
「新生手册」:PyTorch分布式训练

极市导读
本文重点介绍了PyTorch原生的分布式数据并行(DDP) 及其用法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
目录
0X01 分布式并行训练概述
0X02 Pytorch分布式数据并行
0X03 手把手渐进式实战
A. 单机单卡 B. 单机多卡DP C. 多机多卡DDP D. Launch / Slurm 调度方式 0X04 完整框架 Distribuuuu
0X05 Reference
文中所有教学代码和日志见:Tutorialgithub.com
文中提到的框架见:Distribuuuugithub.com
希望本文对你有帮助
0X01 分布式并行训练概述
最常被提起,容易实现且使用最广泛的,莫过于数据并行(Data Parallelism) 技术,其核心思想是将大batch划分为若干小barch分发到不同device并行计算,解决单GPU显存不足的限制。与此同时,当单GPU无法放下整个模型时,我们还需考虑 模型并行(Model / Pipeline Parallelism)。如考虑将模型进行纵向切割,不同的Layers放在不同的device上。或是将某些模块进行横向切割,通过矩阵运算进行加速。当然,还存在一些非并行的技术或者技巧,用于解决训练效率或者训练显存不足等问题。
本文的重点是介绍PyTorch原生的分布式数据并行(DDP) 及其用法,其他的内容,我们后面再聊(如果有机会的话qwq)。
这里我草率地将当前深度学习的大规模分布式训练技术分为如下三类:
Data Parallelism (数据并行)
Naive:每个worker存储一份model和optimizer,每轮迭代时,将样本分为若干份分发给各个worker,实现并行计算 ZeRO: Zero Redundancy Optimizer,微软提出的数据并行内存优化技术,核心思想是保持Naive数据并行通信效率的同时,尽可能降低内存占用(https://arxiv.org/abs/1910.02054) Model/Pipeline Parallelism (模型并行)
Naive: 纵向切割模型,将不同的layers放到不同的device上,按顺序进行正/反向传播(https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html) GPipe:小批量流水线方式的纵向切割模型并行(https://proceedings.neurips.cc/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf) Megatron-LM:Tensor-slicing方式的模型并行加速(https://github.com/NVIDIA/Megatron-LM) Non-parallelism approach (非并行技术)
Gradient Accumulation: 通过梯度累加的方式解决显存不足的问题,常用于模型较大,单卡只能塞下很小的batch的并行训练中(https://www.zhihu.com/question/303070254) CPU Offload: 同时利用 CPU 和 GPU 内存来训练大型模型,即存在GPU-CPU-GPU的 transfers操作(https://www.deepspeed.ai/tutorials/zero-offload/) etc.:还有很多不一一罗列(如Checkpointing, Memory Efficient Optimizer等)
不过这里我 强推 一下 DeepSpeed,微软在2020年开源的一个对PyTorch的分布式训练进行优化的库,让训练百亿参数的巨大模型成为可能,其提供的 3D-parallelism (DP+PP+MP)的并行技术组合,能极大程度降低大模型训练的硬件条件以及提高训练的效率
0X02 Pytorch分布式数据并行
将时间拨回2017年,我第一次接触深度学习,早期的TensorFlow使用的是PS(Parameter Server)架构,在结点数量线性增长的情况下,带宽瓶颈格外明显。而随后百度将Ring-Allreduce技术运用到深度学习分布式训练,PyTorch1.0之后香起来的原因也是因为在分布式训练方面做了较大改动,适配多种通信后端,使用RingAllReduce架构。
小提醒 ✊ ,确保你对PyTorch有一定的熟悉程度,此前提下,对如下内容进行学习和了解,基本上就能够handle住大部分的数据并行任务了:
DataParallel 和 DistributedDataParallel 的原理和使用 进程组 和 torch.distributed.init_process_group 的原理和使用 集体通信(Collective Communication) 的原理和使用
关于理论的东西,我写了一大堆,最后又全删掉了。原因是我发现已经有足够多的文章介绍 PS/Ring-AllReduce 和 PyTorch DP/DDP 的原理,给出具有代表性的几篇:
PYTORCH DISTRIBUTED OVERVIEW(https://pytorch.org/tutorials/beginner/dist_overview.html) PyTorch 源码解读之 DP & DDP(https://zhuanlan.zhihu.com/p/343951042) Bringing HPC Techniques to Deep Learning(https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/)
0X03 手把手渐进式实战
那么接下来我们以Step by Step的方式进行实践,你可以直接通过下面的快速索引进行跳转,大部分的解释都包含在代码中,每份代码最后也有使用说明和训练Log记录:
单机单卡 [snsc.py] https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/snsc.py
单机多卡 (with DataParallel) [snmc_dp.py] https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/snmc_dp.py
多机多卡 (with DistributedDataParallel)
torch.distributed.launch [mnmc_ddp_launch.py] https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/mnmc_ddp_launch.py torch.multiprocessing [mnmc_ddp_mp.py] https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/mnmc_ddp_mp.py Slurm Workload Manager [mnmc_ddp_slurm.py] https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/mnmc_ddp_slurm.py ImageNet training example [imagenet.py] https://github.com/BIGBALLON/distribuuuu/blob/master/tutorial/imagenet.py
A. 单机单卡
Single Node Single GPU Card Training, 源码见 snsc.py,后续我们会在此代码上进行修改。简单看一下,单机单卡要做的就是定义网络,定义dataloader,定义loss和optimizer,开训,很简单的几个步骤。
"""(SNSC) Single Node Single GPU Card Training"""import torchimport torch.nn as nnimport torchvisionimport torchvision.transforms as transformsBATCH_SIZE = 256EPOCHS = 5if __name__ == "__main__":# 1. define networkdevice = "cuda"net = torchvision.models.resnet18(num_classes=10)net = net.to(device=device)# 2. define dataloadertrainset = torchvision.datasets.CIFAR10(root="./data",train=True,download=True,transform=transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),]),)train_loader = torch.utils.data.DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True,num_workers=4,pin_memory=True,)# 3. define loss and optimizercriterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9,weight_decay=0.0001,nesterov=True,)print(" ======= Training ======= \n")# 4. start to trainnet.train()for ep in range(1, EPOCHS + 1):train_loss = correct = total = 0for idx, (inputs, targets) in enumerate(train_loader):inputs, targets = inputs.to(device), targets.to(device)outputs = net(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()total += targets.size(0)correct += torch.eq(outputs.argmax(dim=1), targets).sum().item()if (idx + 1) % 50 == 0 or (idx + 1) == len(train_loader):print(" == step: [{:3}/{}] [{}/{}] | loss: {:.3f} | acc: {:6.3f}%".format(idx + 1,len(train_loader),ep,EPOCHS,train_loss / (idx + 1),100.0 * correct / total,))print("\n ======= Training Finished ======= \n")"""usage:python snsc.pyFiles already downloaded and verified======= Training ========= step: [ 50/196] [1/5] | loss: 1.959 | acc: 28.633%== step: [100/196] [1/5] | loss: 1.806 | acc: 33.996%== step: [150/196] [1/5] | loss: 1.718 | acc: 36.987%== step: [196/196] [1/5] | loss: 1.658 | acc: 39.198%== step: [ 50/196] [2/5] | loss: 1.393 | acc: 49.578%== step: [100/196] [2/5] | loss: 1.359 | acc: 50.473%== step: [150/196] [2/5] | loss: 1.336 | acc: 51.372%== step: [196/196] [2/5] | loss: 1.317 | acc: 52.200%== step: [ 50/196] [3/5] | loss: 1.205 | acc: 56.102%== step: [100/196] [3/5] | loss: 1.185 | acc: 57.254%== step: [150/196] [3/5] | loss: 1.175 | acc: 57.755%== step: [196/196] [3/5] | loss: 1.165 | acc: 58.072%== step: [ 50/196] [4/5] | loss: 1.067 | acc: 60.914%== step: [100/196] [4/5] | loss: 1.061 | acc: 61.406%== step: [150/196] [4/5] | loss: 1.058 | acc: 61.643%== step: [196/196] [4/5] | loss: 1.054 | acc: 62.022%== step: [ 50/196] [5/5] | loss: 0.988 | acc: 64.852%== step: [100/196] [5/5] | loss: 0.983 | acc: 64.801%== step: [150/196] [5/5] | loss: 0.980 | acc: 65.052%== step: [196/196] [5/5] | loss: 0.977 | acc: 65.076%======= Training Finished ======="""
B. 单机多卡DP
Single Node Multi-GPU Crads Training (with DataParallel),源码见 snmc_dp.py, 和 snsc.py 对比一下,DP只需要花费最小的代价,既可以使用多卡进行训练(其实就一行???),但是因为GIL锁的限制,DP的性能是低于DDP的。
"""(SNMC) Single Node Multi-GPU Crads Training (with DataParallel)Try to compare with smsc.py and find out the differences."""import torchimport torch.nn as nnimport torchvisionimport torchvision.transforms as transformsBATCH_SIZE = 256EPOCHS = 5if __name__ == "__main__":# 1. define networkdevice = "cuda"net = torchvision.models.resnet18(pretrained=False, num_classes=10)net = net.to(device=device)# Use single-machine multi-GPU DataParallel,# you would like to speed up training with the minimum code change.net = nn.DataParallel(net)# 2. define dataloadertrainset = torchvision.datasets.CIFAR10(root="./data",train=True,download=True,transform=transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),]),)train_loader = torch.utils.data.DataLoader(trainset,batch_size=BATCH_SIZE,shuffle=True,num_workers=4,pin_memory=True,)# 3. define loss and optimizercriterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(net.parameters(),lr=0.01,momentum=0.9,weight_decay=0.0001,nesterov=True,)print(" ======= Training ======= \n")# 4. start to trainnet.train()for ep in range(1, EPOCHS + 1):train_loss = correct = total = 0for idx, (inputs, targets) in enumerate(train_loader):inputs, targets = inputs.to(device), targets.to(device)outputs = net(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()total += targets.size(0)correct += torch.eq(outputs.argmax(dim=1), targets).sum().item()if (idx + 1) % 50 == 0 or (idx + 1) == len(train_loader):print(" == step: [{:3}/{}] [{}/{}] | loss: {:.3f} | acc: {:6.3f}%".format(idx + 1,len(train_loader),ep,EPOCHS,train_loss / (idx + 1),100.0 * correct / total,))print("\n ======= Training Finished ======= \n")"""usage: 2GPUs for trainingCUDA_VISIBLE_DEVICES=0,1 python snmc_dp.pyFiles already downloaded and verified======= Training ========= step: [ 50/196] [1/5] | loss: 1.992 | acc: 26.633%== step: [100/196] [1/5] | loss: 1.834 | acc: 32.797%== step: [150/196] [1/5] | loss: 1.742 | acc: 36.201%== step: [196/196] [1/5] | loss: 1.680 | acc: 38.578%== step: [ 50/196] [2/5] | loss: 1.398 | acc: 49.062%== step: [100/196] [2/5] | loss: 1.380 | acc: 49.953%== step: [150/196] [2/5] | loss: 1.355 | acc: 50.810%== step: [196/196] [2/5] | loss: 1.338 | acc: 51.428%== step: [ 50/196] [3/5] | loss: 1.242 | acc: 55.727%== step: [100/196] [3/5] | loss: 1.219 | acc: 56.801%== step: [150/196] [3/5] | loss: 1.200 | acc: 57.195%== step: [196/196] [3/5] | loss: 1.193 | acc: 57.328%== step: [ 50/196] [4/5] | loss: 1.105 | acc: 61.102%== step: [100/196] [4/5] | loss: 1.098 | acc: 61.082%== step: [150/196] [4/5] | loss: 1.087 | acc: 61.354%== step: [196/196] [4/5] | loss: 1.086 | acc: 61.426%== step: [ 50/196] [5/5] | loss: 1.002 | acc: 64.039%== step: [100/196] [5/5] | loss: 1.006 | acc: 63.977%== step: [150/196] [5/5] | loss: 1.009 | acc: 63.935%== step: [196/196] [5/5] | loss: 1.005 | acc: 64.024%======= Training Finished ======="""
C. 多机多卡DDP
Okay, 下面进入正题,来看一下多机多卡怎么做,虽然上面给出的文章都讲得很明白,但有些概念还是有必要提一下:
进程组的相关概念
GROUP:进程组,大部分情况下DDP的各个进程是在同一个进程组下 WORLD_SIZE:总的进程数量 (原则上一个process占用一个GPU是较优的) RANK:当前进程的序号,用于进程间通讯,rank = 0 的主机为 master 节点 LOCAL_RANK:当前进程对应的GPU号
举个栗子 :4台机器(每台机器8张卡)进行分布式训练
通过 init_process_group() 对进程组进行初始化
初始化后 可以通过 get_world_size() 获取到 world size
在该例中为32, 即有32个进程,其编号为0-31<br/>通过 get_rank() 函数可以进行获取 在每台机器上,local rank均为0-8,这是 local rank 与 rank 的区别, local rank 会对应到实际的 GPU ID 上
(单机多任务的情况下注意CUDA_VISIBLE_DEVICES的使用
控制不同程序可见的GPU devices)
DDP的基本用法 (代码编写流程)
使用 torch.distributed.init_process_group 初始化进程组 使用 torch.nn.parallel.DistributedDataParallel 创建 分布式模型 使用 torch.utils.data.distributed.DistributedSampler 创建 DataLoader 调整其他必要的地方(tensor放到指定device上,S/L checkpoint,指标计算等) 使用 torch.distributed.launch / torch.multiprocessing 或 slurm 开始训练 集体通信的使用
torch.distributed NCCL-Woolley scaled_all_reduce 将各卡的信息进行汇总,分发或平均等操作,需要使用集体通讯操作(如算accuracy或者总loss时候需要用到allreduce),可参考:
不同启动方式的用法
torch.distributed.launch:mnmc_ddp_launch.py torch.multiprocessing:mnmc_ddp_mp.py Slurm Workload Manager:mnmc_ddp_slurm.py
"""(MNMC) Multiple Nodes Multi-GPU Cards Trainingwith DistributedDataParallel and torch.distributed.launchTry to compare with [snsc.py, snmc_dp.py & mnmc_ddp_mp.py] and find out the differences."""import osimport torchimport torch.distributed as distimport torch.nn as nnimport torchvisionimport torchvision.transforms as transformsfrom torch.nn.parallel import DistributedDataParallel as DDPBATCH_SIZE = 256EPOCHS = 5if __name__ == "__main__":# 0. set up distributed devicerank = int(os.environ["RANK"])local_rank = int(os.environ["LOCAL_RANK"])torch.cuda.set_device(rank % torch.cuda.device_count())dist.init_process_group(backend="nccl")device = torch.device("cuda", local_rank)print(f"[init] == local rank: {local_rank}, global rank: {rank} ==")# 1. define networknet = torchvision.models.resnet18(pretrained=False, num_classes=10)net = net.to(device)# DistributedDataParallelnet = DDP(net, device_ids=[local_rank], output_device=local_rank)# 2. define dataloadertrainset = torchvision.datasets.CIFAR10(root="./data",train=True,download=False,transform=transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),]),)# DistributedSampler# we test single Machine with 2 GPUs# so the [batch size] for each process is 256 / 2 = 128train_sampler = torch.utils.data.distributed.DistributedSampler(trainset,shuffle=True,)train_loader = torch.utils.data.DataLoader(trainset,batch_size=BATCH_SIZE,num_workers=4,pin_memory=True,sampler=train_sampler,)# 3. define loss and optimizercriterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(net.parameters(),lr=0.01 * 2,momentum=0.9,weight_decay=0.0001,nesterov=True,)if rank == 0:print(" ======= Training ======= \n")# 4. start to trainnet.train()for ep in range(1, EPOCHS + 1):train_loss = correct = total = 0# set samplertrain_loader.sampler.set_epoch(ep)for idx, (inputs, targets) in enumerate(train_loader):inputs, targets = inputs.to(device), targets.to(device)outputs = net(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()total += targets.size(0)correct += torch.eq(outputs.argmax(dim=1), targets).sum().item()if rank == 0 and ((idx + 1) % 25 == 0 or (idx + 1) == len(train_loader)):print(" == step: [{:3}/{}] [{}/{}] | loss: {:.3f} | acc: {:6.3f}%".format(idx + 1,len(train_loader),ep,EPOCHS,train_loss / (idx + 1),100.0 * correct / total,))if rank == 0:print("\n ======= Training Finished ======= \n")"""usage:>>> python -m torch.distributed.launch --helpexmaple: 1 node, 4 GPUs per node (4GPUs)>>> python -m torch.distributed.launch \--nproc_per_node=4 \--nnodes=1 \--node_rank=0 \--master_addr=localhost \--master_port=22222 \mnmc_ddp_launch.py[init] == local rank: 3, global rank: 3 ==[init] == local rank: 1, global rank: 1 ==[init] == local rank: 0, global rank: 0 ==[init] == local rank: 2, global rank: 2 ========= Training ========= step: [ 25/49] [0/5] | loss: 1.980 | acc: 27.953%== step: [ 49/49] [0/5] | loss: 1.806 | acc: 33.816%== step: [ 25/49] [1/5] | loss: 1.464 | acc: 47.391%== step: [ 49/49] [1/5] | loss: 1.420 | acc: 48.448%== step: [ 25/49] [2/5] | loss: 1.300 | acc: 52.469%== step: [ 49/49] [2/5] | loss: 1.274 | acc: 53.648%== step: [ 25/49] [3/5] | loss: 1.201 | acc: 56.547%== step: [ 49/49] [3/5] | loss: 1.185 | acc: 57.360%== step: [ 25/49] [4/5] | loss: 1.129 | acc: 59.531%== step: [ 49/49] [4/5] | loss: 1.117 | acc: 59.800%======= Training Finished =======exmaple: 1 node, 2tasks, 4 GPUs per task (8GPUs)>>> CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch \--nproc_per_node=4 \--nnodes=2 \--node_rank=0 \--master_addr="10.198.189.10" \--master_port=22222 \mnmc_ddp_launch.py>>> CUDA_VISIBLE_DEVICES=4,5,6,7 python -m torch.distributed.launch \--nproc_per_node=4 \--nnodes=2 \--node_rank=1 \--master_addr="10.198.189.10" \--master_port=22222 \mnmc_ddp_launch.py======= Training ========= step: [ 25/25] [0/5] | loss: 1.932 | acc: 29.088%== step: [ 25/25] [1/5] | loss: 1.546 | acc: 43.088%== step: [ 25/25] [2/5] | loss: 1.424 | acc: 48.032%== step: [ 25/25] [3/5] | loss: 1.335 | acc: 51.440%== step: [ 25/25] [4/5] | loss: 1.243 | acc: 54.672%======= Training Finished =======exmaple: 2 node, 8 GPUs per node (16GPUs)>>> python -m torch.distributed.launch \--nproc_per_node=8 \--nnodes=2 \--node_rank=0 \--master_addr="10.198.189.10" \--master_port=22222 \mnmc_ddp_launch.py>>> python -m torch.distributed.launch \--nproc_per_node=8 \--nnodes=2 \--node_rank=1 \--master_addr="10.198.189.10" \--master_port=22222 \mnmc_ddp_launch.py[init] == local rank: 5, global rank: 5 ==[init] == local rank: 3, global rank: 3 ==[init] == local rank: 2, global rank: 2 ==[init] == local rank: 4, global rank: 4 ==[init] == local rank: 0, global rank: 0 ==[init] == local rank: 6, global rank: 6 ==[init] == local rank: 7, global rank: 7 ==[init] == local rank: 1, global rank: 1 ========= Training ========= step: [ 13/13] [0/5] | loss: 2.056 | acc: 23.776%== step: [ 13/13] [1/5] | loss: 1.688 | acc: 36.736%== step: [ 13/13] [2/5] | loss: 1.508 | acc: 44.544%== step: [ 13/13] [3/5] | loss: 1.462 | acc: 45.472%== step: [ 13/13] [4/5] | loss: 1.357 | acc: 49.344%======= Training Finished ======="""
D. Launch / Slurm 调度方式
这里单独用代码 imagenet.py 讲一下不同的启动方式,更详细的内容请看源码。
我们来看一下这个 setup_distributed 函数:
通过 srun 产生的程序在环境变量中会有 SLURM_JOB_ID, 以判断是否为slurm的调度方式 rank 通过 SLURM_PROCID 可以拿到 world size 实际上就是进程数, 通过 SLURM_NTASKS 可以拿到 IP地址通过 subprocess.getoutput(f"scontrol show hostname {node_list} | head -n1")巧妙得到,栗子来源于 MMCV否则,就使用launch进行调度,直接通过 os.environ["RANK"] 和 os.environ["WORLD_SIZE"] 即可拿到 rank 和 world size
# 此函数可以直接移植到你的程序中,动态获取IP,使用很方便# 默认支持launch 和 srun 两种方式def setup_distributed(backend="nccl", port=None):"""Initialize distributed training environment.support both slurm and torch.distributed.launchsee torch.distributed.init_process_group() for more details"""num_gpus = torch.cuda.device_count()if "SLURM_JOB_ID" in os.environ:rank = int(os.environ["SLURM_PROCID"])world_size = int(os.environ["SLURM_NTASKS"])node_list = os.environ["SLURM_NODELIST"]addr = subprocess.getoutput(f"scontrol show hostname {node_list} | head -n1")# specify master portif port is not None:os.environ["MASTER_PORT"] = str(port)elif "MASTER_PORT" not in os.environ:os.environ["MASTER_PORT"] = "29500"if "MASTER_ADDR" not in os.environ:os.environ["MASTER_ADDR"] = addros.environ["WORLD_SIZE"] = str(world_size)os.environ["LOCAL_RANK"] = str(rank % num_gpus)os.environ["RANK"] = str(rank)else:rank = int(os.environ["RANK"])world_size = int(os.environ["WORLD_SIZE"])torch.cuda.set_device(rank % num_gpus)dist.init_process_group(backend=backend,world_size=world_size,rank=rank,)
那提交任务就可以灵活切换,下面给出32卡使用Slurm调度,以及8卡单结点的Launch调度:
slurm example:32GPUs (batch size: 8192)128k / (256*32) -> 157 itertaion>>> srun --partition=openai -n32 --gres=gpu:8 --ntasks-per-node=8 --job-name=slrum_test \python -u imagenet.py[] == local rank: 7, global rank: 7 ==[] == local rank: 1, global rank: 1 ==[] == local rank: 4, global rank: 4 ==[] == local rank: 2, global rank: 2 ==[] == local rank: 6, global rank: 6 ==[] == local rank: 3, global rank: 3 ==[] == local rank: 5, global rank: 5 ==[] == local rank: 4, global rank: 12 ==[] == local rank: 1, global rank: 25 ==[] == local rank: 5, global rank: 13 ==[] == local rank: 6, global rank: 14 ==[] == local rank: 0, global rank: 8 ==[] == local rank: 1, global rank: 9 ==[] == local rank: 2, global rank: 10 ==[] == local rank: 3, global rank: 11 ==[] == local rank: 7, global rank: 15 ==[] == local rank: 5, global rank: 29 ==[] == local rank: 2, global rank: 26 ==[] == local rank: 3, global rank: 27 ==[] == local rank: 0, global rank: 24 ==[] == local rank: 7, global rank: 31 ==[] == local rank: 6, global rank: 30 ==[] == local rank: 4, global rank: 28 ==[] == local rank: 0, global rank: 16 ==[] == local rank: 5, global rank: 21 ==[] == local rank: 7, global rank: 23 ==[] == local rank: 1, global rank: 17 ==[] == local rank: 6, global rank: 22 ==[] == local rank: 3, global rank: 19 ==[] == local rank: 2, global rank: 18 ==[] == local rank: 4, global rank: 20 ==[] == local rank: 0, global rank: 0 ========= Training ========= step: [ 40/157] [0/1] | loss: 6.781 | acc: 0.703%== step: [ 80/157] [0/1] | loss: 6.536 | acc: 1.260%== step: [120/157] [0/1] | loss: 6.353 | acc: 1.875%== step: [157/157] [0/1] | loss: 6.207 | acc: 2.465%distributed.launch example:8GPUs (batch size: 2048)128k / (256*8) -> 626 itertaion>>> python -m torch.distributed.launch \--nproc_per_node=8 \--nnodes=1 \--node_rank=0 \--master_addr=localhost \--master_port=22222 \imagenet.py[] == local rank: 0, global rank: 0 ==[] == local rank: 2, global rank: 2 ==[] == local rank: 6, global rank: 6 ==[] == local rank: 5, global rank: 5 ==[] == local rank: 7, global rank: 7 ==[] == local rank: 4, global rank: 4 ==[] == local rank: 3, global rank: 3 ==[] == local rank: 1, global rank: 1 ========= Training ========= step: [ 40/626] [0/1] | loss: 6.821 | acc: 0.498%== step: [ 80/626] [0/1] | loss: 6.616 | acc: 0.869%== step: [120/626] [0/1] | loss: 6.448 | acc: 1.351%== step: [160/626] [0/1] | loss: 6.294 | acc: 1.868%== step: [200/626] [0/1] | loss: 6.167 | acc: 2.443%== step: [240/626] [0/1] | loss: 6.051 | acc: 3.003%== step: [280/626] [0/1] | loss: 5.952 | acc: 3.457%== step: [320/626] [0/1] | loss: 5.860 | acc: 3.983%== step: [360/626] [0/1] | loss: 5.778 | acc: 4.492%== step: [400/626] [0/1] | loss: 5.700 | acc: 4.960%== step: [440/626] [0/1] | loss: 5.627 | acc: 5.488%== step: [480/626] [0/1] | loss: 5.559 | acc: 6.013%== step: [520/626] [0/1] | loss: 5.495 | acc: 6.520%== step: [560/626] [0/1] | loss: 5.429 | acc: 7.117%== step: [600/626] [0/1] | loss: 5.371 | acc: 7.580%== step: [626/626] [0/1] | loss: 5.332 | acc: 7.907%
0X04 完整框架 Distribuuuu
Distribuuuu 是我闲(没)来(事)无(找)事(事)写的一个完整的纯DDP分类训练框架,足够精简且足够有效率。支持launch和srun两种启动方式,可以作为新手学习和魔改的样板工程。
# 1 node, 8 GPUspython -m torch.distributed.launch \--nproc_per_node=8 \--nnodes=1 \--node_rank=0 \--master_addr=localhost \--master_port=29500 \train_net.py --cfg config/resnet18.yaml# see srun --help# and https://slurm.schedmd.com/ for details# example: 64 GPUs# batch size = 64 * 128 = 8192# itertaion = 128k / 8192 = 156# lr = 64 * 0.1 = 6.4srun --partition=openai-a100 \-n 64 \--gres=gpu:8 \--ntasks-per-node=8 \--job-name=Distribuuuu \python -u train_net.py --cfg config/resnet18.yaml \TRAIN.BATCH_SIZE 128 \OUT_DIR ./resnet18_8192bs \OPTIM.BASE_LR 6.4
下面是用 Distribuuuu 做的一些简单的实验,botnet50 是复现了今年比较火的 Transformer+CNN 的文章 Bottleneck Transformers for Visual 的精度,主要是证明这个框架的可用性, resnet18最后小测了 64卡/16384BS 的训练, 精度尚可。另外稍微强调一下SyncBN不要随便乱用,如果单卡Batch已经足够大的情况下不需要开SyncBN。
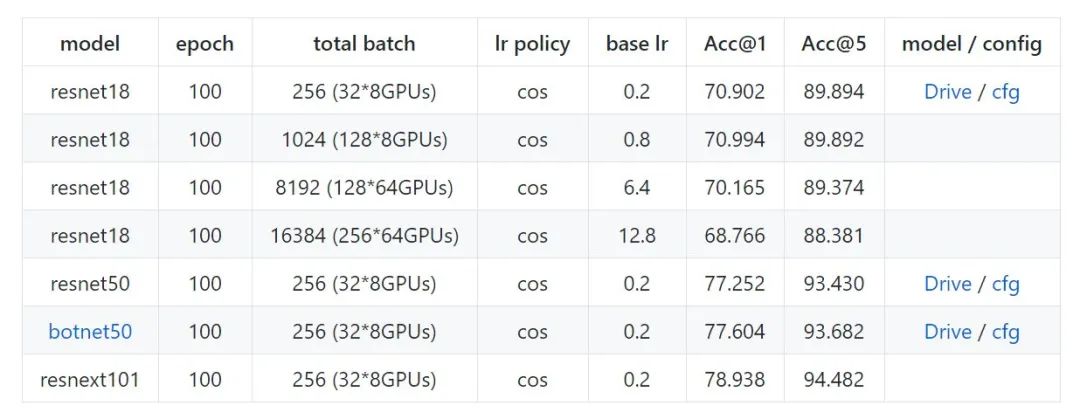
Distribuuuu benchmark (ImageNet)
如果是出于学习目的,想进行一些魔改和测试,可以试试我的Distribuuuu(https://github.com/BIGBALLON/distribuuuu),因为足够简单很容易改吖 ,如果你想做research的话推荐用FAIR的 pycls, 有model zoo 而且代码足够优雅。另外,打比赛的话就不建议自己造轮子了,分类可直接魔改 pycls 或 MMClassification, 检测就魔改 MMDetection 和 Detectron2 就完事啦
Reference
PYTORCH DISTRIBUTED OVERVIEW PyTorch 源码解读之 DP & DDP Bringing HPC Techniques to Deep Learning Parameter Servers Ring-Allreduce:Launching and configuring distributed data parallel applications PyTorch Distributed Training Kill PyTorch Distributed Training Processes NCCL: ACCELERATED MULTI-GPUCOLLECTIVE COMMUNICATIONS WRITING DISTRIBUTED APPLICATIONS WITH PYTORCH PyTorch Distributed: Experiences on Accelerating Data Parallel Training Pytorch多机多卡分布式训练 Launching and configuring distributed data parallel applications
那今天就到这里吧,如果你有问题,用任何方式联系我都阔以,我康到就会解答啦(如果我会的话啦) ✌️ ,另外如果大家感兴趣的话,康康要不要出第二篇(如果有时间的话啦) ✍️
推荐阅读
2021-03-27

2021-03-05

2021-01-17

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
