
【Python】红旗超市线下缴电费用户数据分析及可视化(pandas+pyecharts)
一部分用户习惯在红旗超市线下进行缴电费,电力公司希望了解哪些用户喜欢到线下缴费,具体分布在哪里,才能有针对性地宣传掌上电力app引导用户体验更高效的线上缴费方式,提升用户满意度。
需求分析:
首先要拿到红旗超市线下缴费清单数据,对所有数据进行隐私化处理,数据预览如图所示:
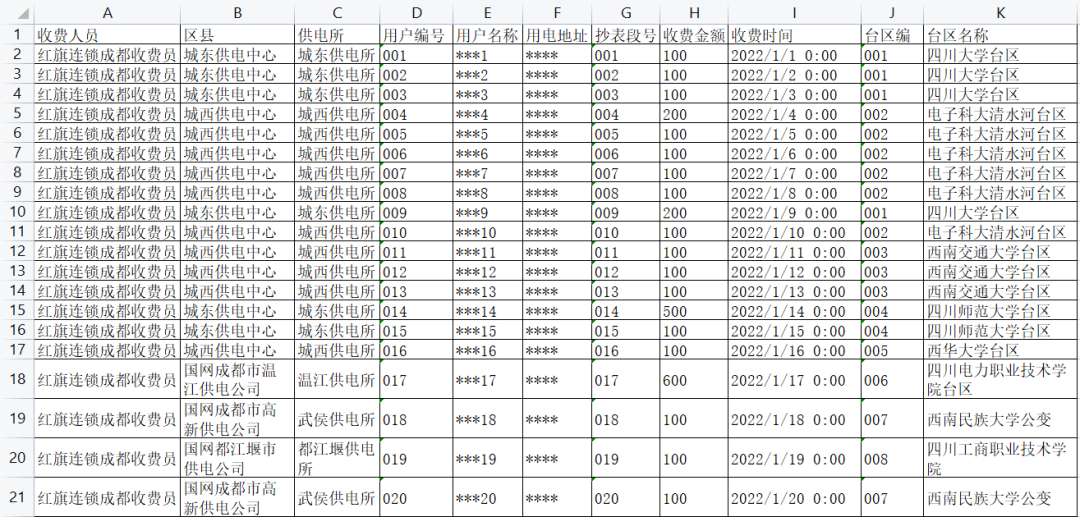
可以看出台区名称为本项目的核心字段,通过台区匹配到经纬度信息,然后利用经纬度信息进行线下缴费热力图展示。
同时可以提供分析报告,分缴费笔数和缴费金额两个维度来分析哪些台区线下缴费更多。
代码分析:
数据分析报告比较简单,可以直接读入数据,利用pandas来进行分析,最终将结果文件输出,我们先实现这部分的代码。
真实的缴费数据量级是十万级别,但台区会有很多重复,也就是家住在同一小区的,我们先看看台区大概有多少。
import pandas as pddata = pd.read_excel(r"./成都红旗成都收费员收费记录/红旗连锁成都收费员-2022年1月交费数据.xlsx")result=data["台区名称"].unique().tolist()print(len(result))
结果量级变为了万级,也就是我们要匹配这几万户的经纬度。先不管经纬度,我们用已有信息从缴费笔数和缴费金额两个维度进行分析。
读取数据:
import pandas as pdtb=pd.DataFrame(pd.read_excel(r"红旗连锁成都收费员-2022年1月交费数据.xlsx"))
对数据进行分组,求各台区收费总金额和缴费次数:
gp=tb.groupby(["区县","台区名称"])d0=gp.sum().loc[:,["收费金额"]]d1=gp.size()d=pd.concat([d0,d1],axis=1)d.columns=["总金额","缴费次数"]
对数据分别按总金额和缴费次数进行排序输出:
d_1=d.sort_values(by="总金额",ascending=False)d_1.to_excel("统计信息_金额.xlsx")d_2=d.sort_values(by="缴费次数",ascending=False)d_2.to_excel("统计信息_缴费次数.xlsx")
此时我们就获得了一个简易的分析报告:
(统计信息_金额.xlsx)
| 区县 | 台区名称 | 总金额 | 缴费次数 |
| 城西供电中心 | 电子科大清水河台区 | 700 | 6 |
| 国网成都市温江供电公司 | 四川电力职业技术学院台区 | 600 | 1 |
| 城东供电中心 | 四川师范大学台区 | 600 | 2 |
| 四川大学台区 | 500 | 4 | |
| 城西供电中心 | 西南交通大学台区 | 300 | 3 |
| 国网成都市高新供电公司 | 西南民族大学公变 | 200 | 2 |
| 国网都江堰市供电公司 | 四川工商职业技术学院 | 100 | 1 |
| 城西供电中心 | 西华大学台区 | 100 | 1 |
(统计信息_缴费次数.xlsx)
| 区县 | 台区名称 | 总金额 | 缴费次数 |
| 城西供电中心 | 电子科大清水河台区 | 700 | 6 |
| 城东供电中心 | 四川大学台区 | 500 | 4 |
| 城西供电中心 | 西南交通大学台区 | 300 | 3 |
| 国网成都市高新供电公司 | 西南民族大学公变 | 200 | 2 |
| 城东供电中心 | 四川师范大学台区 | 600 | 2 |
| 国网成都市温江供电公司 | 四川电力职业技术学院台区 | 600 | 1 |
| 国网都江堰市供电公司 | 四川工商职业技术学院 | 100 | 1 |
| 城西供电中心 | 西华大学台区 | 100 | 1 |
分析报告显示:需要重点去宣传的小区是电子科大、四川大学、西南交大,因为他们线下缴费用户多,还有四川电力职业技术学院和四川师范大学,虽然用户不多,但是他们交的电费多。
表格看起来始终不够直观,那么可否进行热力图显示,当然可以,下面我们利用pyecharts进行热力图展示。
要进行热力图展示,此时我们还缺了一项数据,那就是台区的经纬度,正常情况下我们从数据中台中获取所有台区的经纬度信息进行匹配,由于台区经纬度信息同样属于保密数据,获取需要审批,此项目我们从另外一个渠道获取经纬度信息,那就是百度地图开放平台。
https://lbsyun.baidu.com/

导入本项目需要的包:
from urllib.request import quoteimport requestsimport pandas as pdimport numpy as npimport jsonpd.set_option('display.max_columns',None)
先写一个能够将中文字符串转化为经纬度的函数:
def getlnglat(address):url = 'http://api.map.baidu.com/geocoding/v3/'output = 'json'ak = '在百度地图开放平台申请的ak'address = quote(address) # 由于本文地址变量为中文,为防止乱码,先用quote进行编码uri = url + '?' + 'address=' + address + '&output=' + output + '&ak=' + ak +'&callback=showLocation%20'+'//GET%E8%AF%B7%E6%B1%82'res=requests.get(uri).texttemp = json.loads(res) # 将字符串转化为jsonlat = temp['result']['location']['lat']lng = temp['result']['location']['lng']return lng,lat # 纬度 latitude,经度 longitude
再写一个能够从区县字符串中扣出对我们定位有用信息的函数:
def renew_quxian(x):if "供电中心" in x:return x.split("供")[0]if "供电公司" in x:temp = x.split("网")[1]if "成都市" in temp:temp1 = temp.split("供")[0]return temp1.split("市")[1]else:return temp.split("供")[0]
读入数据,利用所写的 renew_quxian函数构造一个新的字段——中文地址:
data["中文地址"]="成都市"+data["区县"].apply(renew_quxian)+data["台区名称"]如果不构造这个中文地址字段,直接用台区名称,那么很有可能就定位到北上广深的同名小区去了,所以尽量利用成都市和区县信息替百度缩小搜索范围,当然也是为了提升我们定位的精确度。
假如有几十万的台区数据,里面又有重复的台区信息,总不能调用百度api几十万次吧,没有那么多额度,就算是认证用户,一天也只能查30w次。

根据台区信息进行去重操作:
data_unique = data.iloc[data.groupby(['台区名称']).apply(lambda x: x['用户编号'].idxmax())]
去重后新增经纬度字段:
data_unique["经纬度"]=data_unique["中文地址"].apply(getlnglat)r=data_unique.loc[:,["台区名称","经纬度"]]
根据台区名称和经纬度组成的键值对来构建city_coordinates.json文件:
for i in r.iterrows():k=i[1]['台区名称']v=i[1]['经纬度']mp[k]=vf=open(r"city_coordinates.json", 'r',encoding='utf-8')fs=str(f.read())f.close()old=json.loads(fs) #json转objold.update(mp) #把从excel里读到的更新进去f=open(r"city_coordinates.json",'w',encoding='utf-8')json.dump(old,f,ensure_ascii=False)f.close()
city_coordinates.json结构如下图所示:
{"四川大学台区": [104.08399190311378, 30.63014203788181], "电子科大清水河台区": [103.93740389474014, 30.756035188715344], "西南交通大学台区": [103.99321381946406, 30.77039889704779], "四川师范大学台区": [104.12869113613753, 30.619258186581966], "西华大学台区": [104.07428849682555, 30.640677198288525], "四川电力职业技术学院台区": [103.84530242741315, 30.726613592027057], "西南民族大学公变": [104.02072415621548, 30.626048550861352], "四川工商职业技术学院": [103.70236701907363, 30.918967871107483]}将city_coordinates.json文件替换至C:\ProgramData\Anaconda3\Lib\site-packages\pyecharts\datasets的原文件处,为在地图上显示做准备。
为了显示热力图要计算每个台区出现的次数,其实前面已经统计出来了,这里我们展示另外一种算法:
def getlistnum(li):set1 = set(li)dict1 = {}for item in set1:dict1.update({item:li.count(item)})return dict1total = {}total = getlistnum(data["台区名称"].tolist())
由于热力图展示的时候取值可以从0到100,100最红,0基本看不到,所以我们将最小值映射到50,最大值映射到100,我们在打绩效的时候其实也是这一套操作:
def fun(li):zhi=[]for i in li:scale = (i - min(li)) / (max(li) - min(li))zhi.append(50 + 50 * scale)return zhi
最后一步就是利用pyecharts画热力图:
from pyecharts.charts import BMapfrom pyecharts import options as optsdef heatmap_heatmap() -> BMap:c = (BMap().add_schema(baidu_ak="在百度地图开放平台申请的ak", center=[104.07231,30.663467]).add("",[list(z) for z in zip(total.keys(), fun(total.values()))],type_="heatmap",label_opts=opts.LabelOpts(formatter="{b}"),).set_global_opts(title_opts=opts.TitleOpts(title="",title_textstyle_opts = (opts.TextStyleOpts(color='red', font_size=50))),legend_opts=opts.LegendOpts(pos_left='80%',pos_top='20',textstyle_opts=opts.TextStyleOpts(color='black', font_size=30),),tooltip_opts=opts.TooltipOpts(textstyle_opts=opts.TextStyleOpts(font_size=30),# background_color='green',border_color='black',border_width=3),visualmap_opts=opts.VisualMapOpts()).render("红旗地图.html"))return cheatmap_heatmap()
画出的热力图是一个html文件,可以全方位展示线下红旗缴电费用户的状况:
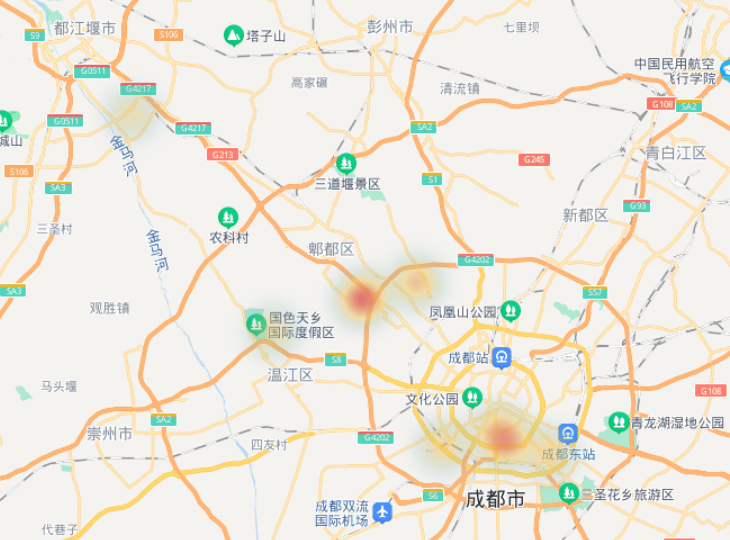
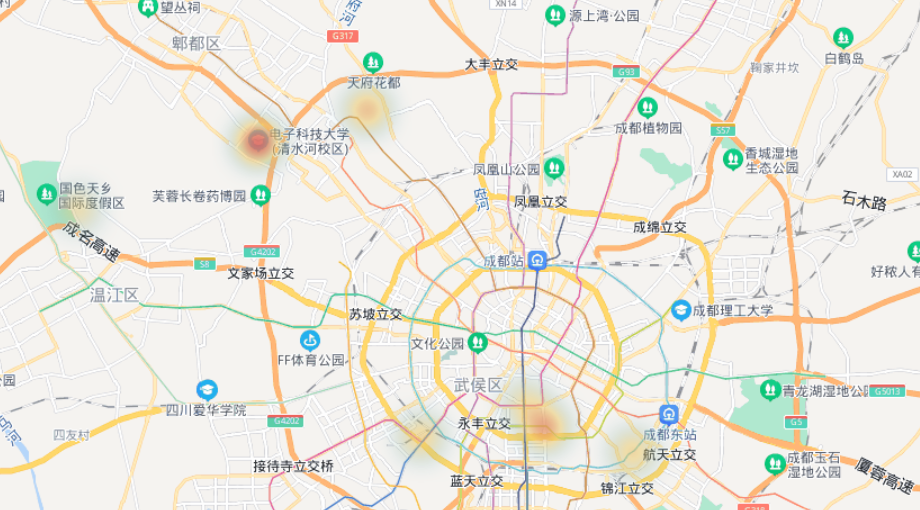
由于数据是我伪造的,这里的效果其实是展示的成都市高校的情况,将数据换成真实业务数据,就可以得到我们想要的结果。
总结分析:
数据量超过百万级别,用python和pandas也迷糊,excel是不可能带得动的,所以建设数据库,学会利用sql取数是必要的也是必须的。
常用信息尽量从自己的数据仓库或数据中台获取,大量数据从外部获取会存在非常大的不确定因素,说给你把api封了,就给你封了。
积累到所有台区数据后,可以分批次从百度api获取数据存入数据库,以后用就方便了,存入自己数据库才是王道
如果能从数据中台获取业务系统里面的经纬度信息就更好,不过业务系统数据库中存入的经纬度信息不一定能够匹配百度地图进行精确显示
建设好公司数据仓库后,利用业务需求+数据分析的方式实现业数融合,利用大数据指导业务
往期精彩回顾 适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: