
超越PVT、Swin,南大开源高效Transformer:ResT
点击下面卡片关注,”AI算法与图像处理”
最新CV成果,火速送达

标题&作者团队
来源:AIwalker
paper: https://arxiv.org/abs/2105.13677
code: https://github.com/wofmanaf/ResT
本文是南京大学提出的一种高效Transformer架构:ResT,它采用了类似ResNet的设计思想:stem提取底层特征信息、stages捕获多尺度特征信息。与此同时,为解决MSA存在的计算量与内存占用问题,提出了EMSA模块进一步降低计算量与内存消耗。所提ResT在图像分类、目标检测以及实例分割等任务均取得了显著的性能提升,比如在ImageNet数据上,在同等计算量前提下,所提方法取得了优于PVT、Swin的优异性能,实乃一种强力骨干网络。
Abstract
本文提出一种高效多尺度Vision Transformer:ResT,它可作为图像中识别的通用骨干架构。不同于现有采用固定分辨率+标准Transformer模块的Transformer模型,它有这样几个优势:
(1) 提出了一种内容高效的多头自注意力模块,它采用简单的深度卷积进行内存压缩,并跨注意力头维度进行投影交互,同时保持多头的灵活性;
(2) 将位置编码构建为空域注意力,它可以更灵活的处理任意分辨率输入,且无需插值或者微调;
(3) 并未在每个阶段的开始部分进行序列化,我们把块嵌入设计成重叠卷积堆叠方式。
我们在图像分类与下游任务上对所提ResT进行了性能验证,实验结果表明:所提ResT大幅优于现有骨干架构,比如,ResNet18(69.7%)、PVT-Tiny(75.1%)相似大小的模型下,所提方法取得了79.5%的top1精度,这说明它是一种强有力的骨干网络。
Method
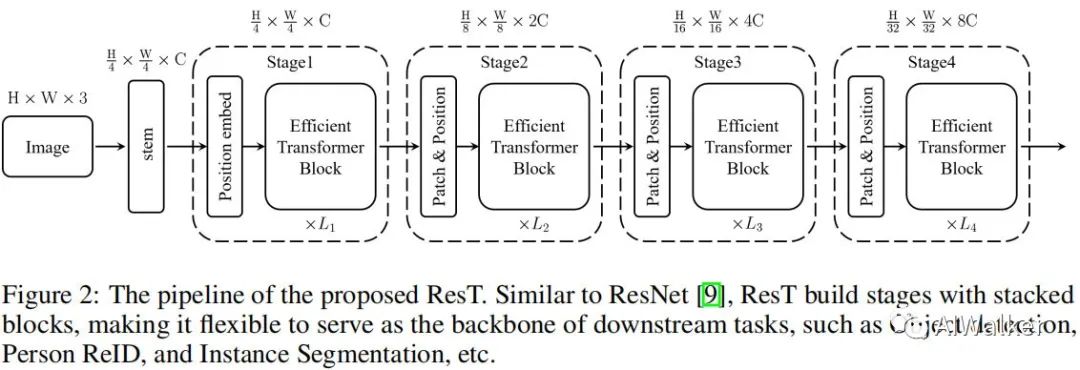
上图给出了ResT的架构示意图,它具有与ResNet相似的结构方案,比如采用stem模块提取底层特征,后接四个stage捕获多尺度特征。每个stage包含三个成分:一个块嵌入模块,一个位置编码模块以及L个高效Transformer模块。具体来说,在每个stge开始前,块嵌入模块用于降低输入的分辨率并扩展通道维度;位置编码用于约束位置信息提升块嵌入的特征提取能力;然后将所得送入到后续高效Transformer模块中。
Rethinking of Transformer Block
标准的Transformer模块由MSA与FFN以及残差链接构成,在MSA与FFN之前还采用LN。对于输入token
,每个Transformer模块的输出表示如下:
其中,MSA的单头SA与FFN的定义分别如下:
MSA与FFN的计算复杂度分别为
,
。
Efficient Transformer Block
如前所述,MSA有两个缺点:(1) 计算量随
平方增长,这会导致较大的训练与推理负载;(2) MSA的每个头仅负责输入的部分子集,这会影响模型的性能,尤其当通道维度非常小时。
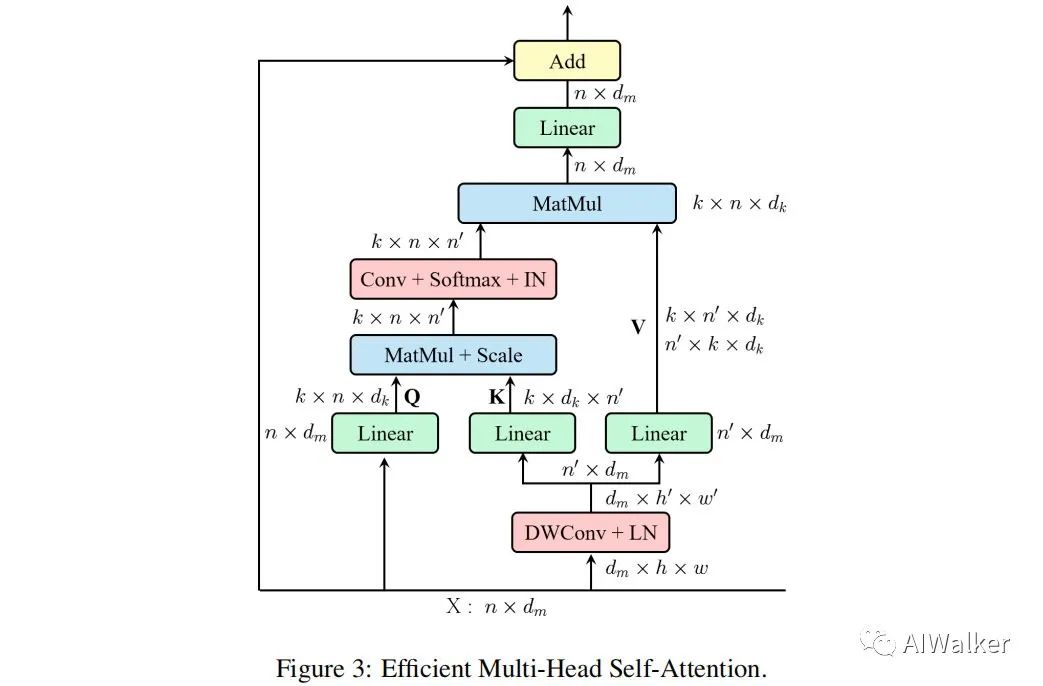
为解决上述问题,我们提出了上图所示的高效多头自注意力模块。可以看到:
类似MSA,EMSA首先采用投影集合得到Q;
为压缩内存,2D输入将被reshap为3D形式,然后送入深度卷积以因子
降低空域维度;
将上述所得特征reshape为2D形式并送入后两个投影集合得到K与V;
然后采用下面公式计算注意力,注:Conv为
卷积,用于对不同头进行信息交互。为补偿Conv导致的多样性素食,我们在Softmax之后添加了IN。
最后,每个头的输出进行拼接并线性 投影构成最终的输出。
EMSA的计算复杂度为,具有比MSA更低的计算量。此时,高效Transformer模块定义如下:
Patch Embedding
标准的Transformer采用一序列token作为输入,以ViT为例,3D图像
需要拆分为
的块,这些块再平展为2D形式并映射为隐嵌入
。然而,这种直接的tokenization难以捕获底层特征信息(比如边缘、角点)。此外,ViT中的tokens长度是固定的,这使其难以进行下游任务(比如目标检测、实例分割)适配。
为解决上述问题,我们构建了一种高效多尺度骨干ResT用于稠密预测。正如前面所提到的,每个阶段的高效Transformer模块在同尺度同分辨率上跨通道、空域维度进行处理。因此,块嵌入模块同样需要渐进的扩展通道维度,同时降低空域分辨率。
类似于ResNet,我们采用stem模块以倍率4收缩宽高维度。为高效捕获底层特征信息,我们引入了一种简单而有效的方式:堆叠三个
卷积,stride分别为212,前两个后接BatchNorm与ReLU。在234阶段,采用块嵌入模块下采样空间分辨并提升通道维度,这与stride=2的卷积作用类似。
Position Encoding
位置编码对于序列顺序的探索非常关键,ViT一文将可学习参数加到输入tokens中编码位置信息。假设
为输入,
表示位置参数,那么编码后输入表示如下:
然而,此时要求位置长度与输入tokens长度相同,这无疑会限制了其应用。
为解决上述问题,我们需要设计一种新的变长位置编码,我们将上式修改为如下:
其中
表示组线性操作,组数为c。
除了上述形式外,我们还可以采用更灵活的注意力机制得到像素级权值。因此,我们提出了一种简单且高效的像素注意力(Pixel-wise Attention,PA)模块进行位置编码。具体来说,PA采用采用
深度卷积计算像素权值,然后采用sigmoid激活,那么带PA的位置编码可以描述如下:
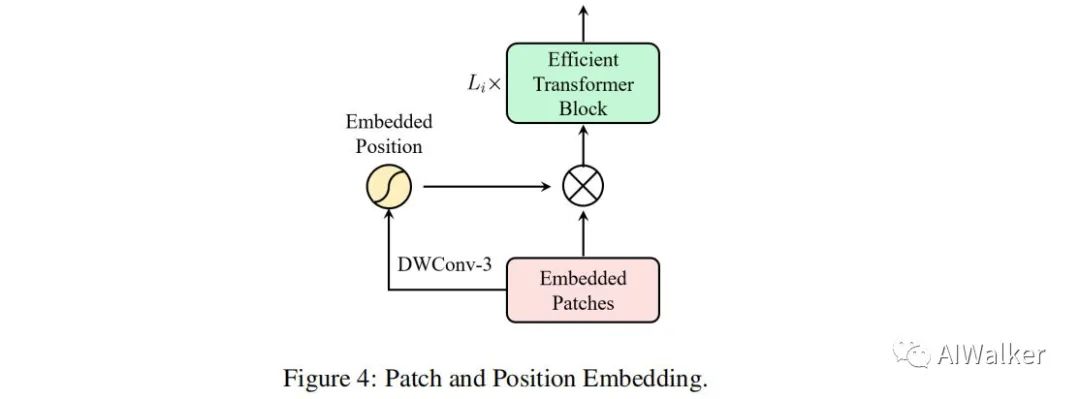
由于每个stage的输入token通过卷积得到,我们可以将位置编码嵌入到块嵌入模块中,整体结果见上图。注:这里的PA可以采用任意空域注意力替换,这使得ResT中的PE极为灵活。
Linear Head
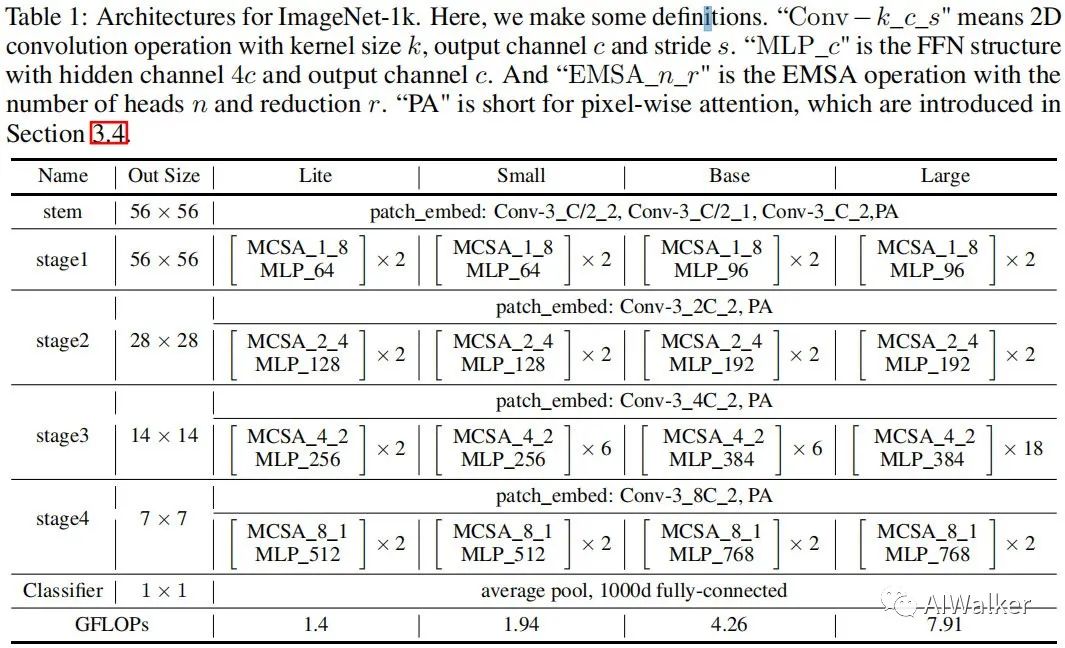
分类头采用全局均值池化+线性分类器的方式,ResT的架构配置信息见下表。
Experiments
接下来,我们在常用基准任务上进行所提方案验证,包含ImageNet数据上的图像分类、COCO数据上的目标检测与实例分割等。
Image Classification
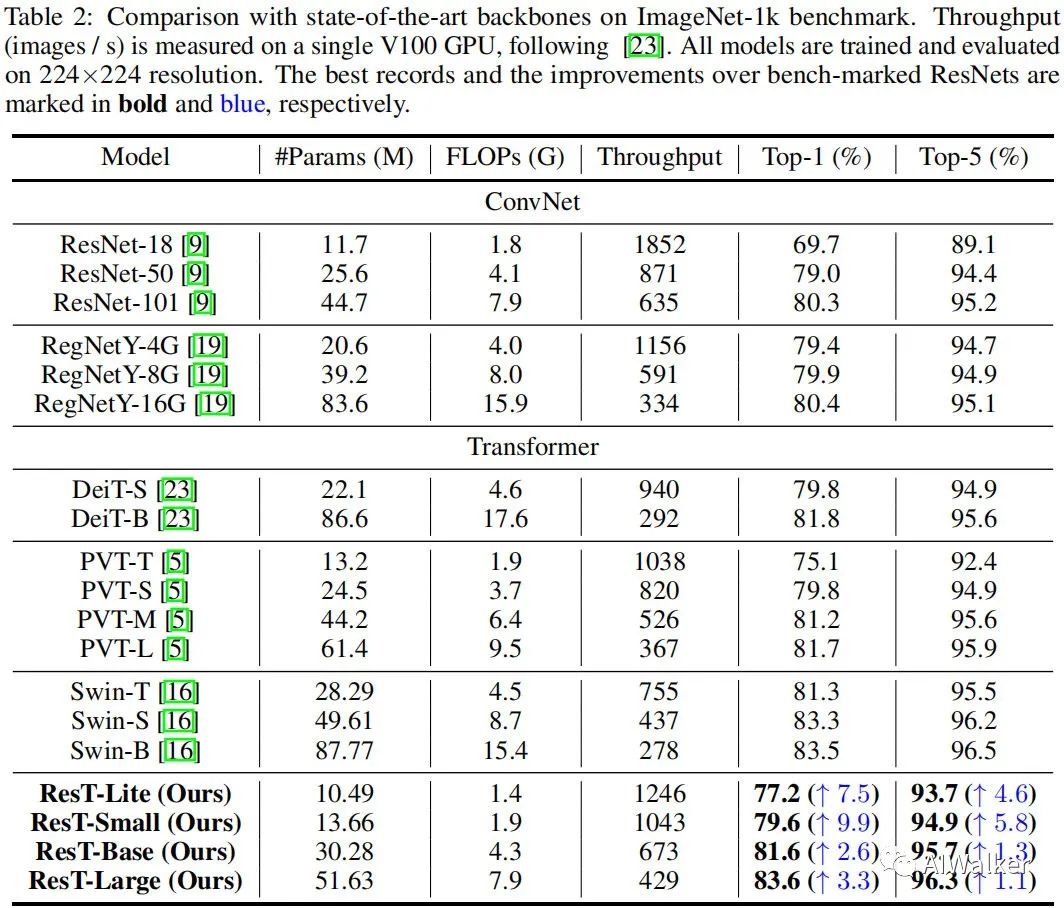
上表给出了图像分类任务上不同方案的性能对比,从中可以看到:
在小模型方面,ResT-small凭借相似的复杂度以79.6%精度大幅超过PVT-T的75.1%;
在中等模型方面,ResT-base凭借相似复杂度以81.6%超过Swin-T的81.3%;
在大模型方面,ResT-Large凭借相似复杂度以83.6%精度超过Swin-S的83.3%;
相比ConvNet,如RegNet,所提ResT凭借相似复杂度取得了更佳的性能;
总而 言之,在不同复杂度模型方面,ResT均显著优于现有模型。
Object Detection and Instance Segmentation
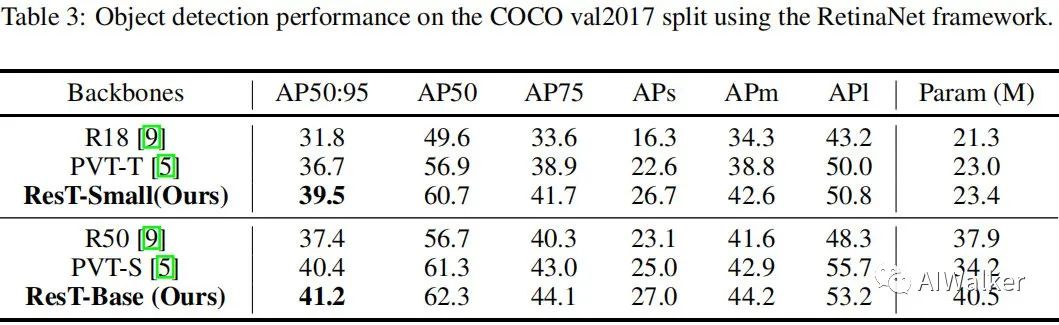
上表给出了RetinaNet架构下的不同骨干模型在目标检测上的性能对比,可以看到:
在小模型方面,相比PVT-T,ResT-Small取得了2.8的指标提升;
在大模型方面,相比PVT-S,ResT-Base取得了0.8的指标提升。
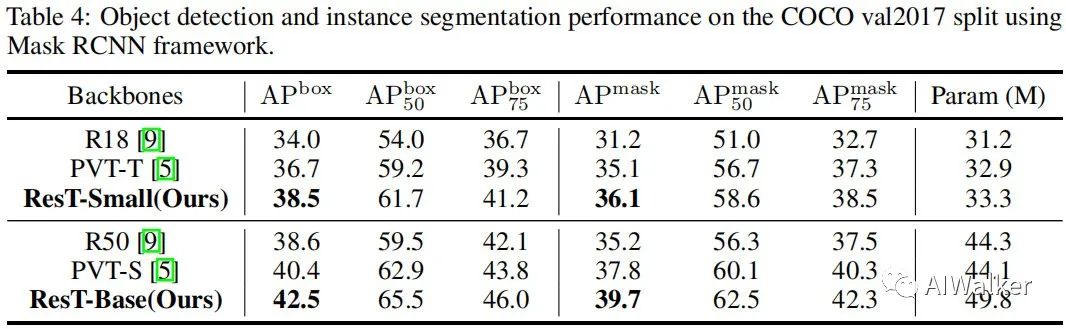
上表给出了实例分割任务上的性能对比,可以看到:
在小模型方面,相比PVT-T,ResT-Small取得了1.8boxAP指标提升,1.0MaskAP指标提升;
在大模型方面,相比PVT-S,ResT-Base分别取得了2.1与1.9的指标提升。
Ablation Study
接下来,我们对所提ResT进行消融实验分析,主要从stem、EMSA、PE三个角度进行对比分析。
从下图的Table5可以看到:ResT中的stem比PVT、ResNet中的Stem更加高效,分别取得了0.92%、0.64%的性能提升。
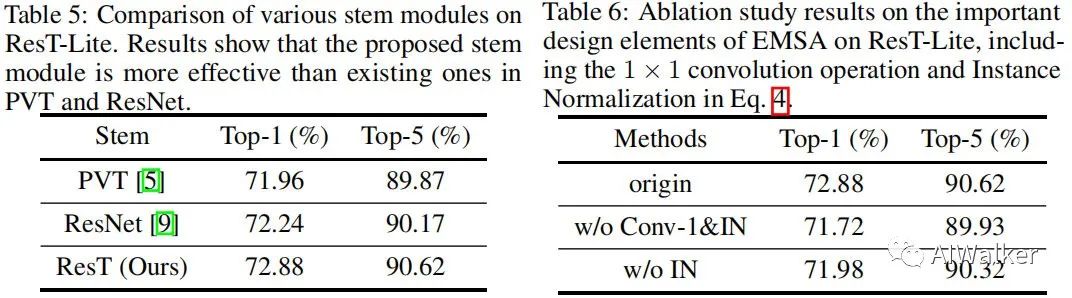
从上图的Table6可以看到:
当移除卷积操作与IN后,模型性能下降1.16%,这说明长序列与灵活性的组合对于注意力非常重要;
当移除IN后,模型同样出现了大幅性能下降,我们将其归因于不同头之间的多样性遭到了破坏。
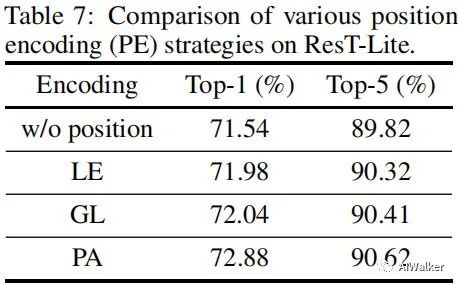
上表对比了不同PE的性能对比,从中可以看到:
当移除PA编码后,模型性能从72.88%下降到71.54%,这说明位置编码对于ResT非常重要;
LE与GL具有相似性能,而PA以0.84%精度优于GL,这说明:空域注意力可用于进行位置编码建模。
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看