
Facebook首次揭秘:超过10亿用户使用的Instagram推荐算法是怎样炼...
新智元报道
来源:Venturebeat
编辑:大明
【新智元导读】目前,每年约有5亿用户通过Instagram的自建推荐功能搜索和发现自己喜欢的内容,其背后的推荐引擎是怎样炼成的呢?近日,Facebook发表博客文章,首次对这个名为Explore的推荐引擎的原理和机制进行全方位揭秘,一起来看看!来 新智元AI朋友圈 和AI大咖们一起讨论吧。
在目前Instagram大约10亿用户中,超过一半的人每月都通过Instagram Explore来搜索视频、图片、直播和各种文章。可以预见,为这些用户构建服务基础的推荐引擎,需要负责整理上传到Instagram的数十亿条内容,这是个工程上的大难题,尤其是这些内容还是实时生成的。
在近日发表的一篇博客文章中,Facebook首次揭开了Explore内部的运行机制。Facebook称,Explore是个由三部分组成分级漏斗,使用自定义查询语言和建模技术,目前已提取了650亿个特征,每秒可以做出9000万次模型预测。而且,这些还只是冰山一角。
10亿用户使用的推荐工具,背后有着怎样的奥秘?
在开始构建内容推荐系统之前,开发团队已经使用大量工具进行了大规模实验,并获得关于用户关注兴趣的强烈信号。研究人员使用的首款工具是IGQL,这是一种元语言,能够提供对候选算法进行集中聚合所需的概要信息。
Facebook表示,经C++优化的IGQL可在不牺牲可扩展性的情况下最大程度地降低延迟,减少计算资源的消耗。工程师能够以“类似Python”的方式编写推荐算法,并补充了帐户嵌入组件,可以识别局部高度相似的配置文件,并将其作为帐户级信息的检索流程的一部分。
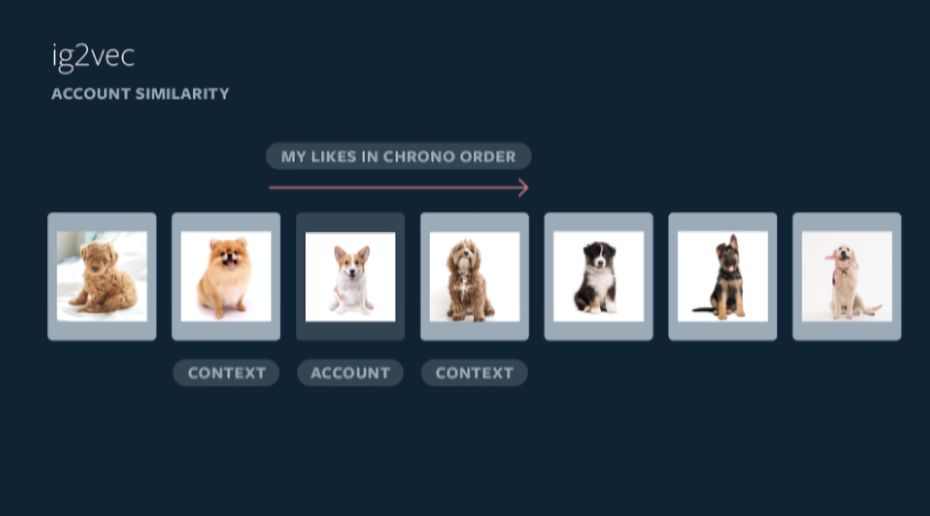
上图:ig2vec预测账户内容相似性的功能演示
Ig2vec框架将用户与之交互的Instagram帐户视为句子中的单词序列,通知用户可能与之交互的模型预测。(与随机帐户相比,会话中进行交互的一系列帐户在局部上的连贯性更高。)同时,Facebook的AI会搜索最近邻域检索库(FAISS)来查询数百万个帐户进行训练。
Facebook表示,在Explore中基于兴趣对账户进行排名,需要预测与每个账户相关度最高的内容,生成轻量级排名提炼模型,该模型在将候选账户传递给更复杂的排名模型之前,会对账户进行预选。利用较复杂模型的特征和输出的候选输入的知识,较简单的模型会尝试通过直接(和间接)学习来尽可能近似主排名模型。
Explore架构和运行机制
Explorer运行包括两个阶段:候选内容生成阶段(也称为“采购”阶段)和排名阶段。
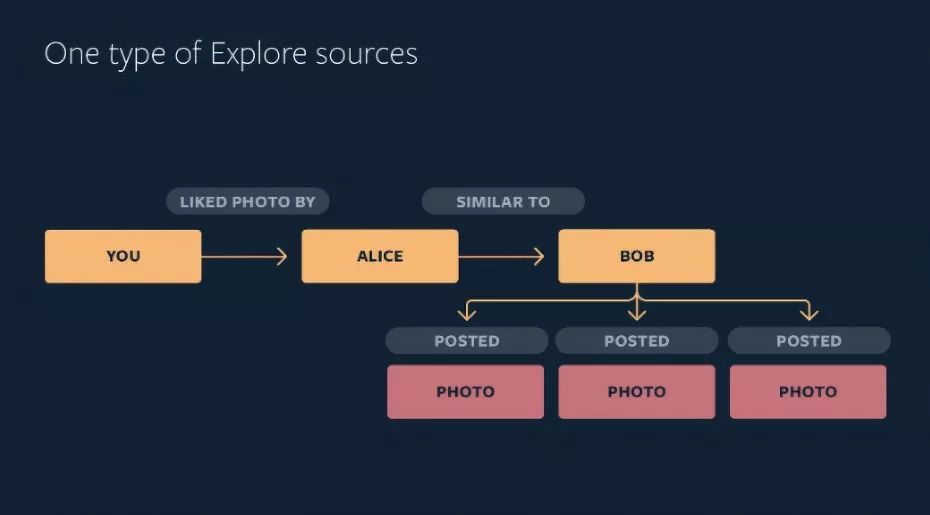
在生成阶段,Explore会挖掘用户以前与之交互过的帐户,以识别感兴趣的“种子帐户”。这些账户只是兴趣相同的帐户的一小部分,但与“兴趣相同”账户筛选结合使用,可以更高效地识别局部相似的帐户。
了解可能吸引用户的帐户是哪些,这是确定哪些内容可能会被筛选出来的第一步。IGQL允许将不同的候选内容源表示为不同的子查询,这样Explore就可以在多种类型的内容源中为普通人找到成千上万的合格候选内容。
上图所示为一个典型的Explore推荐内容源
为了确保推荐内容的安全,适合所有年龄段的用户,系统利用信号来过滤可能不符合要求的内容。在为每个用户建立推荐列表之前,会由算法进行检测,过滤垃圾邮件和其他内容。
根据Facebook最新的社区标准执行报告的内容,这套过滤系统非常有效。在2019年第三季度,Facebook删除了涉及自残内容数量达到84.5万条,其中主动检测到79.1%,在过去四个季度中,Facebook删除了超过99%的儿童裸体色情内容和剥削职位。
对于每个“explore”排名请求,系统将从数千个采样样本中选择500个候选,并将结果送至排名阶段(即上文所说的第二阶段)。这个阶段由三部分的基础架构组成,旨在实现内容相关度和计算效率的平衡。
在排名阶段的第一阶段,滤过模型以最少的特征数量模拟其他阶段的组合。它从500个最优质和最相关的候选内容中选出1个,然后,具有完全密集特征集的模型(第二阶段)会选择前50个候选内容。最后,另一个具有全特征的模型将选择25个最佳候选内容,这些候选内容将填充至“explore”网格中。
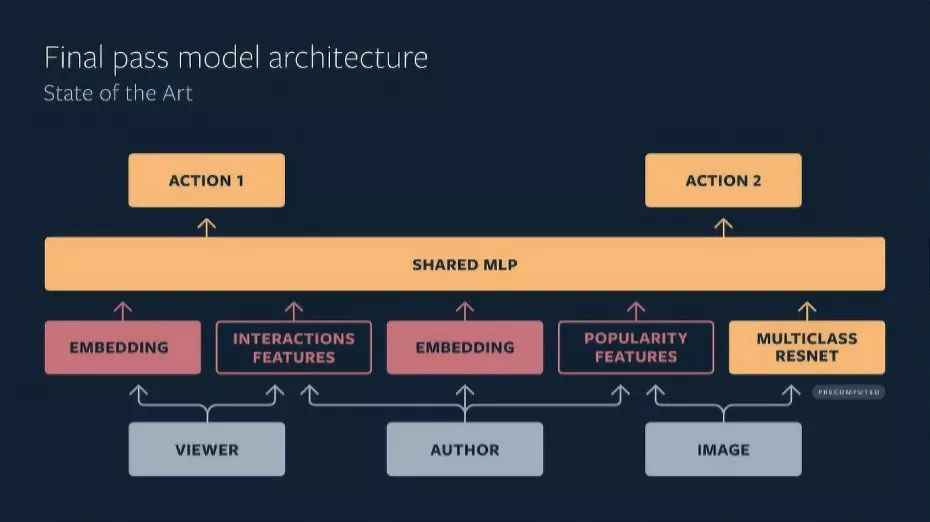
上图:当前最终通过模型架构的图示
有时,首次滤过模型会按照内容排名顺序模仿其他两个阶段的模型。这是个修补程序,实际是一种多任务,多层算法,可以预测人们可能对相关内容做出的行为。
比如点“喜欢”或“收藏”之类的“积极”行为,以及点“不再查看这类内容”等“消极”行为。算法会使用值模型公式进行预测,以获取行为的集中程度,然后加权和确定用户行为的重要程度,比如“保存”帖子和“喜欢”帖子的重要性孰高孰低。
为了在新内容和现有内容之间保持“丰富的平衡”,Explore团队制定了一条规则,以促进内容多样性:添加惩罚因子,这一规则降低了来自同一作者或种子帐户的帖子的排名,因此用户不会在资源管理器中看到来自同一个人或同一种子帐户的多个帖子。
Facebook表示:“我们以代际方式根据每个排名候选内容的终值模型得分,对相关度最高的内容进行排名。”Explore的最激动人心的部分之一是寻找新的有趣方式来帮助社区发现Instagram上最有趣和最相关的内容。我们还在不断继续开发Instagram Explore。无论是添加新格式的媒体,还是不同主题的帖子(比如购物帖),都是很有趣的体验。”
参考链接:https://venturebeat.com/2019/11/25/facebook-details-the-ai-technology-behind-instagram-explore/
 新智元AI朋友圈详细使用教程,8000名AI大玩家和实践者都在这里!
新智元AI朋友圈详细使用教程,8000名AI大玩家和实践者都在这里!