
【数据分析】用于数据分析的8个SQL技术
编译 | VK
来源 | Analytics Vidhya
概述
SQL是任何从事分析或数据科学的人都必须知道的语言
这里有8种用于数据分析的SQL技术,任何数据科学专业人士都会喜欢使用它
介绍
SQL是数据科学专业人员军械库中的一个关键齿轮。这是经验之谈,如果你还没有学会SQL,你就不能指望在分析或数据科学领域取得成功。
为什么SQL如此重要?
随着我们进入新的十年,我们生产和消费数据的速度正在一天一天的飙升。
为了根据数据做出明智的决策,世界各地的组织都在聘请数据专业人士,如业务分析师和数据科学家,从海量的数据宝库中挖掘信息。
其中一个最重要的工具就是SQL!

结构化查询语言(SQL)已经存在了几十年。它是一种编程语言,用于管理关系数据库中保存的数据。
世界各地的大多数大公司都在使用SQL。数据分析员可以使用SQL访问、读取、操作和分析数据库中存储的数据,并生成有用的信息,以推动明智的决策过程。
在本文中,我将讨论8种SQL技术,这些技术将使你为任何高级数据分析问题做好准备。请记住,本文假设你对SQL有非常基本的了解。
目录
了解数据集
SQL技术1:计算行和项
SQL技术2:聚合函数
SQL技术3:极值识别
SQL技术4:数据切片
SQL技术5:限制数据
SQL技术6:数据排序
SQL技术7:过滤模式
SQL技术8:分组、汇总数据和分组过滤
了解数据集
学习数据分析的最好方法是什么?通过在一个数据集上执行它!
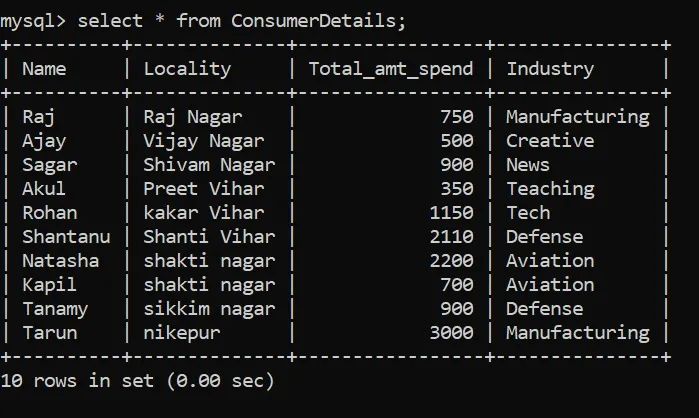
为此,我创建了一个零售商店的虚拟数据集。客户数据表由ConsumerDetails表示。
我们的数据集由以下列组成:
「Name」 –消费者的名称 「Locality」 –客户所在地 「Total_amt_spend」 –消费者在商店中花费的总金额 「Industry」 –它表示消费者所属的行业
注:我们将使用MySQL5.7进行实验。你可以从这里下载
https://dev.mysql.com/downloads/mysql/5.7.html
SQL技术1–计算行和项
Count函数
我们将从最简单的查询开始分析,即计算表中的行数。我们将使用函数COUNT()来完成此操作。
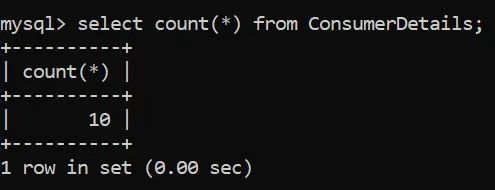
太好了!现在我们知道表中的行数是10。在一个小的测试数据集上使用这个函数似乎没用。但是当你的行数达到数百万时,它会有很大的帮助!
Distinct函数
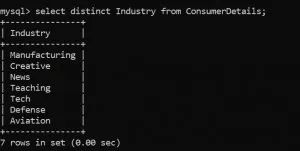
很多时候,我们的数据表中充满了重复的值。为了获得独一的值,我们使用了不同的函数。
在我们的数据集中,我们如何找到客户所属的行业?
你猜对了。我们可以通过使用DISTINCT函数来实现这一点。
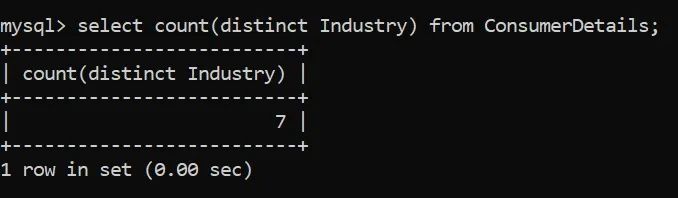
你甚至可以使用count和distinct一起计算唯一行的数量。你可以参考以下查询:
SQL技术2–聚合函数
聚合函数是任何数据分析的基础。它们为我们提供了数据集的概述。我们将讨论的一些函数是–SUM()、AVG()和STDDEV()。
SUM函数
我们使用SUM()函数计算表中数值列的和。
我们来计算一下每位顾客的消费总额:
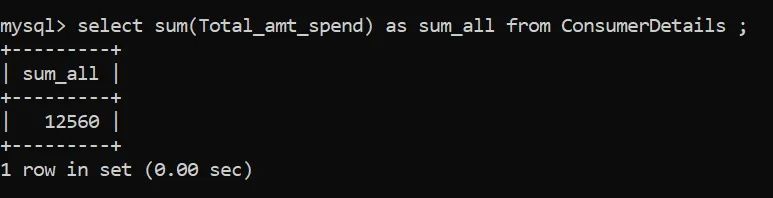
在上面的例子中,sum_all是存储sum值的变量。消费者的消费总额是12560卢比。
AVG函数
AVG()函数计算平均值。让我们找出消费者对我们零售店的平均支出:
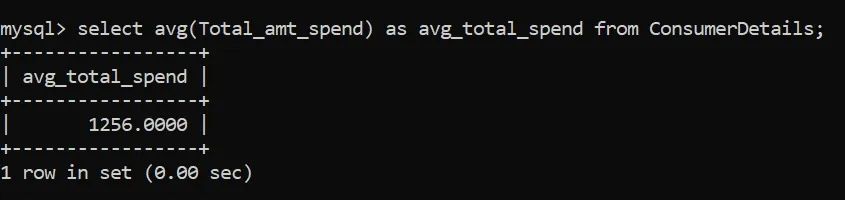
顾客在零售店的平均消费额为1256卢比。
STDDEV函数
如果你查看了数据集,然后查看了消费者的平均支出值,你会发现有些东西遗漏了。平均值并不能提供完整的理解,所以让我们找到另一个重要的指标——标准差。函数为STDDEV()。
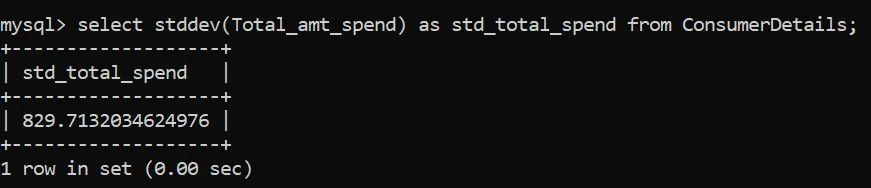
标准差为829.7,这意味着消费者的支出之间存在很大差距!
SQL技术3–极值识别
下一种类型的分析是确定极值,这将有助于你更好地理解数据。
Max函数
可以使用MAX()函数标识最大数值。让我们看看如何应用它:
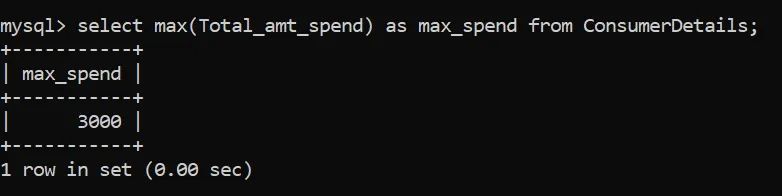
消费者在零售店的最高消费额是3000卢比。
Min函数
与max函数类似,我们有MIN()函数来标识给定列中的最小数值:
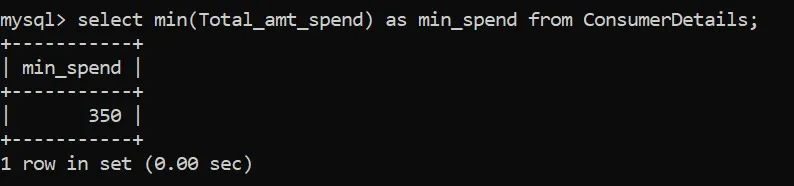
零售店消费者的最低消费额是350卢比。
SQL技术4–数据切片
现在,让我们关注数据分析中最重要的部分之一——数据切片。分析的这一部分将构成高级查询的基础,并帮助你根据某种条件检索数据。
假设零售店希望找到来自某个地方的客户,特别是Shakti Nagar和Shanti Vihar地区。
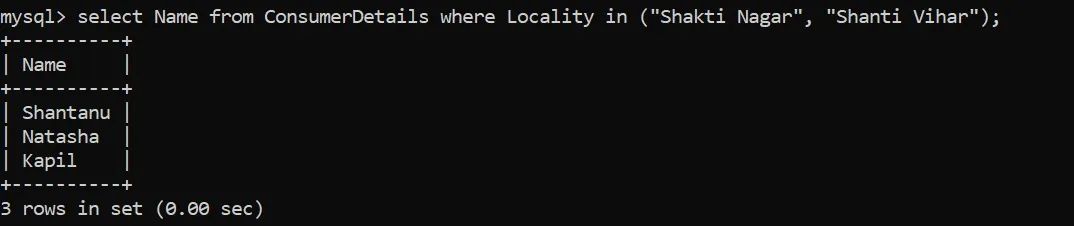
太好了,我们有3个客户!我们使用WHERE子句根据消费者应该居住在当地的条件筛选出数据—Shakti Nagar和Shanti Vihar。
我没有在这里使用OR条件。相反,我使用了IN运算符,它允许我们在WHERE子句中指定多个值。
我们需要找到那些居住在特定地区(Shakti Nagar和Shanti Vihar)且消费金额超过2000卢比的客户。

在我们的数据集中,只有Shantanu和Natasha满足这些条件。由于这两个条件都需要满足,所以和条件更适合这里。让我们看看另一个例子。
这一次,零售店希望找回所有消费在1000卢比到2000卢比之间的消费者,以便推出特别的营销优惠。
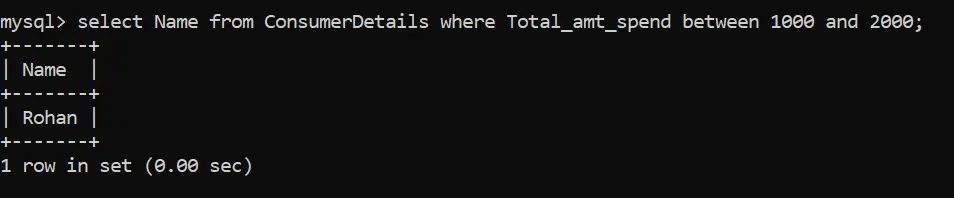
另一种写同样语句的方法是:

只有Rohan在满足这个标准!
太好了!我们已经走到一半了。让我们在迄今所获得的知识基础上再接再厉。
SQL技术5–限制数据
Limit
假设我们要查看由数百万条记录组成的数据表。我们不能直接使用SELECT语句,因为这会将整个表转储到我们的屏幕上,这既麻烦又计算密集。我们可以使用Limit:
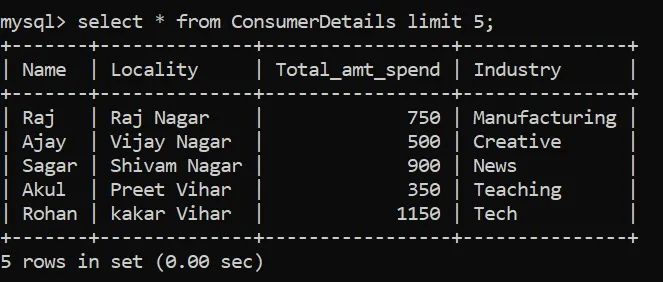
上面的SQL命令帮助我们显示表的前5行。
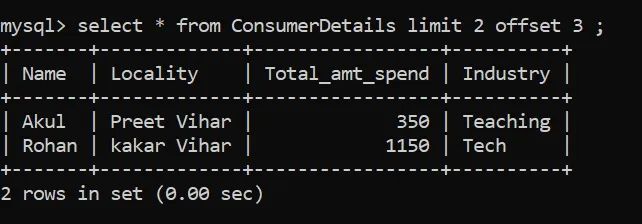
OFFSET
如果你只想选择第四行和第五行,你会怎么做?我们将使用OFFSET。OFFSET将跳过指定的行数。让我们看看它是如何工作的:
SQL技术6–数据排序
对数据进行分类有助于我们对数据进行观察。我们可以使用关键字ORDER by来执行排序过程。
ORDER BY
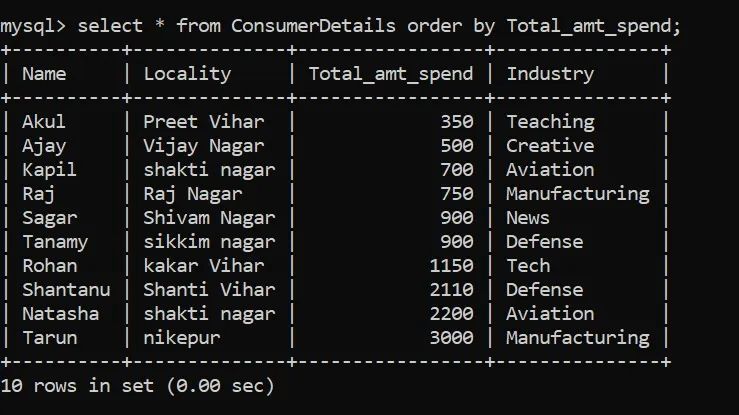
关键字可用于按升序或降序对数据进行排序。默认情况下,ORDER BY关键字按升序对数据排序。
让我们看一个示例,其中我们根据Total_amt_spend列按升序对数据进行排序:
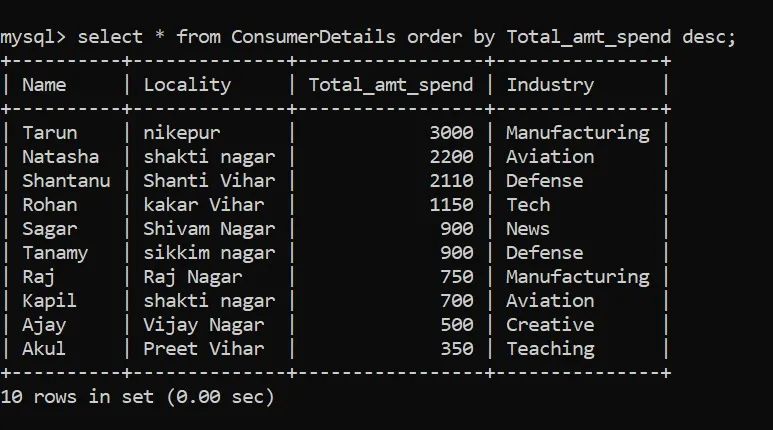
要将数据集按降序排序,可以按照以下命令进行操作:
SQL技术7–过滤模式
在前面的部分中,我们学习了如何根据一个或多个条件过滤数据。在这里,我们将学习匹配指定的模式列。为此,我们将首先了解LIKE运算符和通配符。
LIKE
LIKE在WHERE子句中用于搜索列中的指定模式。
通配符
通配符用于替换字符串中的一个或多个字符。它们与LIKE运算符一起使用。最常见的两个通配符是:
「%」,表示0个或更多个字符
「_」,它代表一个字符
在我们的虚拟零售数据集中,假设我们想要所有以“Nagar”结尾的地区。花点时间来理解问题陈述,并思考如何解决这个问题。
让我们试着把这个问题分解一下。我们需要以“Nagar”结尾的所有位置,并且在这个特定字符串之前可以有任意数量的字符。因此,我们可以在“Nagar”之前使用“%”通配符:
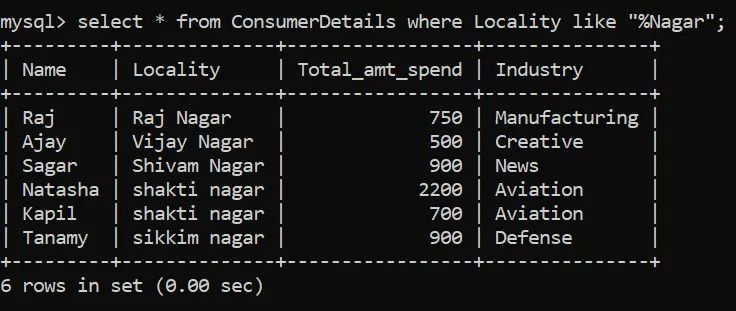
太棒了,我们有6个地方以这个名字结尾。注意,我们使用LIKE操作符来执行模式匹配。
接下来,我们将尝试解决另一个基于模式的问题。我们需要第二个字符在他们各自的名字中有“a”的消费者的名字。
再一次,我建议你花点时间来理解这个问题,并想出一个解决它的逻辑。
让我们把问题分解一下。这里,第二个字符需要是“a”。第一个字符可以是任何字符,所以我们用通配符_。
在第二个字符之后,可以有任意数量的字符,因此我们将这些字符替换为通配符“%”。最终的模式匹配如下所示:
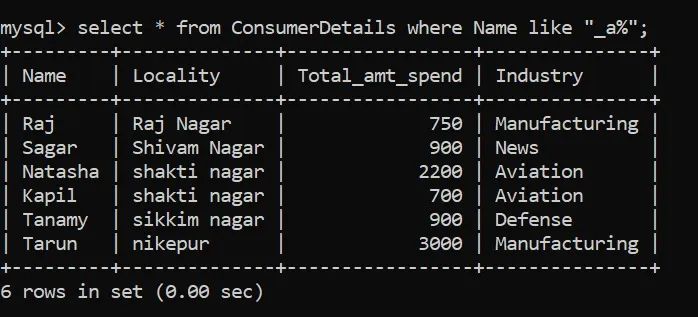
我们有6个人满足了这个条件。
SQL技术8–分组、汇总数据和分组筛选
我们终于到了SQL中最强大的分析工具之一,使用GROUP BY语句对数据进行分组。
这个语句最有用的应用是寻找分类变量的分布。这是通过使用GROUPBY语句和聚合函数(如–COUNT、SUM、AVG等)来完成的。
让我们用一个问题陈述来更好地理解这一点。零售商店希望找到与其所属行业对应的客户数量:
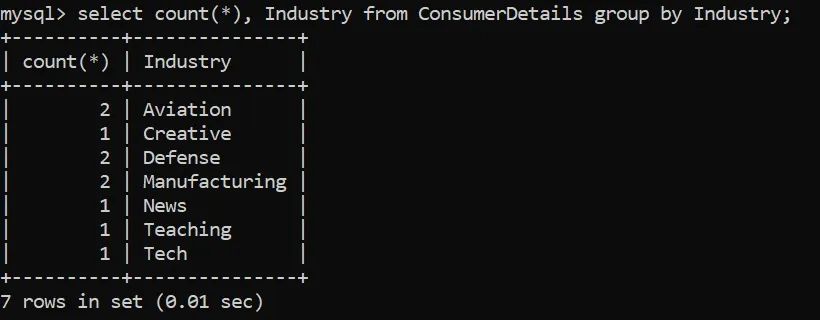
我们注意到,属于不同行业的客户数量或多或少是相同的。因此,让我们改成根据客户所属行业分组,计算出他们的支出总额:
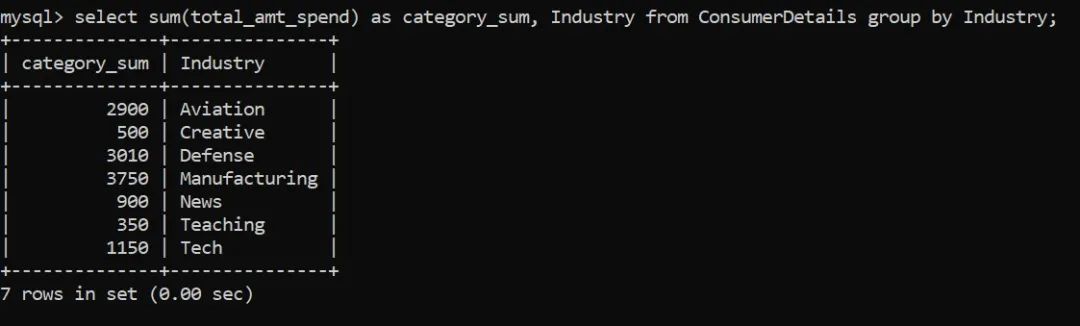
我们可以观察到,消费金额最大的是属于制造业的客户。这看起来有点容易,对吧?让我们继续更改要求,让它变得更复杂。
现在,零售商希望找到总销售额大于2500的行业。为了解决这个问题,我们将再次根据行业数据进行分组,然后使用HAVING子句。
HAVING
HAVING子句与WHERE子句类似,但仅用于过滤分组的数据。记住,它总是在group by语句之后。

我们只有3个类别满足条件-航空,国防和制造业。但为了更清楚,我还将添加ORDER BY关键字,使其更直观:

结尾
我很高兴你做到了。这些是SQL中所有数据分析查询的构建知识。你还可以使用这些基础知识来进行高级查询。在本文中,我使用了MySQL 5.7来建立示例。
我希望这些SQL查询能够帮助你分析复杂数据的日常生活。
原文链接:https://www.analyticsvidhya.com/blog/2020/07/8-sql-techniques-data-analysis-analytics-data-science/
看到这里,说明你喜欢这篇文章,请点击「在看」或顺手「转发」「点赞」。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群请扫码进群: