
三大特征选择策略,有效提升你的机器学习水准
转自:机器之心公众号
选自Medium
机器之心编译
参与:刘晓坤、黄小天
特征选择是数据获取中最关键的一步,可惜很多教程直接跳过了这一部分。本文将分享有关特征选择的 3 个杰出方法,有效提升你的机器学习水准。
「输入垃圾数据,输出垃圾结果」——每个机器学习工程师
什么是特征选择?面对试图解决的实际问题之时,什么特征将帮助你建模并不总是很清晰。伴随这一问题的还有大量数据问题,它们有时是多余的,或者不甚相关。特征选择是这样一个研究领域,它试图通过算法完成重要特征的选取。
为什么不把全部特征直接丢进机器学习模型呢?
现实世界的问题并没有开源数据集,其中更没有与问题相关的信息。而特征选择有助于你最大化特征相关性,同时降低非相关性,从而增加了构建较好模型的可能性,并减小模型的整体大小。
顶级的特征选择方法
比如说我们要预测水上公园的票价走势;为此我们决定查看天气数据、冰淇淋销量、咖啡销量以及季节状况。
从下表中我们可以看到,夏季的门票明显比其他季节好卖,而冬季卖不出一张票。咖啡销量整年中比较稳定,冰淇淋则一年之中都有销量,但旺季是 6 月。
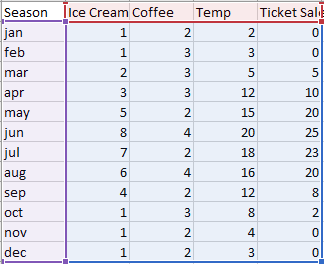
表 1:文中使用的各项虚构数据。
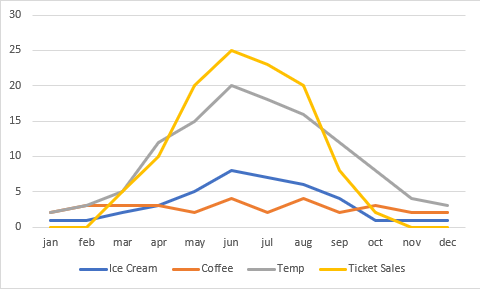
图 1:各项虚构数据的图示对比。
我们想要预测水上公园票价,但很可能不需要所有数据以得到最佳结果。数据存在 N 个维度,并且 K 数值会给出最佳结果。但是不同大小的子集之间存在大量的结合。
我们的目标是减少维度数量,同时不损失预测能力。让我们退回一步,看看那些我们能使用的工具。
穷举搜索
这项技术能 100% 保证找到最好的可能特征以建立模型。我们认为它非常可行,因为它将搜索所有可能的特征组合并找到返回模型最低点的组合。
在我们的例子中有 15 个可能的特征组合可供搜索。我使用公式 (2^n—1) 计算组合的数量。这个方法在特征数量较少的时候可行,但如果你有 3000 个特征就不可行了。
幸运的是,还有一个稍微好点的方法可用。
随机特征选择
大多数情形中,随机特征选择可以工作的很好。如果要将特征数减少 50%,只需随机选择其中 50% 的特征并删除。
模型训练完成之后,检验模型的性能,重复这个过程直到你满意为止。遗憾的是,这仍然是个蛮力方法。
当需要处理一个很大的特征集,又不能削减规模的时候,该怎么办?
最小冗余最大关联特征选择
将所有的想法整合起来就能得出我们的算法,即 mRMR 特征选择。算法背后的考虑是,同时最小化特征的冗余并最大化特征的关联。因此,我们需要计算冗余和关联的方程:

让我们用虚构的数据写一个快速脚本来实现 mRMR:
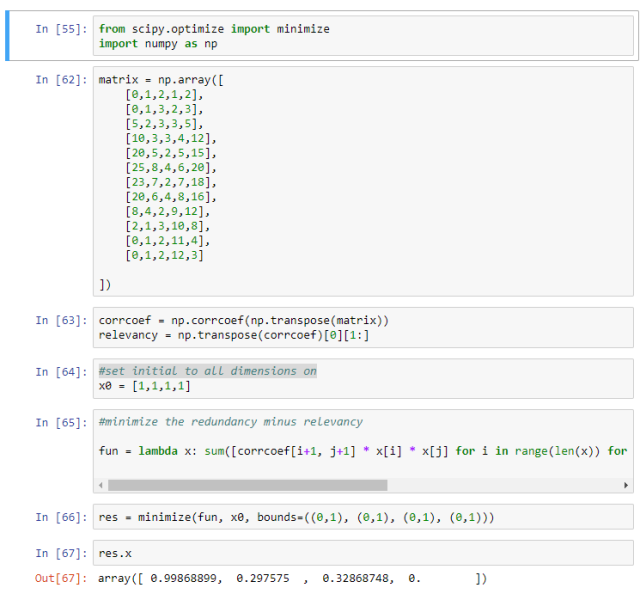
我并没有对结果抱有什么期待,冰淇淋的销量看起来能很精确地对售票量建模,而气温不可以。在这个例子中,似乎只需要一个变量就可以精确地对售票量建模,但在实际的问题中肯定不是这样的。
mRMR 代码地址:https://files.fm/u/bshx9hay
结论
你应该对这些特征选择方法有更好的理解,它们能帮助你减少模型特征的总数量,并保留对目标来说最重要的特征。![]()
原文链接:https://medium.com/towards-data-science/three-effective-feature-selection-strategies-e1f86f331fb1
《数据科学与人工智能》公众号推荐朋友们学习和使用Python语言,需要加入Python语言群的,请扫码加我个人微信,备注【姓名-Python群】,我诚邀你入群,大家学习和分享。