮,并迅速成为AI领域的技术新高地,助推人工智能从1.0的感知智能向2.0的认知智能转变。 自从2012年深度学习的应用元年以来,人脸识别、语音识别等技术通过机器学习实现了大量应用场景突破,不仅提升了社会工作效率,同时改变了人们的生活出行模式,建立了人类对人工智能技术的基础认知。但是经过多年的应用实践,传统人工智能基于特定场景、特定内容、特定需求的适配模式也暴露出很多短板,尤其在泛场景应用、小样本及复杂场景上,只能达到“有多少人工,就有多少智能”的基础感知,识别准确度差,泛化能力低。要实现人工智能的真正落地,必须让机器具备通识知识的自学习能力,以及对业务的逻辑判断能力,建立机器综合认知体系。工欲善其事必先利其器,预训练技术让深度神经网络模型可以对大规模无标注数据进行自监督学习,使超大规模模型的建立成为可能。自从2018年Google推出BERT以来,Open AI、Google、Facebook、Microsoft、英伟达、智源研究院、阿里达摩院、华为、百度等研发机构和企业纷纷进行大规模预训练模型布局,掀起了一轮拼参数、拼算力的AI军备竞赛。虽然这轮竞赛参数规模呈指数级增长,但技术应用各有侧重。于是2021年8月,基于各类大模型的特性和未来发展前景,斯坦福大学的Percy Liang、李飞飞等100多位学者联名发表了一份 200 多页的重磅研究综述《On the Opportunities and Risk of Foundation Models》,将大规模预训练模型统一命名为基础模型(Foundation Models),并从基础模型的能力、应用领域、技术层面和社会影响等四个方面阐述了基础模型面临的机遇和挑战,奠定了大规模预训练模型的理论基础,也正式标志着人工智能2.0序幕的正式拉开。在新一轮大规模预训练模型的商业化热潮中,近期,由深投控领投,融创投资等共同参与的联汇科技D轮融资,使这家从事大规模预训练模型研发的新型AI公司浮出水面。不同于大量的AI新创企业,联汇科技拥有十多年的行业积累,以及对音视图文处理分析技术的丰富应用经验,正如一只等风来的候鸟,积极打造针对视觉语言的多模态预训练大模型,努力改变视觉分析和多模态分析领域的人工智能技术实现方式。




 下载APP
下载APP