
推荐系统是如何找到相似用户的?
注:误操作将之前的本文删掉了,重发一遍
在《当推荐系统遇上用户画像:你的画像是怎么来的?》一文中,我们介绍了怎么通过TF-IDF的方式得到用户的画像。而在本文中,我们来聊一下在搜索、推荐、计算广告系统中“画像是怎么用的?相似用户是怎么被发现的?”。
在互联网商业应用中,许多广告主在“搜寻潜客”时,都会遇到如难以识别高潜人群、难于平衡成本与规模等问题。而在数字营销的过程中,运营人员或者数据分析同学也是在根据已有的经验,通过用户画像的方式,扩展与历史转化人群相似的人群。比如,通过性别、年龄等筛选出化妆品的受众人群等。显然,这种方式有些粗糙。
那么,有什么方法可以优雅而有理有据的解决这个问题吗?答案是肯定,不然我费劲巴拉的写这篇文章干嘛,躺着刷刷视频不香吗...言归正传,相似人群拓展(Lookalike)的工作机制是基于种子用户画像和社交关系链寻找出相似用户。即,根据种子人群的共有属性进行自动化扩展,以扩大潜在用户覆盖面,提升营销/广告效果。

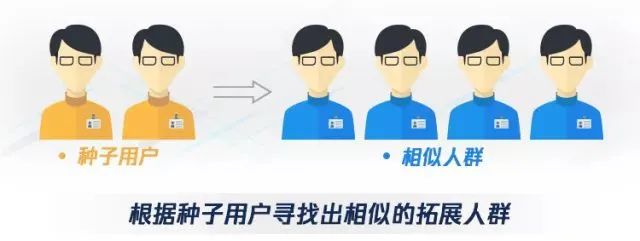
图片引用来自参考资料1
具体来讲,相似人群拓展(Lookalike)是基于种子用户,通过用户画像、算法模型等找到与种子用户更多拥有潜在关联性的拓展技术。Lookalike算法是计算广告中的术语,不是单指某一种算法,而是一类方法的统称,这类方法综合运用多种技术,其目的就是为了实现人群包扩充。
举个广告的栗子,对于一个化妆品类广告主,需要对100万人投放自己的广告,但是根据经验或者画像只有10万的人群包,那么如何选取这100万,同时满足人群量级和转化(盲目选择可能存在无效用户)两个因素,就需要用到Lookalike相似人群拓展技术了。比如,向品牌偏好、消费价格区间匹配的人群进行投放等。
举个数字营销的栗子,对于运营人员,需要将某一个节日活动向100万用户进行短信/Push发送,但根据画像刷选之后,可能发现这波用户已经被其他业务的运营发送过了N多次,最后剩下可以发送的用户寥寥...此时Lookalike相似人群拓展的作用便来了。根据种子人群(已有过的转化人群)的共有属性进行自动化扩展,以扩大潜在用户覆盖面。对于拉新任务来说,谁用谁知道....啊~真香~
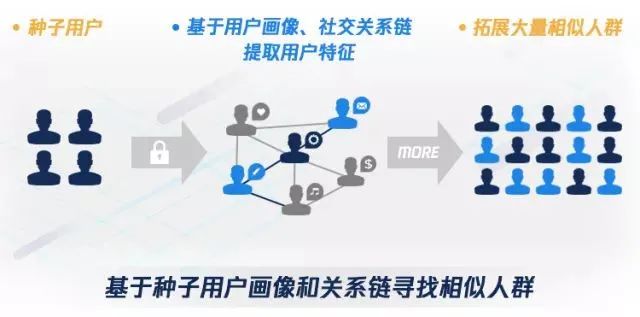
图片引用来自参考资料1
Lookalike相似人群拓展方法主要有以下几种方式,
利用用户画像进行显式人群拓展:根据种子用户的标签(地理、兴趣、行为、品牌偏好等),利用相同标签找到目标人群;
利用机器学习模型进行隐式人群拓展:广告主的种子用户做为正样本,广告平台中有海量的非种子用户,也有大量的广告投放历史数据可以做为负样本,训练机器学习模型,然后用模型对所有候选对象进行筛选;
利用社交图结构的相似人群拓展:核心就是通过Graph Embedding的形式去得到相似的人群。
同时,我们需要注意到的问题是,随着流量不断增大,相似人群的聚焦性也必然逐步降低,寻找目标人群的难度加大,致使非目标人群(无效人群,对转化没有帮助,但是会增加投放成本)的比例也随着流量的增加而增加。而Lookalike技术通过大数据分析和复杂模型学习归纳高质量人群的人口特征,然后在更大的流量范围内,寻找具有类似人口特征的人,从而实现目标的转化。
另外,做任何业务背景的问题,我们都需要关注其背后的可解释性:虽然可以通过一系列的用户画像、机器学习技术拓展了一批用户,但是拓展的途径、人群的行为特征等都需要一个直观的解释。比如扩展的人群在哪些特征或行为上匹配种子用户,而未被拓展的人群,又是怎么样的? 这不仅为拓展提供了帮助,也为badcase溯源问题提供了一套良好的方式方法。


谷歌Similar Audiences
Google的“Similar Audiences”根据用户近期的浏览和下载APP行为,为广告主推荐拓展相似的人群。谷歌广告后台会自动生成与你的网站访问者或现有客户兴趣相似的用户群体,一般情况下,你设置了多少个再营销相似群体列表,就会生成多少个对应的相似人群。

Similar Audience不仅可以帮你查找到与你网站访问者相似的人,并且还能帮你向这些特定人群传递信息,为你带来高质量的潜在用户,甚至直接转化。例如,你开了一家保险公司,并且想推销碎屏保险。通过Remarketing的使用,你可以将之前来过你网站并且查看过碎屏保险的人创建为一个List,然后在这个基础上去寻找相似的受众。
这样一来,新的受众和你之前Remaketing Lists里面的人都是有着相同的行为习惯,兴趣,甚至购买倾向,从而转化率大大提升。
Facebook Lookalike Audiences
Facebook的“Lookalike Audiences”,可以根据Custom Audiences所筛选出的用户名单为参考,再筛选出与其相似的人群,让广告主可以将广告投递给此名单内的用户。

通过Facebook像素插件,来记录客户在你网站的行为,比如,加入购物车但未购买,像素会反馈给你信息,方便后期给客户定向投放广告。
同时相似群体大致有以下情况:
与主页互动,比如点赞,转发,评论主页等,用messenger发消息等等。
视频观看情况,比如说观看你发布的视频时间播放时长等。
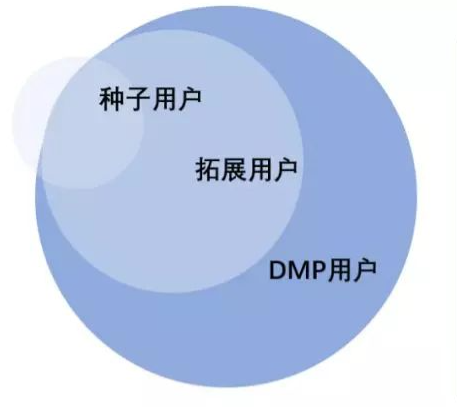
阿里达摩盘DMP
阿里推出达摩盘(DMP)Lookalike 模型根据对店铺或品牌最忠实的那批用户(种子用户),并通过Lookalike 模型找到与这些种子用户相似的人来增加店铺的有效浏览和转化。
腾讯社交Lookalike
腾讯社交广告团队基于种子用户画像和关系链寻找相似用户,即根据种子人群的共有属性进行自动化扩展,以扩大受众覆盖面,提升广告效果。
例如,家庭、社会身份、地位、相关群体等社会因素,文化、次文化等文化因素,以及行为、动机、兴趣等心理因素等都能形成相似人群拓展Lookalike的筛选标准。以社交关系链为基础,腾讯社交广告可以助力广告主寻找相似线索、捕捉高潜客户。

腾讯广告算法大赛2018年的赛题,题目如下:
相似人群拓展(Lookalike)基于广告主提供的一个种子人群(又称为种子包),自动计算出与之相似的人群(称为扩展人群)。本题目将为参赛选手提供几百个种子人群、海量候选人群对应的用户特征,以及种子人群对应的广告特征。出于业务数据安全保证的考虑,所有数据均为脱敏处理后的数据。整个数据集分为训练集和测试集。训练集中标定了人群中属于种子包的用户与不属于种子包的用户(即正负样本)。测试集将检测参赛选手的算法能否准确标定测试集中的用户是否属于相应的种子包。训练集和测试集所对应的种子包完全一致。初赛和复赛所提供的种子包除量级有所不同外,其他的设置均相同。
在特征工程层面,总结一下鱼和jachin的开源方案中的思路如下:
(1)原始onehot特征,比如aid,age,gender等。
(2)向量特征,比如interest1,interest2,topic1,kw1等
(3)向量长度统计特征:interest1,interest2,interest5的长度统计。
(4)uid类的统计特征,uid的出现次数,uid的正样本次数,以及uid与ad特征的组合出现次数,组合正样本次数。
(5)uid的序列特征,比如uid=1时,总共出现了5次,序列为[-1,1,-1,-1,-1]。
(6)组合特征:age与aid的组合,gender与aid的组合,interest1与aid的组合,interest2与aid的组合,topic1与topic2的组合,LBS与kw1的组合。
(7)五大类特征,投放量(click)、投放比例(ratio)、转化率(cvr)、特殊转化率(CV_cvr)、多值长度(length),每类特征基本都做了一维字段和二维组合字段的统计。值得注意的是转化率利用预处理所得的分块标签独立出一个分块验证集不加入统计,其余分块做dropout交叉统计,测试集则用全部训练集数据进行统计。
(8)此外,我们发现一些多值字段的重要性很高,所以利用了lightgbm特征重要性对ct\marriage\interest字段的稀疏编码矩阵进行了提取,提取出排名前20的编码特征与其他单值特征进行类似上述cvr的统计生成CV_cvr的统计,这组特征和cvr的效果几乎相当。
对于没有看过赛题数据的同学,可能会看不懂以上的特征构造,有兴趣的话可以关注炼丹笔记后在后台回复“2018腾讯赛”查看赛题详细介绍。
https://zhuanlan.zhihu.com/p/97786389
https://www.zhihu.com/question/43566578/answer/891387342
https://zhuanlan.zhihu.com/p/46537440
https://zhuanlan.zhihu.com/p/38034501
https://zhuanlan.zhihu.com/p/38341881
https://algo.qq.com/archive.html?