
PyTorch分布式训练进阶:这些细节你都注意到了吗?

导语 | pytorch作为目前主流的深度学习训练框架之一,可以说是每个算法同学工作中的必备技能。此外,pytorch提供了极其方便的API用来进行分布式训练,由于最近做的工作涉及到一些分布式训练的细节,在使用中发现一些之前完全不会care的点,现记录于此,希望对有需求的同学有所帮助。
本文包含:
pytorch分布式训练的工作原理介绍。
一些大家平时使用时可能不太注意的点,这些点并不会导致直观的bug或者训练中断,但可能会导致训练结果的偏差以及效率的降低。
同时结合某些场景,介绍更为细粒度(group)的分布式交互方式。
名词解释 :
DP: DataParallel
DDP:DistributedDataParaller
基于DDP的多机单卡模型
world_size:并行的节点数
rank:节点的index,从0开始
group_size:并行group的节点数
group_ws:group数量
group_rank:group的index,从0开始
local_group_rank:一个group内部的节点index,从0开始
group_rank_base:一个group内local_group_rank为0的节点的rank
举例:
使用6节点,group_size=3,则group_ws=2则各个参数的对应关系如下:
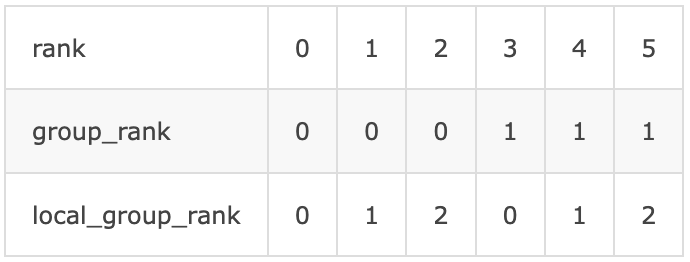
group 0的group_rank_base为0,group 1的group_rank_base为3。
一、DataParallel和DistributedDataParallel
pytorch提供了两种分布式训练的接口,DataParallel(单机多卡)和DistributedDataParallel(多机单卡,多机多卡)。
(一)DataParallel(DP)
先看下DataParallel的工作原理:

module:即要进行的并行的模型,为nn.Module子类实例
device_ids:需要进行并行的卡
output_device:模型最终输出进行汇总的卡,默认是local_rank=0的卡(以下简称“卡0”)
以单机4卡为例,当接到一个batch size=128的数据时,卡0会将128的个数分成32*4,然后将模型拷贝到1~3卡,分别推理32个数据后,然后在output_device(默认为卡0)上进行输出汇总,因为每次推理都会需要进行模型的拷贝,整体效率较低。
注意:
当使用DP的时候,会发现卡0的显存占用会比其他的卡更多,原因便在于默认情况下,卡0需要进行输出的汇总,如果模型的输出是一个很大tensor,可能会导致卡0负载极其不均衡爆显存,从而不得不降低整体的bs导致其他卡的显存利用率低。
解决方案:
由于卡0进行输出的汇总,因此我们可以把loss的求解放到模型内部,这样模型的输出就是一个scalar,能够极大的降低卡0汇总带来的显存负载。
(二)DistributedDataParallel(DDP)

其他的参数含义类似DP,这里重点说下:
broadcast_buffers:在每次调用forward之前是否进行buffer的同步,比如bn中的mean和var,如果你实现了自己的SyncBn可以设置为False。
find_unused_parameters:是否查找模型中未参与loss“生成”的参数,简单说就是模型中定义了一些参数但是没用上时需要设置,后面会详细介绍。
process_group:并行的group,默认的global group,后面细粒度分布式交互时会详细介绍。
DistributedDataParallel的则很好的解决了DP推理效率低的问题,这里以多机单卡为例:DDP会在初始化时记录模型的参数和buffer等相关信息,然后进行一次参数和buffer的同步,这样在每次迭代时,只需要进行梯度的平均就能保证参数和buffer在不同的机器上完全一致。
多机多卡情况下,在一个机器内部的工作原理和DP一致,这也是为什么torch官方会说多机单卡是效率最高的方式。
目前主要使用DDP的多机单卡模式进行分布式训练,后文都将基于该设置进行介绍。
DDP训练中需要注意的点:
由于DDP在初始化会遍历模型获取所有需要进行同步操作的参数和buffer并记录,因此,一旦初始化了DDP就不要再对内部模型的参数或者buffer进行增删,否则会导致新增的参数或buffer无法被优化,但是训练不会报错。
如果你是做类似NAS这种需要进行子图推理的任务或者模型定义了未使用参数,则必须设置find_unused_parameters为True,否则设置为False。如果是后者,请检查模型删除无用的参数,find_unused_parameterss设置为True时会有额外的开销。
buffer是在forward前进行同步的,所以其实训练最后一个iter结束时,不同卡上的buffer是不一样的(虽然这个差异很小),如果需要完全一致,可以手动调用DDP._sync_params_and_buffers()
类似NAS这种动态子图,且你的优化器设置了momentum等除了grad以外其他需要参与梯度更新的参数时需要特别注意:在pytorch中,required_grad=False的参数在进行参数更新的时候,grad为None,所以torch中优化器的step中有一个p.grad is not None的判断用来跳过这些参数:
for group in self.param_groups:....for p in group['params']:if p.grad is not None:params_with_grad.append(p)d_p_list.append(p.grad)state = self.state[p]if 'momentum_buffer' not in state:momentum_buffer_list.append(None)else:momentum_buffer_list.append(state['momentum_buffer'])....
正常训练没有任何问题,但是使用动态子图时,即使对当前iter没有优化的子图的参数设置required_grad=False,如果该子图之前曾经被优化过,则它的grad会变成全0而不是None。例如有两个子图A和B,优化顺序为A->B->A:1.第一次优化A时,B的grad为None,一切正常;2.第一个优化B时,由于A已经被优化过,此时A的grad为0,优化器的判断无法过滤到该参数,因此会沿着第一次优化A时的buffer(如momentum)进行错误的优化。如果子图数量很多的话,某一个子图可能会被错误的优化成千上万次。解决方案有两个:一个是把优化器中的
if p.grad is not None:改成
if p.grad is not None (p.grad == 0).all():或者在每次调用optim.step()之前,加一句:
for p in model.parameters():if p.grad is not None and (p.grad == 0).all():p.grad = None
DDP的梯度汇总使用的是avg,因此如果loss的计算使用的reduce_mean的话,我们不需要再对loss或者grad进行/ world_size的操作。
二、使用DDP时的数据读取
DDP不同于DP需要用卡0进行数据分发,它在每个node会有一个独立的dataloader进行数据读取,一般通过DistributedSampler(DS)来实现:
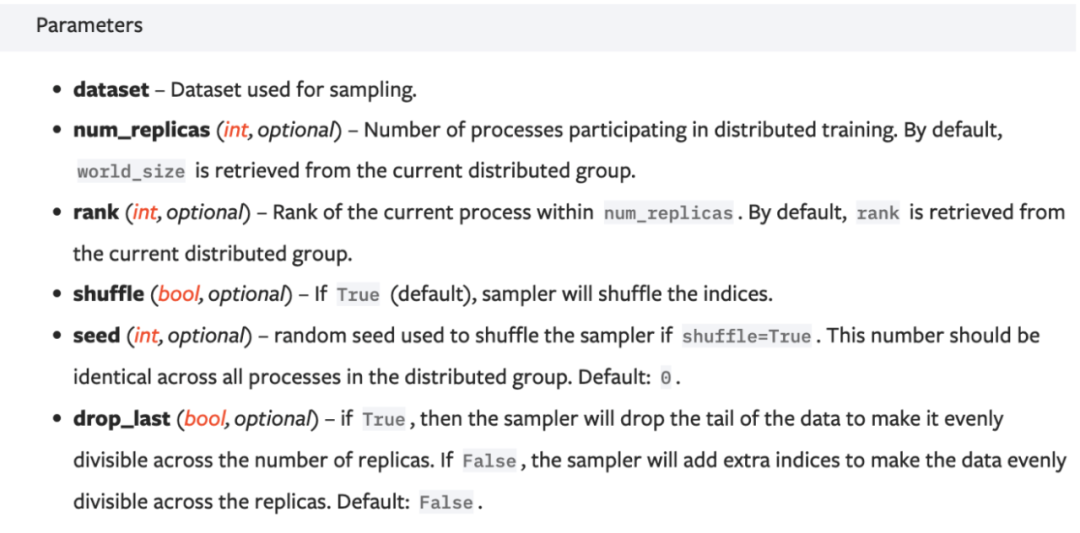
DS会将range(len(dataset))的indices拆分成num_replicas(一般为word_size),不同rank的节点读取不同的数据进行训练,一个简单的分布式训练示例:
from torch import distributed as distfrom torch.utils.data.distributed import DistributedSamplerimport torch.utils.data as Dataassert torch.cuda.is_available()if not dist.is_initialized():dist.init_process_group(backend='nccl')rank = dist.get_rank()world_size = dist.get_world_size()model = MyModel().cuda()ddp_model = DistributedDataParallel(model, device_ids=[torch.cuda.current_device()]).cuda()dataset = MyDataset()sampler = DistributedSampler(dataset, rank, world_size, shuffle=True)dataloader = Data.DataLoader(dataset, batch_size, drop_last=False, sampler=sampler, shuffle=False, num_workers=8, pin_memory=True)# training
注意:
如果你的模型使用了分布式评估:
评估需要用到所有测试数据的结果进行整体统计。
精度的计算和数据顺序相关,则你需要注意DS中:
初始化时会对数据进行padding,padding后的数量为:
real_data_num = int(math.ceil(len(dataset) * 1.0 / world_size)) * world_size因此直接评估可能会使得某些样本被重复评估导致精度结果误差,尤其是测试数据量不大,测试数据样本之间难易程度差距较大时
slice的方式为等间距slice,step为world size,因此直接将不同rank的输出拼接的话,顺序和原始的datast并不一致。
注意:
可以看到,上述代码示例中DataLoader的pin_memory设置为True,torch会在返回数据前将数据直接放到CUDA的pinned memory里面,从而在训练时避免从一次从cpu拷贝到gpu的开销。但是只设置该参数不太会导致数据读取速度变快,原因是该参数需要搭配使用,要将代码中的数据拷贝由.cuda()变更为.cuda(non_blocking=True)
三、分布式训练进阶:Group
根据上述介绍,基本可以满足常规的分布式训练了。但是像诸如nas这种可能需要同时训练多个网络时,考虑到用户的不同需求(子网络可能需要并行,也可能并不需要并行),我们需要对分布式过程进行更加细粒度的控制,这种控制也可以让我们能在数据读取和通信开销做trade off。
在torch的分布式api中基本都包含group(或process_group)这个参数,只不过一般情况下不太需要关注。它的作用简言之就是对分布式的节点数进行划分成组,可以在组内进行分布式通信的相关操作。初始化api如下:
ranks = [0,1,2,3]gp = dist.new_group(ranks, backend='nccl')
上述代码会将节点[0,1,2,3]作为一个group,在后续的分布式操作(如:broadcast/reduce/gather/barrier)中,我们只需传入group=gp参数,就能控制该操作只会在[0,1,2,3]中进行而不会影响其他的节点。
注意:
在所有的节点上都需要进行所有group的初始化,而不是只初始化当前rank所属的group,如使用12卡,group size设置为4,则12/4=3个group对应的rank分别为[0,1,2,3][4,5,6,7][8,9,10,11],这12个节点都需要初始化三个group,而不是rank0,1,2,3只用初始化group0:
rank = dist.get_rank()group_ranks = [[0,1,2,3], [4,5,6,7],[8,9,10,11]]cur_gp = Nonefor g_ranks in group_ranks:gp = dist.new_groups(g_ranks)if rank in g_ranks:cur_gp = gp# 后续使用cur_gp即可
注意:
如果进行兼容性考虑的话,比如group_size=1或者group_size=world_size,此时不需要创建group,但是为了代码的一致性,所有的分布式操作都需要传入group参数,需要注意的是新版本的torch,分布式op的group参数缺省值为None,当检测到None会自动获取group.WORLD,但是旧版本的缺省参数为group.WORLD,传入None会报错,可以尝试做以下兼容(具体从哪个版本开始变更没有尝试过,以下仅为sample):
import torchfrom torch.distributed.distributed_c10d import _get_default_groupdef get_group(group_size, *args, **kwargs):rank = dist.get_rank()world_size = dist.get_world_size()if group_size == 1:# 后续不会涉及到分布式的操作return Noneelif group_size == world_size:v = float(torch.__version__.rsplit('.', 1)[0])if v >= 1.8:return Noneelse:return _get_default_group()else:# 返回当前rank对应的group
(一)模型在group内的并行
只需在DDP初始化的时候把gp赋值给process_group即可
(二)数据在group内的读取
使用带group的DDP训练时,数据读取依旧使用DS,不同的是num_replicas和rank参数不再等于world_size和节点的真实rank,而要变更为group_size和local_group_rank(见名词解释部分)。这个也很好理解,举个例子:
6卡,group_size为3,每个group内有3个节点,模型在这3个节点上并行。
训练该模型相应的数据也应只在这3个节点上进行,所以DS的num_replicas变更为group_size。
另外,DS中的rank参数决定了当前节点读取哪些数据(用来进行indices划分),因此,对于一个group内部而言,该参数需要变更为当前节点在当前group的序号,即local_group_rank。
四、某些分布式训练场景下IO瓶颈
这里只介绍多机单卡场景(即一个scheduler和多个worker,且scheduler和每个worker只有一张GPU),且针对某些对于小文件io密集型不太友好的文件系统:
对应数据集不大的,可以考虑做成lmdb或者运行时将数据拷贝到docker的路径下。
数据集大,无法采用上述方案时,如果进行大规模分布式,io问题会更加严重:调度系统可能将worker映射到物理机上,可能导致多个worker都映射到同一台物理机器,虽然设置的cpu核心和内存,不同的node还是会进行资源抢占,导致速度变慢,为此需要进行数据分发:
方式一:group0中的对应节点进行数据读取,然后分发到其他group的对应节点上,即rank0,1,2各自读取1/3的数据,然后通过broadcast将数据广播,rank0的数据广播至rank3,rank1至rank4以此类推。
方式二:rank0的节点读取所有数据,然后在group0内进行scatter,然后使用方式一broadcast到其他group。
采用方式一还是二取决于你的数据读取开销,如果group size很大,那么group0的资源抢占可能就很严重,导致速度降低,如果只有rank0进行数据读取的话,虽然不会存在资源抢占(gemini的scheduler不会和worker映射到同一台机器),但是bs会增大可能会导致读取变慢。
在gpu正常的情况下,数据broadcast的开销相对较小。
注意:
使用数据broadcast自然需要dataset返回的所有数据均是tensor,meta信息诸如字符串类型的数据无法broadcast。
进行数据broadcast时需要新建一系列的data group,因为它的维度和模型并行的维度不一样,模型是在[0,1,2]和[3,4,5]上并行,数据是在0->3,1->4,2->5上broadcast,因此需要新建三个group[0,3][1,4][2,5]
broadcast自然需要知道数据维度,结合前面讲到的DS补齐操作,注意每个epoch最后一个batch数据的bs可能不到设置的bs(drop_last=False时),因此broadcast需要进行额外的处理。
当不同的group之间代码的逻辑可能不一样时,使用broadcast需要额外注意,比如group0训练1个网络,group1训练2个网络,数据由group0进行broadcast,group0训完第一个网络就break,导致group1训练第二个网络时接受不到broadcast的数据而卡死。
推荐阅读
