
各种机器学习和深度学习的中文微博情感分析

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
"情感分析"是我本科的毕业设计, 也是我入门并爱上NLP的项目hhh, 当时网上相关语料库的质量都太低了, 索性就自己写了个爬虫, 一边标注一边爬, 现在就把它发出来供大家交流。因为是自己的项目,所以标注是相当认真的,还请了朋友帮忙校验,过滤掉了广告/太短/太长/表意不明等语料,语料质量是绝对可以保证的
带情感标注的微博语料数量: 10000(train.txt)+500(test.txt)
数据格式
文档的每一行代表一条语料
每条语料的第一个数据为微博对应的
mid,是每条微博的唯一标签,可以通过"https://m.weibo.cn/status/" + mid 访问到该条微博的网页(部分微博可能已被博主删除)第二个数据为情感标签,
0表示负面,1表示正面其余后面部分都是微博文本
微博表情都被转义成[xx]的格式, 如:
[doge]
[允悲]
微博话题/地理定位/视频、文本超链接等都转义成了
{%xxxx%}的格式,使用正则可以很方便地将其清洗
项目说明
训练集10000条语料, 测试集500条语料
使用朴素贝叶斯、SVM、XGBoost、LSTM和Bert, 等多种模型搭建并训练二分类模型
前3个模型都采用端到端的训练方法
LSTM先预训练得到Word2Vec词向量, 在训练神经网络
Bert使用的是哈工大的预训练模型, 用Bert的[CLS]位输出在一个下游网络上进行finetune。预训练模型需要自行下载:github下载地址: https://github.com/ymcui/Chinese-BERT-wwm
baidu网盘: https://pan.baidu.com/s/16z-ybrqT6wLdy_mLHtywSw 密码: djkj
下载后将文件夹放在
./model文件夹下, 并将bert_config.json改名为config.json
全部项目代码,微博语料数据集 获取方式:
关注微信公众号 datanlp 然后回复 情感分析 即可获取。
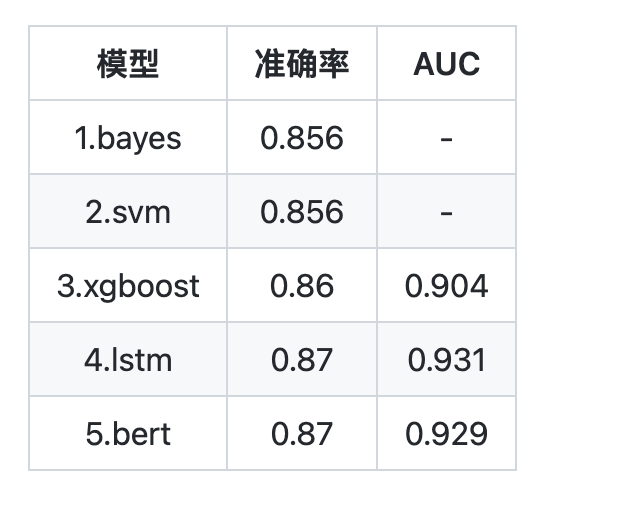
实验结果
各种分类器在测试集上的测试结果
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx