
3个常考的SQL数据分析题(含数据和代码)
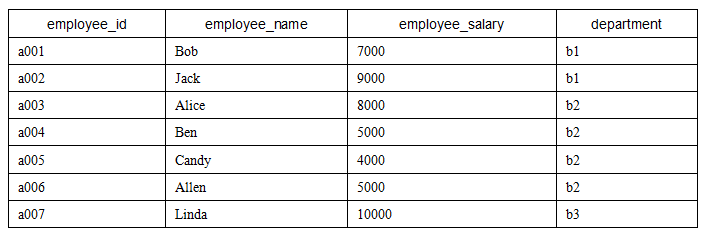

DROP TABLE IF EXISTS employee;
CREATE TABLE employee(
employee_id VARCHAR(8),
employee_name VARCHAR(8),
employee_salary INT(8),
department VARCHAR(8)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
employee (employee_id,employee_name,employee_salary,department)
VALUE ('a001','Bob',7000,'b1')
,('a002','Jack',9000,'b1')
,('a003','Alice',8000,'b2')
,('a004','Ben',5000,'b2')
,('a005','Candy',4000,'b2')
,('a006','Allen',5000,'b2')
,('a007','Linda',10000,'b3');
DROP TABLE IF EXISTS department;
CREATE TABLE department(
department_id VARCHAR(8),
department_name VARCHAR(8)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
department (department_id,department_name)
VALUE ('b1','Sales')
,('b2','IT')
,('b3','Product');
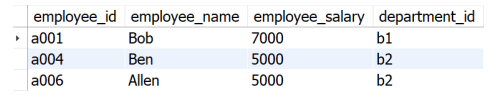
SELECT a.employee_id
,a.employee_name
,a.employee_salary
,b.department_id
FROM
(
SELECT *
,RANK() OVER (PARTITION BY department ORDER BY employee_salary DESC) AS ranking
FROM employee
) AS a
INNER JOIN department AS b
ON a.department = b.department_id
WHERE a.ranking = 2;
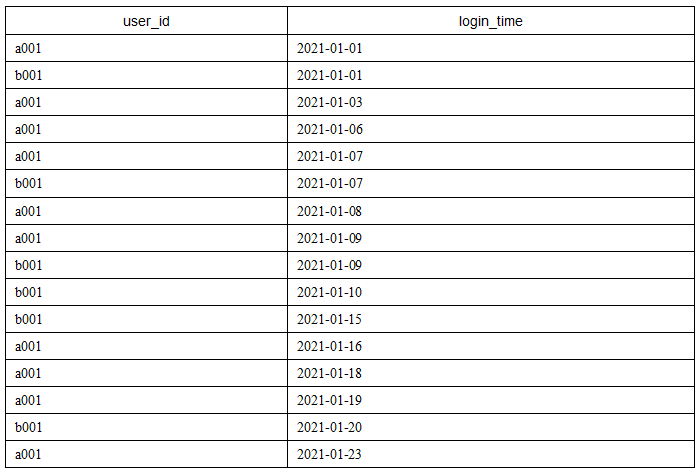 数据导入的代码如下:
数据导入的代码如下:DROP TABLE IF EXISTS login_info;
CREATE TABLE login_info(
user_id VARCHAR(8),
login_time DATE
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
login_info (user_id,login_time)
VALUE ('a001','2021-01-01')
,('b001','2021-01-01')
,('a001','2021-01-03')
,('a001','2021-01-06')
,('a001','2021-01-07')
,('b001','2021-01-07')
,('a001','2021-01-08')
,('a001','2021-01-09')
,('b001','2021-01-09')
,('b001','2021-01-10')
,('b001','2021-01-15')
,('a001','2021-01-16')
,('a001','2021-01-18')
,('a001','2021-01-19')
,('b001','2021-01-20')
,('a001','2021-01-23');
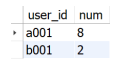
SELECT user_id
,login_time
,LEAD(login_time,1) OVER (PARTITION BY user_id ORDER BY login_time) AS next_login_time
FROM login_info;
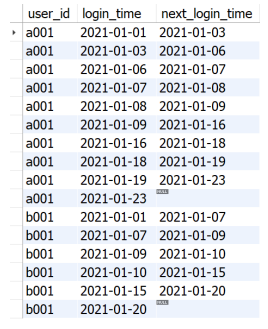
SELECT a.user_id
,COUNT(*) AS num
FROM
(
SELECT user_id
,login_time
,LEAD(login_time,1) OVER (PARTITION BY user_id ORDER BY login_time) AS next_login_time
FROM login_info
) AS a
WHERE TIMESTAMPDIFF(DAY, login_time, next_login_time) < 5
GROUP BY user_id;
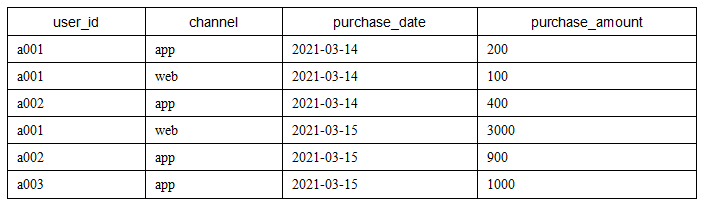
DROP TABLE IF EXISTS purchase_channel;
CREATE TABLE purchase_channel(
user_id VARCHAR(8),
channel VARCHAR(8),
purchase_date DATE,
purchase_amount INT(8)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8;
INSERT INTO
purchase_channel (user_id,channel,purchase_date,purchase_amount)
VALUE ('a001','app','2021-03-14',200)
,('a001','web','2021-03-14',100)
,('a002','app','2021-03-14',400)
,('a001','web','2021-03-15',3000)
,('a002','app','2021-03-15',900)
,('a003','app','2021-03-15',1000);
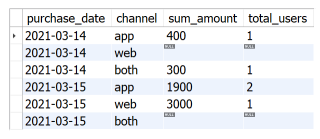
SELECT purchase_date
,channel
,SUM(sum_amount) sum_amount
,SUM(total_users) total_users
FROM
(
SELECT purchase_date
,MIN(channel) channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date
,user_id
HAVING COUNT(DISTINCT channel) = 1 UNION
SELECT purchase_date
,'both' channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date
,user_id
HAVING COUNT(DISTINCT channel) > 1
) c
GROUP BY purchase_date
,channel;
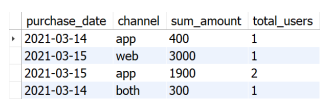
SELECT t1.purchase_date
,t1.channel
,t2.sum_amount
,t2.total_users
FROM
(
SELECT DISTINCT a.purchase_date
,b.channel
FROM purchase_channel a,
(
SELECT "app" AS channel
UNION
SELECT "web" AS channel
UNION
SELECT "both" AS channel
) b
) t1
LEFT JOIN
(
SELECT
purchase_date,
channel,
SUM(sum_amount) sum_amount,
SUM(total_users) total_users
FROM (
SELECT purchase_date
,MIN(channel) channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date,user_id
HAVING COUNT(DISTINCT channel) = 1
UNION
SELECT purchase_date
,'both' channel
,SUM(purchase_amount) sum_amount
,COUNT(DISTINCT user_id) total_users
FROM purchase_channel
GROUP BY purchase_date,user_id
HAVING COUNT(DISTINCT channel) > 1
)c GROUP BY purchase_date, channel
) t2
ON t1.purchase_date = t2.purchase_date AND t1.channel = t2.channel;


没有基础可以学吗?
可以,本书从环境搭建开始,从基础入门到进阶,然后通过题目实战提升SQL能力,是一本关于SQL 数据分析的实战手册。
本书对比市面上大部分SQL书籍的特色是什么?
将数据分析挖掘中所需的SQL能力抽出来专门写,不会涉及很多不常用的功能语法,由浅入深,并配套大量练习题(可作为求职笔试面试的练习题),每个练习题都配有数据导入、解题思路和参考答案。练习题会结合当前数据分析很多场景需求来编制,例如“活跃用户分析”、“连续登录用户分析”、“社区团购行为分析”、“商品销量同环比”。
本书适合数据分析相关岗位求职备考准备么?
很适合,本书展现了数据分析工作的日常内容,给出了数据分析岗位的工作技能要求,然后讲述了数据分析笔试与面试中对SQL 的考查知识点。通过3种难度的题目练习,能提升求职能力并达到初级数据分析挖掘岗位对SQL的能力要求。
本书的适合什么样的读者?
数据分析与数据开发求职者和从业者
计算机科学与技术、统计学、数学、大数据、人工智能、数据科学相关专业的师生
对数据分析和SQL感兴趣人群
转行做数据分析与数据开发的人员
大家如果经常买书都会知道,新书刚出版上市是没有什么折扣的。
原价89元,现在京东和当当都有优惠(下方当当链接目前52元可拿下)。
大家可以点击下方链接或者点击阅读原文直接购买。
助力大家提升SQL数据分析能力!
评论