
赠书福利|用BERT夺腾讯算法大赛50万元大奖,冠军团队的解决方案开源!
(给机器学习算法与Python实战加星标,提升AI技能)

文末赠书福利
机器之心报道
这三位程序员,用 BERT 捧走了 50 万人民币的高额奖金。

用户出现的总次数和天数
用户点击广告的总次数
用户点击不同广告、产品、类别、素材、广告主的总数
用户每天每条广告点击的平均次数,均值和方差
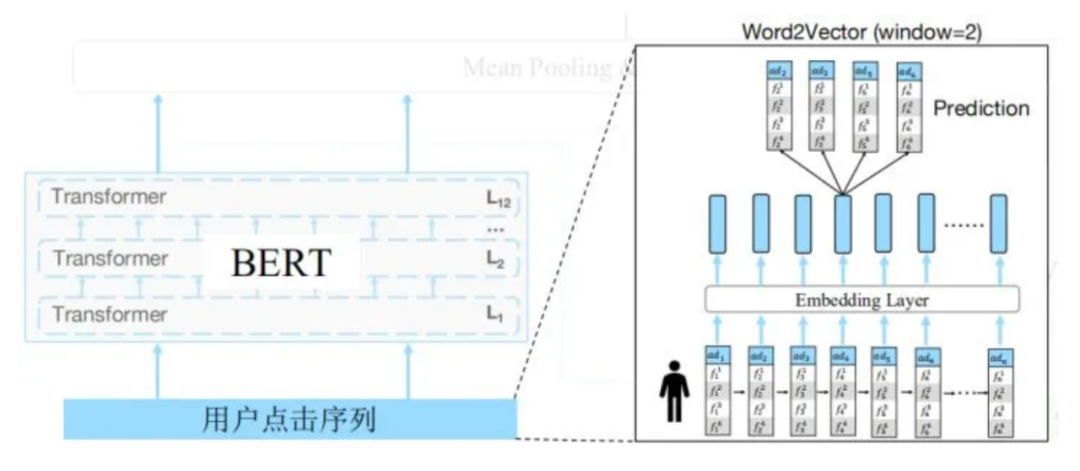
预训练:Word2Vector
预训练:Masked Language Modeling (MLM)
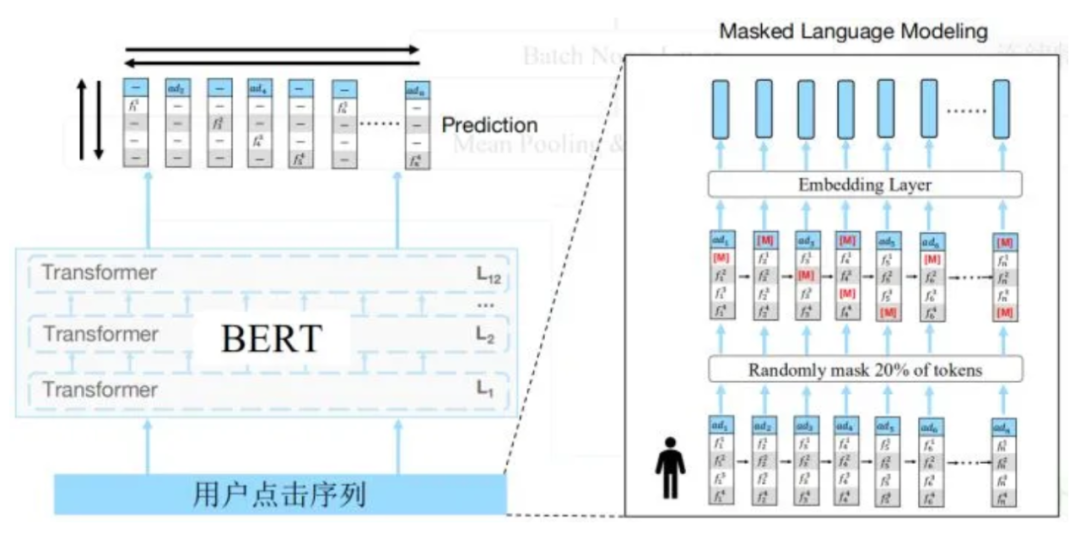
同时,DYG 团队针对词表过大的问题采用了一个很关键的策略:把词表缩小到 10 万(提取 top10w,其余为 unk),在预训练阶段只预测这 10 万个单词,从而使 bert 能够跑起来。
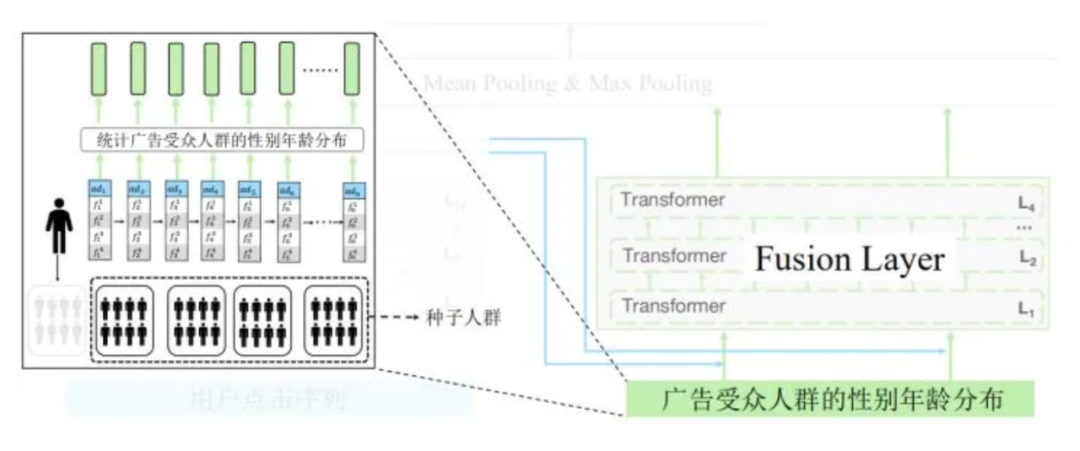
分阶段预训练,缓解广告稀疏性问题并加快预训练速度 (4*V100 预训练 12 个小时)
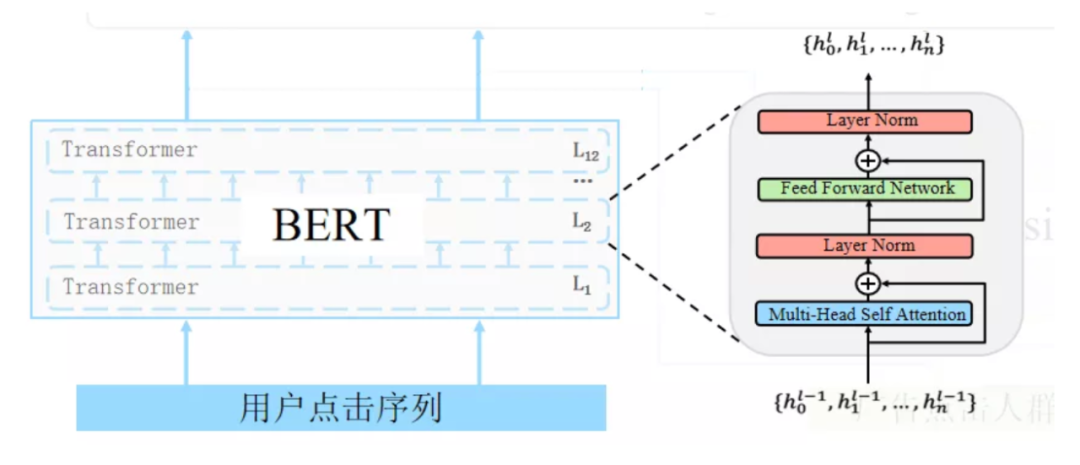
改进 MLM 预训练目标,并从多维度学习广告及其属性的语义表示
将 BERT 运用到人口属性预测的场景,从性能上验证了预训练在广告领域的潜力
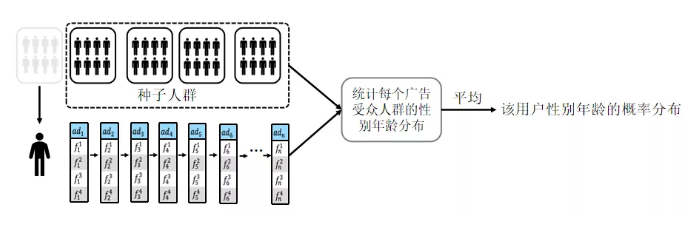
利用受众人群求出每个广告的概率分布
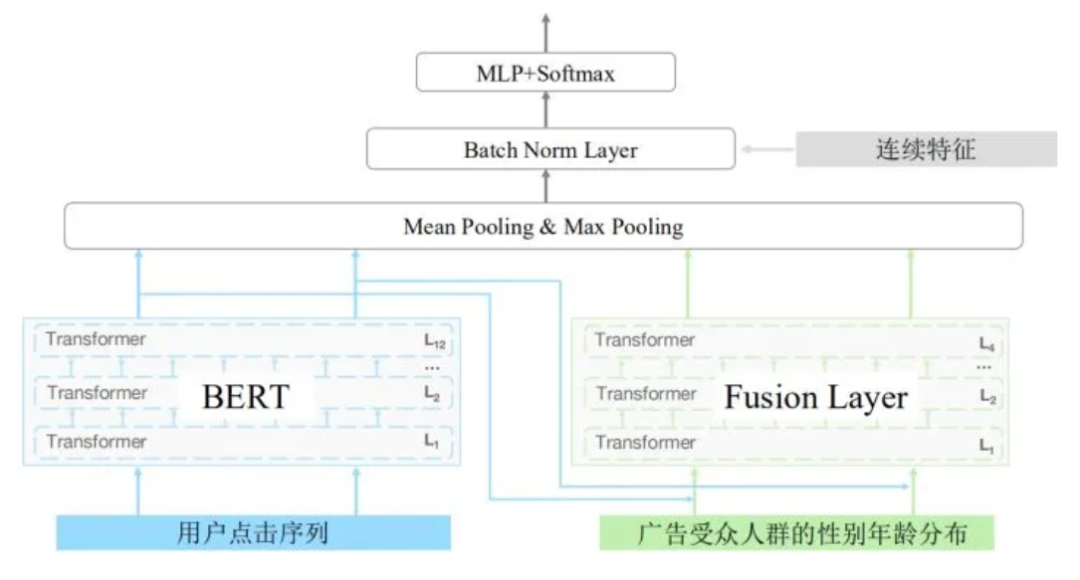
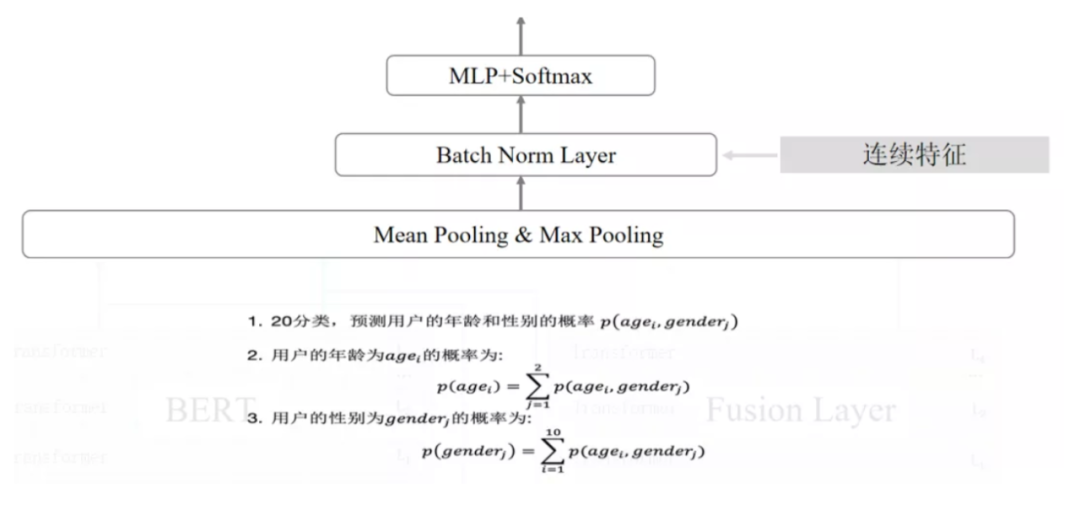
利用多层 Transformer 融合概率分布及 BERT 的语义表示,能有效提升性能
福利时间:

爱学习的土豪可以直接买↑↑↑
本次联合【电子工业出版社】为大家带来前阿里高级开发工程师创作的《机器学习算法框架实战:Java和Python实现》,一共2本。
赠书方式一:后台回复【888】,抽奖1本
赠书方式二:添加我的微信,朋友圈抽奖1本
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论