我常遇到的三种技术债务:代码、数据和架构
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
在软件工程中,我们经常面临各种权衡取舍,用长期来看最佳的技术选项换取短期内的速度提升。借用金融术语的一种常见说法是把它叫做承担技术债务。
这篇文章中我不会涉及意外和故意的技术债务,也不会给出什么决策框架。那都是单独的主题,而且要具体情况具体分析。
本文要讲的是一个思维框架,我认为这个框架在不同的团队、代码库和系统中都能适用。我将技术债务分为三类:代码、数据和架构。现在我们通过一些例子来具体回顾这几个类别。
这可能是最常见的,也是大家第一个能想到的。这种债务的形式是我们提交的次优代码。一些例子包括:
先复制粘贴一些代码,稍后重构
编写一个可以完成所有事情的大函数
导入一个巨大的库,却只是为了一个很小的功能需求
扩展函数签名以管理边缘情况
大家都可能见过很多这样的代码:
# This is a hack: @TODO FIXMEdef barbaric_function(param1, param2, param3, param4, special_case=None):# This code is very brittle but we need to shipif special_case:import something.pretty.badbad.hax0r(special_case)...
代码技术债务往往最容易被提到,因为在审查他人的代码或粗略浏览代码库时很容易看出这些债务。它是 3 大类中最“可见”的。它往往也很容易修复,因为你可以通过测试和重构来包装你的逻辑,在一次代码更改中搞定修复,或者通过几次外科手术来处理(TDD 为充斥着技术债务的代码库创造了很多奇迹)。无论是用哪种方式修复,要处理的都只是代码,所以这一块技术债承担和偿还起来都没有太大的负担。很多时候,当人们谈到“技术债务”时,他们实际上是在考虑这个分类的问题。但我希望情况不是这样,因为这个类别是危害最小的!
这是软件项目承担的一种不太常见但非常关键的债务形式。它与系统架构、运行时选择、接口、服务设计、存储决策等设计考虑相关。
一些例子:
这个进程在什么运行时中运行?
我们如何在进程 / 服务之间传递消息?
我们是采用单体策略、共享库还是面向微服务的架构?
这应该是离线作业还是在线服务?
这些 worker 应该是无状态还是有状态?
我们应该采用轮询模型(pull)、触发器(push)还是事件驱动模型 (pub/sub)?
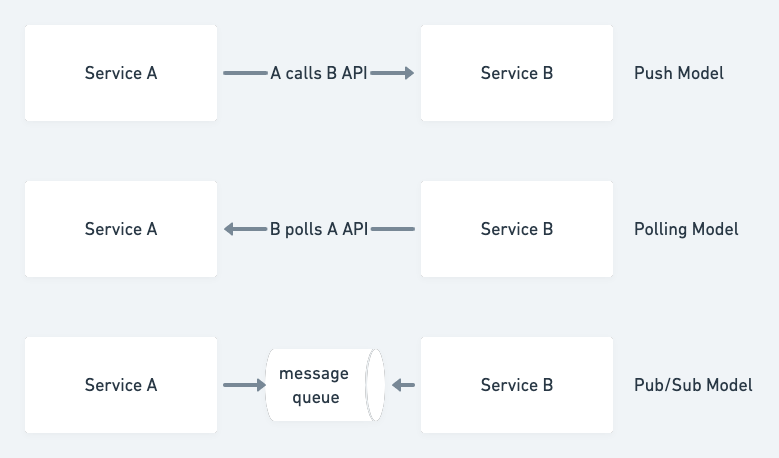
这些架构决策可以将项目推向完全不同的方向。以上面的例子为例,在流量平稳且 QPS 较低的情况下使用中间发布 / 订阅队列,可能会以维护和调试的形式增加架构债务。但是,如果流量非常陡峭并且服务 B 无法处理峰值负载,那么推送模型将是这一领域产生债务最多的。
架构债务的偿还通常跨越更长的时间周期。长反馈循环更难学习,而且这种架构债务很容易被忽略。SWE 在硅谷的平均任期为 18 个月,但发现早期架构决策的问题可能需要更长的时间!当优步发展到 1000 个微服务和 2000 位工程师时发生的 事情 就是一个完美的例子。走微服务路线确实在短期内提高了他们的速度,但后来这条路线为整个系统带来了可调试性和延迟方面的债务。
架构债务的成本可能很高(糟糕的 on-call 计划,系统僵化且难以推理,缺乏可调试性),并且与代码债务相比更难偿还。深入分析你们正在应对的系统,并了解项目做出了哪些影响服务特性(可维护性、灵活性、可靠性等)的关键决策(不管这些决策明确与否),在任何时候都是非常有价值的行动。其中一些决策可能是故意为之的,并带来了有趣的后果。
最后,即使人们在试图避免架构技术债务时,这些债务也可能会偷偷增加。过早的优化通常会导致我们最终产生债务。一个例子是为 10k QPS 设计的一个 Web 服务,最后只用来应对 1/100 的流量。许多架构决策可能会各自冲突,而且很容易因为不必要的复杂性而产生债务。
数据建模似乎不像以前那么常见了。曾经有一段时间,大多数工程师都要定期从事数据建模工作。现在人们通常将其委托给一个特殊的团队(“用户服务来处理”),或者使用一些允许他们完全忽略这类问题的工具(在这方面的例子有 graphQL、mongoDB)。
数据建模的影响在短期和长期范围都存在。从短期来看,在模型和类型上花费大量时间会让人感觉成本很高,因此人们很容易选择一些非常灵活的东西来优化早期迭代和灵活性。然而,我已经看到这是错误的方式(把所有内容都放在一个 JSON 中,并在客户端上进行所有过滤工作),最后我们会在回填、数据完整性修复和重构方面多做很多工作。良好的数据建模对代码和系统架构都有正面影响,也就是说这 3 类技术债务其实是相互关联的。然而,数据是最难做对的事情之一,也是最难改变的事情之一。所以数据技术债务应该被认真对待、积极识别、正确处理。实际上,当你想要更改你的数据模型时,这种更改的依赖关系图通常是非常模糊的。它需要涉及代码更改、数据库迁移和回填,所有这些都可能具有复杂的依赖关系,并且可能影响多个系统、团队或服务。
我个人认为,这个技术债务类别的偶然性是最大的。理解读写模式和数据模型之间的关系可以帮助你有效预防这种债务方面,或者至少有意识地承担它。预测哪里需要灵活性、哪里不应该存在灵活性是非常微妙的问题。随着时间的推移,人们处理这种问题时会更有经验,但必须有意识地应对它们才行。
我们提到了代码、数据和架构类别的技术债务。下次你做设计决策或审查代码时,可以试着找出你所承担的债务,并就此作出明确的讨论:这些债务可能的后果是什么?它什么时候才能得到解决?在日常的开发工作中,架构和数据类技术债务是最难注意到的,但它们以后的消化成本却是最高的,因此值得你认真应对。
最后我想强调的是,技术债务并不总是坏事。使用 MongoDB 来原型化想法或编写一个丑陋的函数来解决关键错误都可以是合理的做法,并且可能是最佳方案。问题是不要故意去做一些增加技术债务的事情。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈