点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
FiftyOne是一个开源的可视化数据集分析工具,最近添加了Jupyter notebook支持,该功能是我实现的,并且是其技术主管。- FiftyOne:http://fiftyone.ai/
完成后,我着手撰写一篇文章,描述此功能的重要性——为什么自动屏幕截图非常适合与他人共享你的视觉发现,为什么将代码及其通常的视觉输出放在一个地方对于CV / ML如此重要,以及如何在notebook使用FiftyOne 可以开启notebook为CV / ML工程师和研究人员建立的更多范例。本文希望做到所有这些事情,但从本质上讲,当我了解科学notebook的历史时,它也朝着另一个方向发展。从科学研究本身开始的历史。FiftyOne希望以此为基础。CV / ML社区需要比Jupyter Notebook更多的东西来进行视觉研究和分析。
本文的最后一部分是在notebook中使用FiftyOne的分步指南,可帮助你发现可视数据集的问题。整个部分也可以通过Google的Colab找到。- Google’s Colab:https://colab.research.google.com/github/voxel51/fiftyone-examples/blob/master/examples/digging_into_coco.ipynb
我们将看到如何用很少的代码行来确认图像检测模型的常见故障模式并识别注释错误,同时在每一步的结果可视化的同时。但是在此之前,我会解释为什么CV / ML社区需要比Jupyter Notebook更多的东西来进行视觉研究和分析。科学状态
2018年4月,《大西洋》发表了一篇文章,宣布我们所知道的科学论文已经过时。实际上,这可能只是一个故意的预测,或者至少是互联网毫不客气的一种夸张说法。但是它勾勒出的科学出版历史是无可争议的。- 文章地址:https://www.theatlantic.com/science/archive/2018/04/the-scientific-paper-is-obsolete/556676/
在科学论文创建近400年之后,其协作效率已达到瓶颈。大量的科研人员在阐述该文章时取得了稳定的进步。现在已不适合时代。现在,成百上千的研究人员在一个领域发表论文,而不是几十人。结果往往不再是手工计算,而是由计算机、软件和曾经难以理解的数据集来计算。由于这种论文发表的规模,可重复性现在比以往任何时候都变得更加重要。但通常情况下,为使研究人员能够重现自己的研究成果而采取的措施是不够的。通常情况下,提供的代码和数据是不完整的,如果提供了代码和数据,并且使用丰富的动态可视化语言描述复杂思想,这种动态可视化语言是用抽象的语言和简化的静态图表来描述的。共享研究的方式与完成研究的方式不再匹配。Wolfram的围墙花园
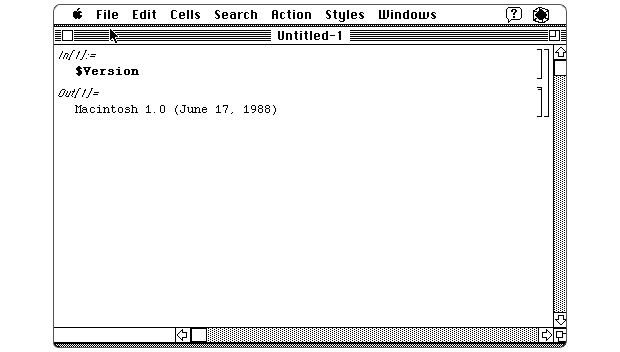
现代研究的计算复杂性和规模一直是科学进步和技术创新的福音。与科学研究论文的顽固形式(即PDF)并列在一起,几十年来,这也是一个公认的问题。不过,一个解决方案已经存在了数十年。一种以相同方式甚至相同形式完成研究并共享的解决方案。该解决方案诞生于1988年,当时由史蒂芬·沃尔夫拉姆(Steven Wolfram)创立的沃尔夫拉姆研究中心(Wolfram Research)发布了Mathematica,成为了计算的“notebook” 。该界面由西奥多·格雷(Theodore Gray)牵头,由早期的苹果代码编辑器提供了信息,并且部分由史蒂夫·乔布斯(Steve Jobs)协助制定。Wolfram Mathematica的版本1,于1988年发布。由Stephen Wolfram Blog提供。三十多年来,Mathematica一直在增加它可以为你解答的问题,可以可视化数据的数字方式以及可以使用的数据量。但是,自推出的第一个十年以来,增长一直很缓慢。许可证价格昂贵,发布商不想使用它们,而Mathematica支持的功能始于Wolfram Research。这是一个美丽而功能强大的围墙花园(Walled Garden)。Python,Jupyter
随着Mathematica继续朝着追求完美的方向前进,2001年初,物理学专业的研究生FernandoPérez发现自己对自己的研究能力已经感到厌倦,即使Mathematica任其支配也是如此。在《大西洋彼岸一书中,他迷上了新的编程语言Python,并在另外两名研究生的帮助下开始了一个名为IPython的项目,即 Jupyter 项目的基础。Jupyter并非在“技术层面”上而是在“社会层面”上胜过Mathematica。
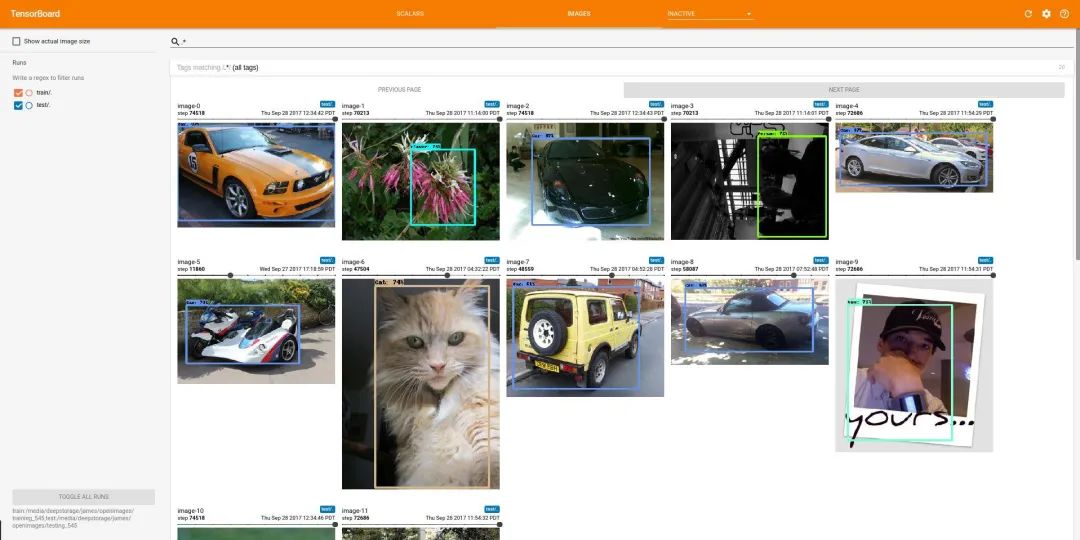
如今,Jupyter Notebook电脑的核心是Jupyter Notebook电脑。像Mathematica一样*,* Jupyter Notebook鼓励科学探索。但是与Mathematica不同*,它是任何人都可以贡献的开源项目。Jupyter并非在“技术层面”上而是在“社会层面”上胜过Mathematica*,正如诺贝尔奖获得者Paul Romer所指出的那样。Jupyter Notebooks的形式由活跃的开发人员和用户社区决定。计算机视觉领域完全属于科学研究领域。多年来,学术界和行业研究人员都在Jupyter Notebook电脑中发现了难以置信的价值。单个数据片段通常是图像和视频本身,需要对其进行查看和观看。notebook电脑提供了。可共享的可视化需要共享。notebook电脑提供了。Jupyter的开放生态系统允许开发人员轻松添加任何缺失的集成。TensorBoard可以嵌入Jupyter Notebook中,用于对象检测实验。像matplotlib和opencv这样的软件包可用于显示需要检查的图像和视频。在训练机器学习模型时,类似tensorboard的软件包会提供示例可视化,将图像检查扩展到实验跟踪的范围内。matplotlib,opencv,tensorboard,和其他无数Python包与可视化功能都可以在Jupyter Notebook电脑中使用。但是,在CV / ML中,使用Jupyter Notebook时仍然存在一个明显的问题。数据质量对于构建出色的模型至关重要。要了解数据质量,就需要对数据趋势进行明智的了解。仅仅看一个甚至十几个图像几乎总是不足以了解模型的性能和故障模式。此外,在ground truth或gold standard标签中识别可能只在1,000张甚至100,000张图像中出现的单个错误,需要对数据集进行快速切片和切割,以缩小问题范围。从根本上说,目前还缺乏能够自然地处理notebook中可视化数据集的工具来解决这类问题。FiftyOne和Jupyter
“ FiftyOne是什么?”。这是一个开放源代码的CV / ML项目,希望解决工业和学术界的CV / ML研究人员面临的许多实际问题和工具问题。这是我写这篇文章的原因,也是我认为计算notebook的历史包含宝贵经验的原因。作为FiftyOne的开发人员,我很欣赏它所鼓励的研究质量以及所允许的协作。我同意,最好在一个开放的论坛中取得最好的进展。让机器为我们做出智能和自动化决策的机会促使我们进行了大量的人工工作。
前面概述的notebook和科学出版的简要历史与当今机器学习面临的许多问题平行。具体而言,在计算机视觉领域。计算机视觉模型试图对我们这个世界上非结构化的,即图像和视频进行观察和决策。在过去的十年中,为了追求训练和理解这些模型的性能,数以千计的图像中的大型数据集已被数千名工人不完全注释。让机器为我们做出智能和自动化决策的机会促使我们进行了大量的人工工作。事实证明,最近在无需监督而又费力的人工标注工作(例如OpenAI的CLIP)的计算机视觉任务的更无监督的方法上的努力取得了丰硕的成果。但是性能仍然远远不够完美。而且,理解模型性能总是需要针对可信的、真实值或黄金标准数据进行手动验证。毕竟,这些模型并不是被送到树林里去操作和推断的。模型正被嵌入我们的日常生活中,它们的表现质量可能会产生生死攸关的后果。我们用来分析计算机视觉模型的方法和工具的质量,应该与用于构建它们的方法和工具的质量相匹配。
因此,可以肯定的是,我们用来分析计算机视觉模型的方法和工具的质量应该与用于构建模型的方法和工具的质量相匹配。而累积的,协作的和渐进的问题解决仍至关重要。建立开放标准,使CV / ML社区不仅是在模型上,而且是在数据集上,以增量方式协同工作,这可能是在现代计算机视觉科学领域建立信任和进步的唯一可行方法。FiftyOne希望能够建立这种信任和进步。以下是FiftyOne当前功能的一个小示例,重点是演示基本的API和UX,这些API和UX可以在Jupyter Notebook中高效地回答有关其数据集和模型的问题。与FiftyOne一起挖掘COCO
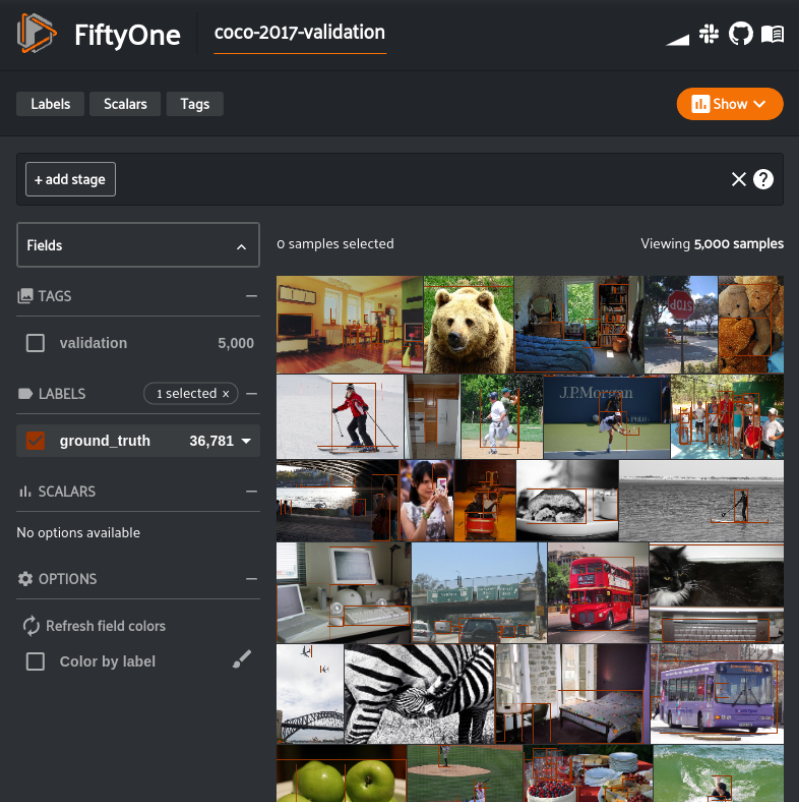
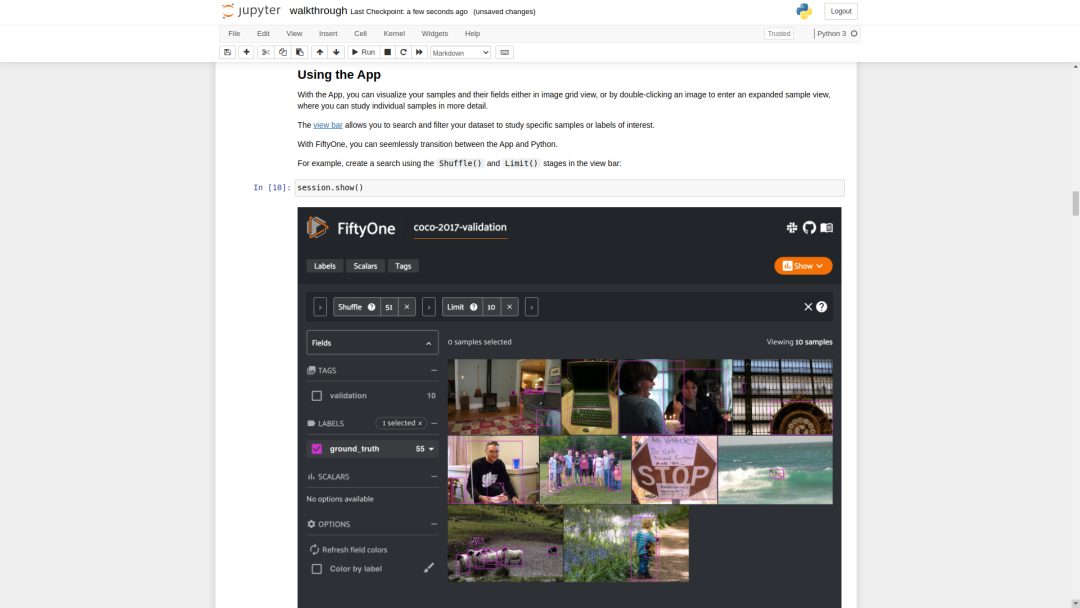
按照此Colab Notebook中的说明进行操作:https://colab.research.google.com/github/voxel51/fiftyone-examples/blob/master/examples/digging_into_coco.ipynbnotebook电脑提供了一种方便的方式来分析视觉数据集。代码和可视化可以位于同一个地方,这正是CV / ML经常需要的地方。考虑到这一点,能够在视觉数据集中发现问题是改进它们的第一步。本节将引导我们深入挖掘图像数据集中问题的每个“步骤”(即notebook单元)。我鼓励你进入Colab Notebook并亲自体验:https://colab.research.google.com/github/voxel51/fiftyone-examples/blob/master/examples/digging_into_coco.ipynb首先,我们需要使用pip安装fiftyone软件包。接下来,我们可以下载并加载我们的数据集。我们将使用COCO-2017验证拆分。我们还花点时间使用FiftyOne App可视化真实值检测标签。以下代码将为我们完成所有这些工作。import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("coco-2017", split="validation")
session = fo.launch_app(dataset)
我们已经加载了验证数据集COCO-2017,现在让我们下载并加载模型并将其应用于验证数据集。我们将使用来自FiftyOne model zoo的预训练模型faster-rcnn-resnet50-fpn-coco-torch。让我们将预测应用于新的标签字段predictions,并将应用范围限制到置信度大于或等于0.6的检测。- FiftyOne Model zoo:https://voxel51.com/docs/fiftyone/user_guide/model_zoo/index.html
model = foz.load_zoo_model("faster-rcnn-resnet50-fpn-coco-torch")
dataset.apply_model(model, label_field="predictions", confidence_thresh=0.6)
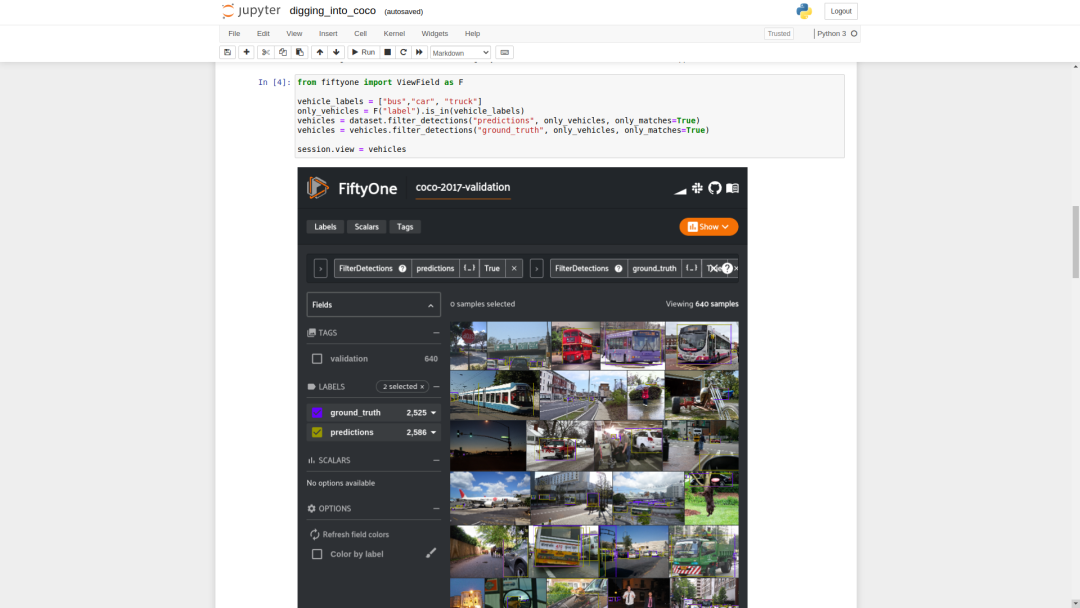
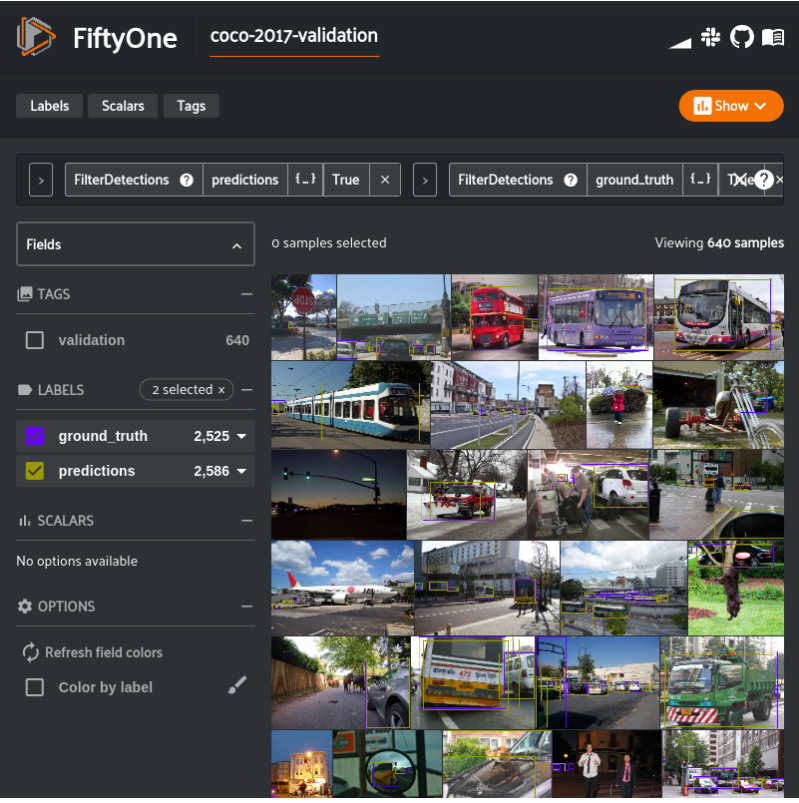
让我们专注于与车辆检测有关的问题,并在真实值标签和我们的预测中考虑所有公共汽车,小汽车和卡车车辆,并忽略任何其他检测。以下内容将我们的数据集过滤到仅包含我们的车辆检测数据的视图,并在App中呈现该视图。from fiftyone import ViewField as F
vehicle_labels = ["bus","car", "truck"]
only_vehicles = F("label").is_in(vehicle_labels)
vehicles = (
dataset
.filter_labels("predictions", only_vehicles, only_matches=True)
.filter_labels("ground_truth", only_vehicles, only_matches=True)
)
session.view = vehicles
仅使用车辆真实值情况和预测的检测结果进行的COCO-2017验证。现在我们有了预测,我们可以评估模型了。我们将使用FiftyOne提供的使用COCO评估方法的实用方法evaluate_detections()。from fiftyone.utils.eval import evaluate_detections
evaluate_detections(vehicles, "predictions", gt_field="ground_truth", iou=0.75)
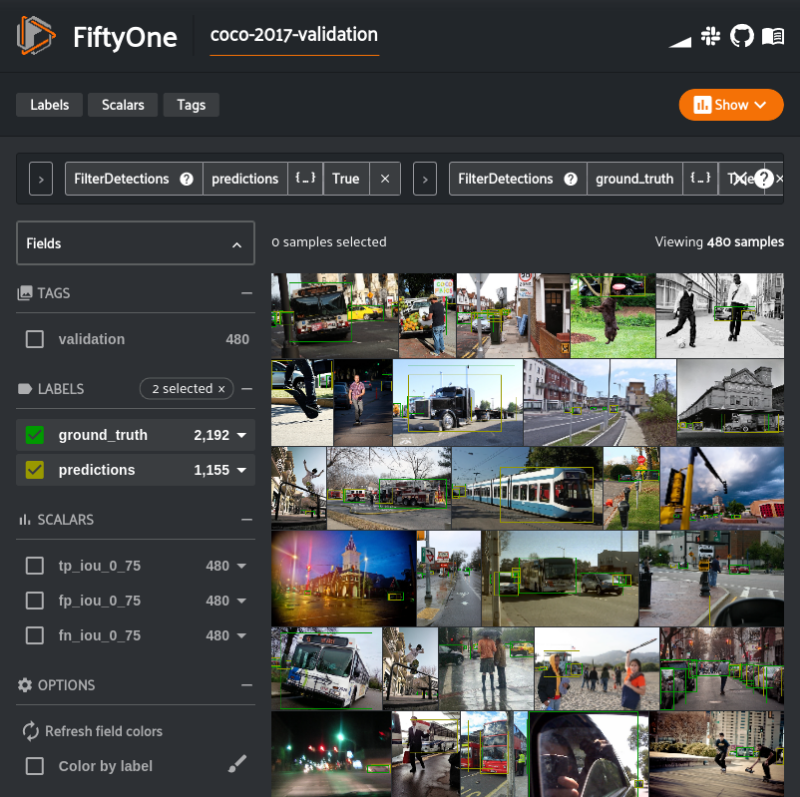
evaluate_detections()已将有关评估的各种数据填充到我们的数据集中。值得注意的是有关哪些预测与真实值框不匹配的信息。下面的数据集视图使我们仅查看那些不匹配的预测。我们也将按照置信值以降序排序。filter_vehicles = F("ground_truth_eval.matches.0_75.gt_id") == -1
unmatched_vehicles = (
vehicles
.filter_labels("predictions", filter_vehicles, only_matches=True)
.sort_by(F("predictions.detections").map(F("confidence")).max(), reverse=True)
)
session.view = unmatched_vehicles
如果你正在使用本演示中的notebook版本,则将看到做出不匹配预测的最常见原因是标签不匹配。这并不奇怪,因为所有这三个类都在超类vehicle中。卡车和汽车在人工注释和模型预测中常常混淆。但是,除了容易混淆之外,让我们来看一下我们的预测视图中的前两个示例。图片右侧的截断汽车的边框太小。预测要准确得多,但没有达到IoU阈值。来自COCO 2017检测数据集的原始图像。- COCO 2017检测数据集:https://cocodataset.org/#detection-2017
上面的图片中发现的第一个样本有一个注解错误。图像右侧的截断汽车的真实值边界框(粉红色)太小。预测(黄色)更为准确,但未达到IoU阈值。树木阴影下的汽车预测箱是正确的,但没有在真实情况中标出。在我们不匹配的预测视图中找到的第二个样本包含另一种注释错误。实际上,这是一个更为严重的问题。图像中正确预测的边界框(黄色)没有相应的真实性。在树荫下的汽车根本没有标注。手动解决这些错误超出了本示例的范围,因为它需要很大的反馈回路。FiftyOne致力于使反馈回路成为可能(且高效),但现在让我们集中讨论如何回答有关模型性能的问题,并确认我们的模型确实经常混淆公共汽车、小汽车和卡车。我们将通过重新评估合并到单个vehicle标签中的公共汽车,小汽车和卡车的预测来做到这一点。下面的代码创建了这样一个视图,将视图克隆到一个单独的数据集中,这样我们将获得单独的评估结果,并评估合并的标签。vehicle_labels = {
label: "vehicle" for label in ["bus","car", "truck"]
}
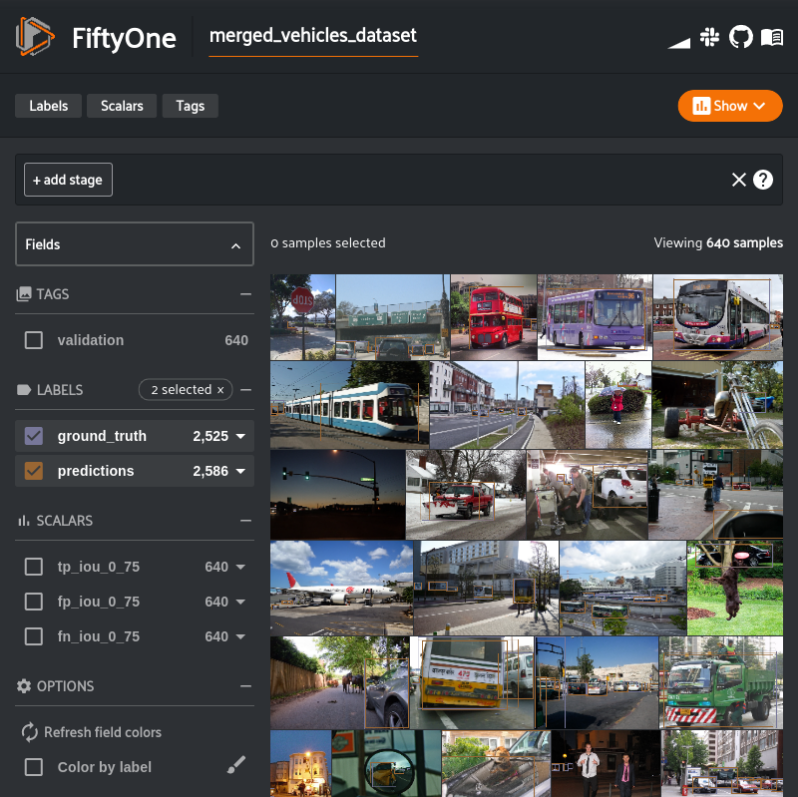
merged_vehicles_dataset = (
vehicles
.map_labels("ground_truth", vehicle_labels)
.map_labels("predictions", vehicle_labels)
.exclude_fields(["tp_iou_0_75", "fp_iou_0_75", "fn_iou_0_75"])
.clone("merged_vehicles_dataset")
)
evaluate_detections(
merged_vehicles_dataset, "predictions", gt_field="ground_truth", iou=0.75)
session.dataset = merged_vehicles_dataset
现在,我们获得了原始分割的公交车,汽车和卡车检测以及合并检测的评估结果。现在,我们可以简单地比较原始评估中的真阳性数与合并评估中的真阳性数。original_tp_count = vehicles.sum("tp_iou_0_75")
merged_tp_count = merged_vehicles_dataset.sum("tp_iou_0_75")
print("Original Vehicles True Positives: %d" % original_tp_count)
print("Merged Vehicles True Positives: %d" % merged_tp_count)
我们可以看到,在合并公共汽车、汽车和卡车标签之前,有1431个真阳性。将三种标签合并在一起产生了1515个真阳性结果。Original Vehicles True Positives: 1431
Merged Vehicles True Positives: 1515
我们能够证实我们的假设!尽管很明显。但是,我们现在有了以数据为基础的理解,可以了解此模型的常见故障模式。现在,整个实验可以与其他人共享。在notebook中,以下内容将截屏最后一个活动的App窗口,因此其他人可以静态查看所有输出。session.freeze() # Screenshot the active App window for sharing
总结
notebook电脑已成为执行和共享数据科学的流行媒体,尤其是在计算机视觉领域。但是,从历史上看,使用视觉数据集一直是一个挑战,我们希望通过像FiftyOne这样的开放工具来应对这一挑战。notebook革命在很大程度上仍处于起步阶段,并将继续发展并成为在社区中执行和交流ML项目的更有说服力的工具,这在一定程度上归功于FiftyOne!感谢你的关注!该FiftyOne项目上可以在GitHub上找到,即下方链接。- https://github.com/voxel51/fiftyone
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看