
推荐 | 深度学习反卷积最易懂理解
重磅干货,第一时间送达

本文转载自:OpenCV学堂
引言 ·
普通图像反卷积,跟深度学习中的反卷积是一回事吗?别傻傻分不清!其实它们根本不是一个概念
图像反卷积
最早支持反卷积是因为图像去噪跟去模糊,知道图像去模糊时候会使用反卷积技术,那个是真正的反卷积计算,会估算核,会有很复杂的数学推导,主要用在图像的预处理与数字信号处理中。本质上反卷积是一种图像复原技术,典型的图像模糊可以看成事图像卷积操作得到的结果,把模糊图像重新复原为清晰图像的过程常常被称为去模糊技术,根据模糊的类别不同可以分为运动模糊与离焦模糊,OpenCV支持对这两张模糊图像进行反卷积处理得到清晰图像。反卷积的基本原理就是把图像转换到频率域,通过估算图像的核函数,在频率域对图像点乘计算之后,重新获取图像信息,转回为空间域。主要操作都在频率域,转换通过离散傅里叶(DFT)变换与反变换,通过维纳滤波处理获取反模糊信息,OpenCV支持反卷积采用维纳滤波方式的去模糊,但是参数调整事一个大坑,基本上每张图像的参数都不一样,很难有相同的结果。最近这些年,图像反模糊逐步被深度学习的方法引领,OpenCV提供的那几个函数越来越少的人知道,主要是通用性很差。贴一张图:

OpenCV反模糊之后的效果:

深度学习中的反卷积
深度学习中典型网络就是卷积神经网络,对图像分类,对象检测都可以取得很好的效果。但是在语义分割任务中,网络模型涉及到上采样操作,最常见的就是通过填充0或者最近邻插值的方式来完成上采样。在ICCV 2015年的一篇论文中提出了可学习的反卷积网络,不再通过简单粗暴的填充0或者最近邻插值方法来完成上采样,让整个过程变成可学习,在图像语义分割网络中实现了对上采样过程的训练。论文中提到的反卷积操作实现上采样跟图像处理中反卷积实现图像去模糊有本质区别,这里的反卷积更加准确的说法应该是转置卷积。
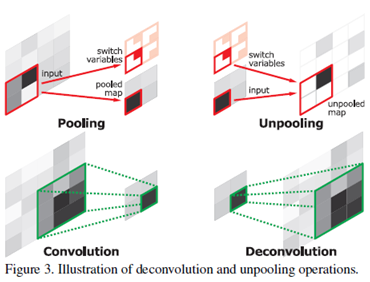
卷积操作 ·
图中第二行就是卷积与反卷积的示意图,下面通过一个简单的例子来解释上图的内容。假设有4x4大小的二维矩阵D,有3x3大小的卷积核C,图示如下:
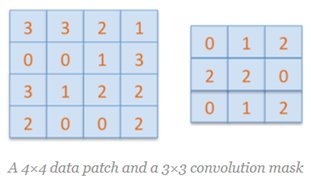
直接对上述完成卷积操作(不考虑边缘填充)输出卷积结果是2x2的矩阵

其中2x2卷积的输出结果来自D中第二行第二列像素位置对应输出,相关的卷积核与数据点乘的计算为:
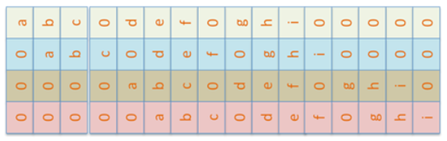
0x3+1x3+2x2+2x0+2x0+0x1+0x3+1x1+2x2=12,可以看出卷积操作是卷积核在矩阵上对应位置点乘线性组合得到的输出,对D=4x4大小的矩阵从左到右,从上到下,展开得到16个维度的向量表示如下:
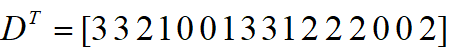
我们同样可以把3x3的卷积核表示如下:
为了获得卷积核的4x4的向量表示,我们可以对其余部分填充零,那么卷积核在D上面移动的位置与对应的一维向量表示如下:
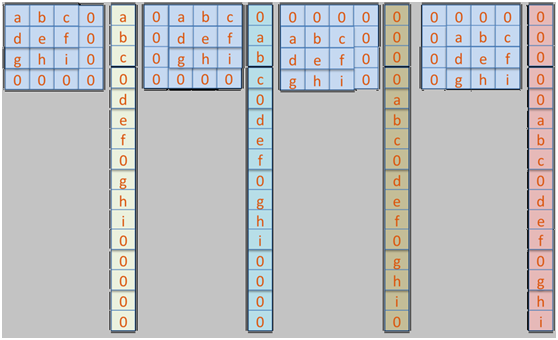
考虑到卷积核C与D的点成关系,合并在一起还可以写成如下形式:
把上面卷积核中的字符表示替换为实际卷积核C,得到:

所以上述的卷积操作可以简单的写为:
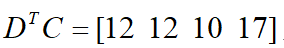
重排以后就得到上面的2x2的输出结果。
转置卷积:
现在我们有2x2的数据块,需要通过卷积操作完成上采样得到4x4的数据矩阵,怎么完成这样的操作,很容易,我们把2x2转换为1x4的向量E,然后对卷积核C转置,再相乘,表示为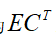 就得到16维度向量,重排以后就得到了4x4的数据块。这个就是深度学习中的卷积与反卷积最通俗易懂的解释。
就得到16维度向量,重排以后就得到了4x4的数据块。这个就是深度学习中的卷积与反卷积最通俗易懂的解释。
终极解释-一维转置卷积 ·
什么!还不明白,那我最后只能放一个大招了!我搞了个一维的转置卷积的例子:
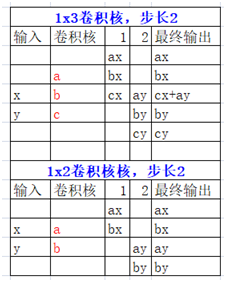
有个前提,你得先理解什么是卷积跟一维卷积,二维卷积等基本概念。这个例子就很直接,我用Excel绘制的,先看图:
解释一下,一维卷积的本来是1xN,转置变为Nx1的,然后同样用输入的数据跟卷积核点乘,点成的方式如上,如果有重叠的部分,就加在一起就好啦,这部分还可以通过代码来验证演示一波,pytorch的代码演示如下:
你好
from __future__ import print_function
import torch
import numpy as np
# 输入一维数据
d = torch.tensor([1.,2.])
# 一维卷积核
f = torch.tensor([3.0,4.0])
# 维度转换dd
d = d.view(1,1,2)
f = f.view(1,1,2)
# 一维转置卷积
ct1d = torch.nn.ConvTranspose1d(in_channels=1, out_channels=1, kernel_size=2, stride=2, bias=0)
ct1d.weight = torch.nn.Parameter(f);
# 打印输出
print("输入数据:", d)
print("输出上采样结果:", ct1d(d))运行结果如下:

根据我的手绘Excel图,可以认为:
[x, y] = [1, 2],卷积核[a, b] = [3, 4],输出结果[ax, bx, ay, by] = [3, 4, 6, 8]
这个就是转置卷积上采样!这下还不明白我真的没法啦!
参考:
https://iksinc.online/2017/05/06/deconvolution-in-deep-learning/
2015 ICCV论文《Learning Deconvolution Network for Semantic Segmentation》
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~