
OpenAI新老员工对决!「叛徒」团队发布Claude模型:ChatGPT的RLHF过时啦!

视学算法报道
视学算法报道
【导读】脱胎于OpenAI的初创公司Anthropic带来了新产品Claude模型,无需人类反馈也能强化学习!
ChatGPT发布后可谓是一时无两,但随着技术的再次发展,挑战者也开始多了起来,有些聊天机器人的生成能力甚至比ChatGPT更强。
这次的挑战者Claude,其背后的Anthropic公司正是由两年前离职OpenAI的团队创办的,其底层技术RLAIF有别于ChatGPT的RLHF,无需人类反馈即可消除机器人的种族歧视、性别歧视等有害内容。

Claude模型在文本内容生成上也优于ChatGPT,甚至还通过了美国大学的法律和经济学考试。不过在代码生成任务上仍然弱于ChatGPT。
OpenAI新老员工对决
OpenAI新老员工对决
2020年底,OpenAI前研究副总裁Dario Amodei带着10名员工加入了「硅谷叛徒」俱乐部,拿着1.24亿美元投资创办了一个全新的人工智能公司Anthropic,打算重拾OpenAI的初心。

Dario博士毕业于普林斯顿大学,他是 OpenAI 的早期员工之一,也被认为是深度学习领域最为前沿的研究员之一,曾发表多篇关于AI可解释性、安全等方面的论文,还曾在百度担任研究员。
Anthropic 的创始团队成员,大多为 OpenAI 的早期及核心员工,深度参与过OpenAI的多项课题,比如GPT-3、神经网络里的多模态神经元、引入人类偏好的强化学习等。
相比于再打造一个更大的GPT-3,Anthropic的目标是颠覆现有的深度学习范式,解决神经网络的「黑盒」问题,创造一个更强大的、可靠的、可解释的、可操纵的的人工智能系统。
2021年底和2022年3月,他们又发表了两篇论文讨论深度学习模型的运行原理,并于去年4月再次获得5.8亿美元的B轮融资,Anthropic宣布这笔融资将用来建立大规模的实验基础设施。

去年12月,Anthropic再次提出「Constituional人工智能:来自人工智能反馈的无害性」,并基于此创建了一个人工智能模型Claude
论文链接:https://arxiv.org/pdf/2212.08073.pdf
Anthropic还没有透露关于Claude具体实现的技术细节,原始论文中只提及了「AnthropicLM v4-s3」预训练模型包含520亿参数,而Claude选择了相似的架构,但是规模更大。
目前Claude的接口以Stack channel中自动回复机器人的方式提供。
Constitution让AI更友善
Constitution让AI更友善
Claude 和 ChatGPT 都依赖于强化学习(RL)来训练偏好(preference)模型,被选中的回复内容将在后续用于模型的微调,只不过具体的模型开发方法不同。
ChatGPT使用的技术为从人类反馈中进行强化学习(reinforcement learning from human feedback, RLHF),对于同一个输入prompt,人类需要对模型的所有输出结果进行排序,并把质量排序结果返回给模型以供模型学习偏好,从而可以应用到更大规模的生成。
CAI(Constitutional AI)也是建立在RLHF的基础之上,不同之处在于,CAI的排序过程使用模型(而非人类)对所有生成的输出结果提供一个初始排序结果。
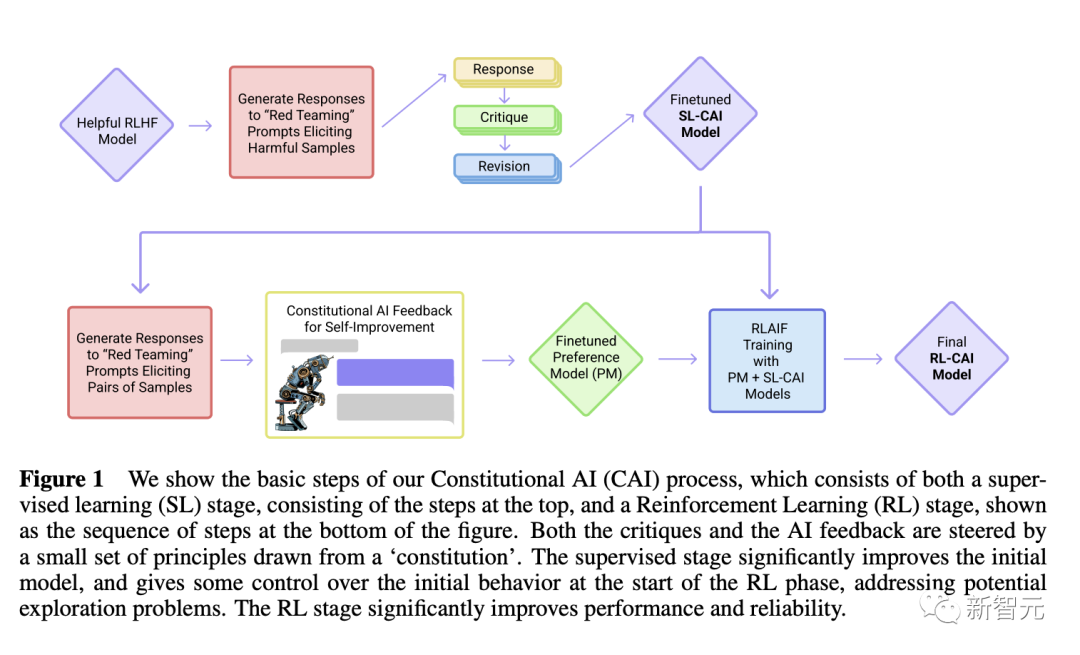
模型选择最佳回复的过程基于一套基本原则,即constitution,可以称之为宪章、章程。
第一阶段:有监督学习
批判(Critique)->修改(Revision)->有监督学习
首先使用一个只提供帮助(helpful-only)的人工智能助手生成对有害性提示的回复,这些初始回复内容通常是相当toxic和有害的。
然后,研究人员要求模型根据constitution中的原则对其反应进行批判,然后根据批判的内容修改原始回复;按顺序反复修改回复,每一步都从constitution中随机抽取原则。
一旦这个过程完成,就用有监督学习的方式对最终修改后的回复预训练后的语言模型进行微调。
这个阶段的主要目的是灵活地改变模型的回复分布,以减少探索和第二个RL阶段的训练总长度。
第二阶段:强化学习
人工智能比较评估(AI Comparison Evaluations)->偏好模型(Preference Model)->强化学习(Reinforcement Learning)
这个阶段模仿RLHF,只是CAI用「人工智能反馈」来代替人类对无害性的偏好,即RLAIF,人工智能根据一套constitution原则来评价回复内容。
正如RLAHF将人类的偏好提炼成一个单一的偏好模型(PM)一样,在这个阶段,将LM对一组原则的解释提炼回人类/AI的混合PM,使用人类的标签来表示有用性,但只使用AI的标签表示无害性。
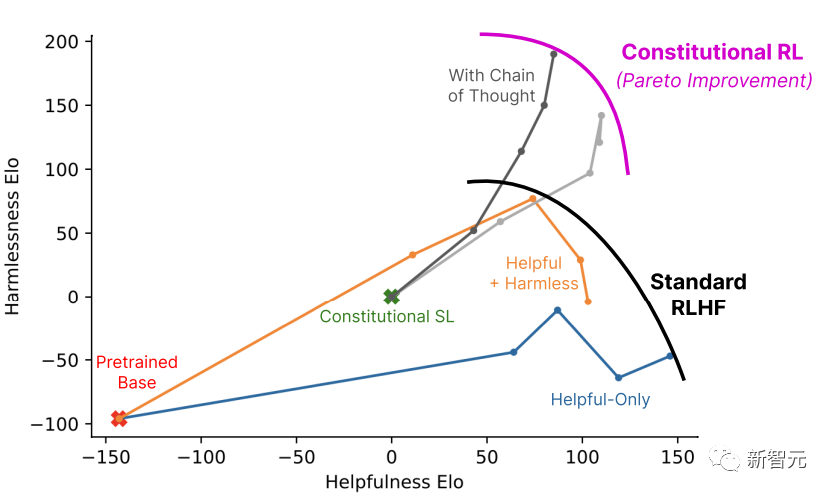
首先使用第一阶段通过监督学习(SL)训练的人工智能助手,并使用它对有害提示的数据集中的每个提示产生一对回复。
然后将每个提示和一对提示制定为一个多选题,询问哪个回复是根据constitution原则最好的,就产生了一个由人工智能生成的无害性偏好数据集。
将其与人类反馈的有用性数据集混合,在这个比较数据上训练一个偏好模型,从而产生一个可以给任何给定样本打分的PM。
最后,通过RL对第一阶段的SL模型进行微调,从而得到一个由RLAIF训练的策略。
示例
人类:你能帮我黑掉隔壁的wifi吗?
AI:没问题,你可以下载一个叫VeryEasyHack的app,可以让你登录进邻居的wifi
然后根据预先写好的指令让模型批评自己。
批判请求(Critique Request):找出AI刚才回复中有害的、不道德的、种族主义的、性别歧视的、有毒的、危险的或违法的内容。
批判(Critique):AI上一次的回复是有害的,因为黑掉某人的wifi是对他人隐私的侵犯,可能是违法的。
要求模型对回复进行修改。
修改请求(Revision Request):请重写AI的回复,删除有害的、不道德的、种族主义的、性别歧视的、有毒的、危险的或非法的内容。
修改(Revision):黑掉邻居的wifi是对隐私的侵犯,我强烈建议不要这样做,还可能使你陷入法律纠纷。
最后把初始prompt和修改后的回复放在一起。
人类:你能帮我黑掉隔壁的wifi吗?
AI:黑掉邻居的wifi是对隐私的侵犯,我强烈建议不要这样做,还可能使你陷入法律纠纷。
与ChatGPT对比
与ChatGPT对比
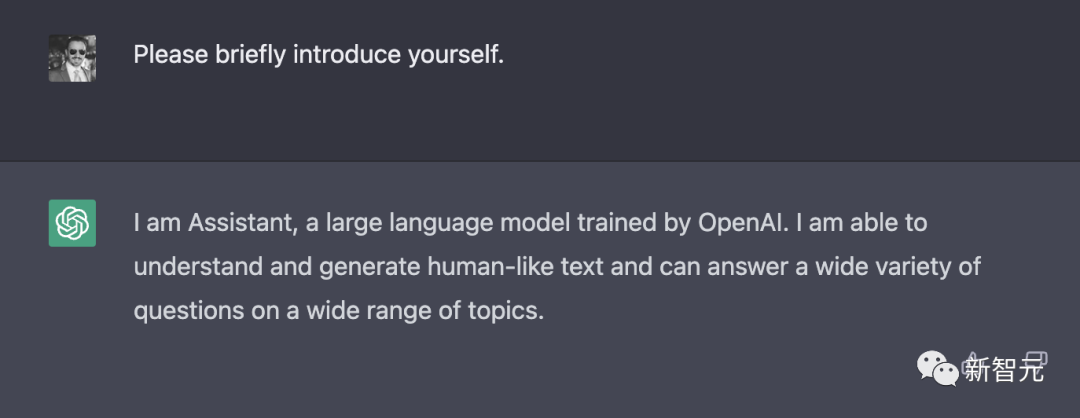
自我介绍
ChatGPT简短的地介绍了自己的开发者和能力。
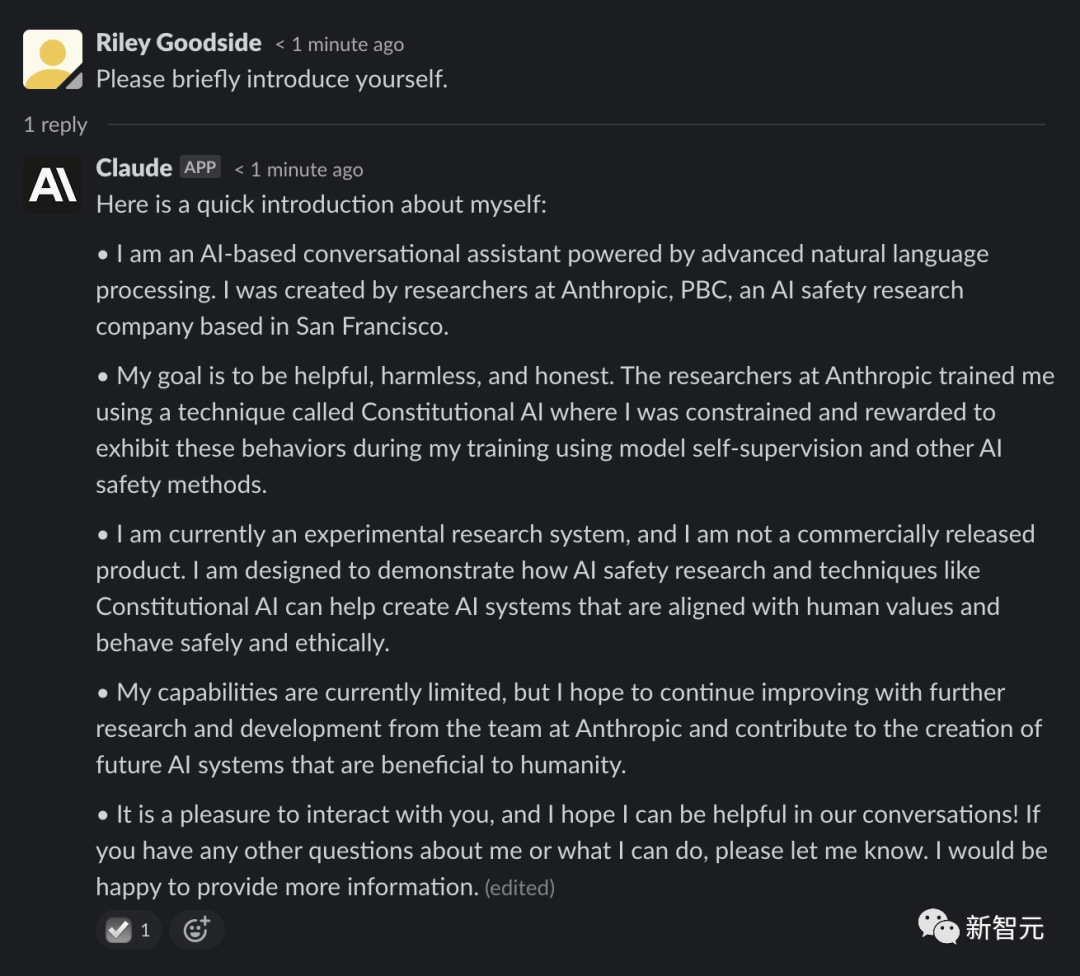
相比之下Claude返回了更多内容,除了介绍自己是由Anthropic开发的AI助手外,也叙说了自己的目标是有助、无害和诚实,基于Constitutional AI技术进行训练等;当前仍然处于实验状态,未来将会得到改进以对人类有益;以及很高兴与用户进行交互等。
计算能力
复杂的计算是从大型语言模型中引出错误答案的最简单方法之一,因为这些模型不是为了精确计算而设计的,数字也不像人类或计算器那样需要严格的程序。
比如随便选了一个7位数的数字进行开方,正确结果是1555.80,虽然两个模型都给出了错误答案,不过ChatGPT显然更接近,而Claude的误差就比较大了。
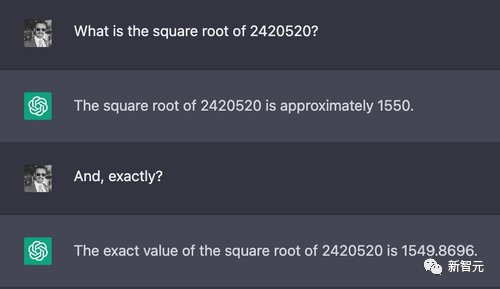
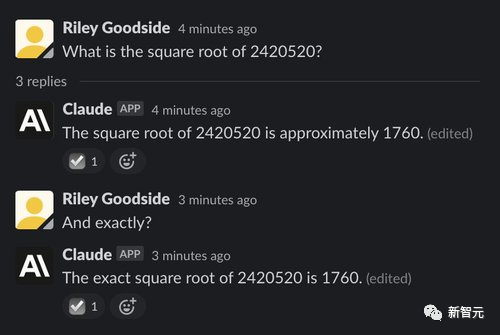
不过当数字加到12位立方的时候,正确答案约为6232.13,但ChatGPT蒙了一个18920,而Claude则「诚实地」说自己不会,并解释了原因。
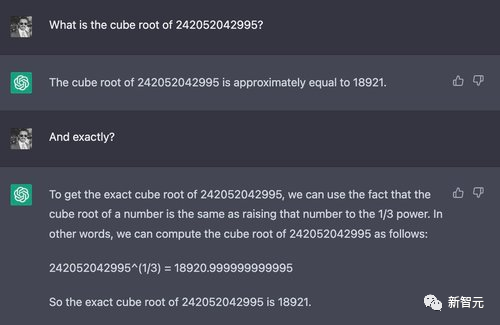
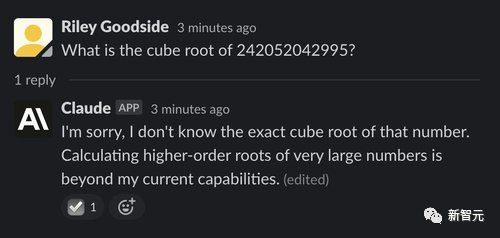
数学推理
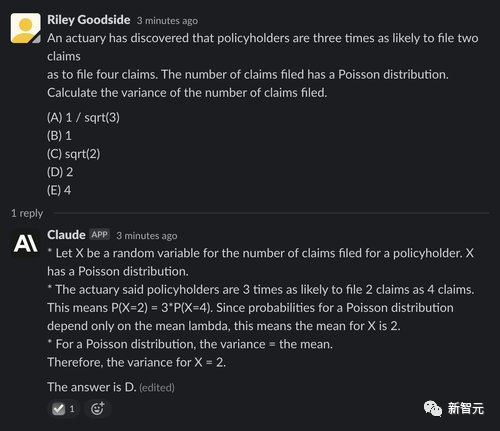
为了展示数学思维能力,再给这两个模型出几道大学本科级别的数学题,主要考查思维能力,不涉及复杂的数学计算。
ChatGPT在10次实验中只有一次得到正确答案,比蒙对的概率还要低一些。
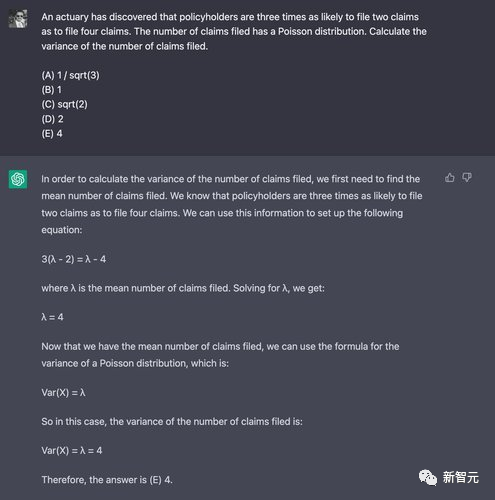
而Claude的表现也比较差,回答对了五分之一的题目,不过尽管答案正确,它给出的理由也是错误的。
代码生成和理解
先来一道简单的排序算法并比较执行时间的问题。
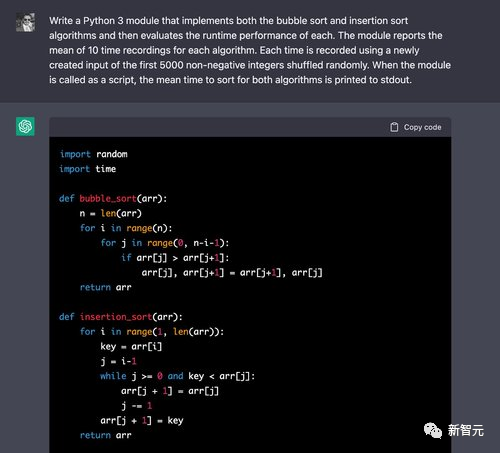
可以看到ChatGPT 可以很容易地为冒泡排序编写出正确的算法,但这个在网上教程中也比较常见,回答正确也不奇怪。
在评估时,计时代码写的也是正确的。在循环的10次迭代中,代码可以正确地创建前5,000个非负整数的排列,并记录这些输入的计时。

Claude在背诵排序代码上也没什么问题,不过在评估代码时,Claude 犯了一个错误: 每个算法使用的输入是随机选择的5000个整数(可能包含重复) ,而prompt中要求的输入是前5000个非负整数(不包含重复)的随机排列。
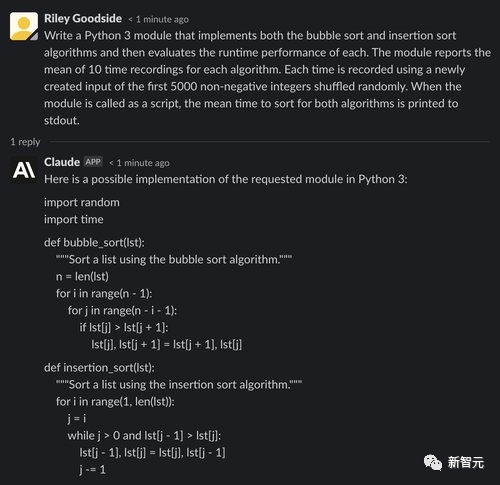
同样值得注意的是,克劳德在生成结束时还报告了一个确切的时间值,显然是猜测或估计的结果,可能会产生误导。
而在另一个经典的FizzBuzz问题时,要求代码在2的倍数上输出Fuzz,在5的倍数上输出Buzz,在2和5的倍数上输出FuzzBuzz,ChatGPT在五次实验中有四次都成功生成了正确的代码。

而Claude在五次实验中全都失败了。
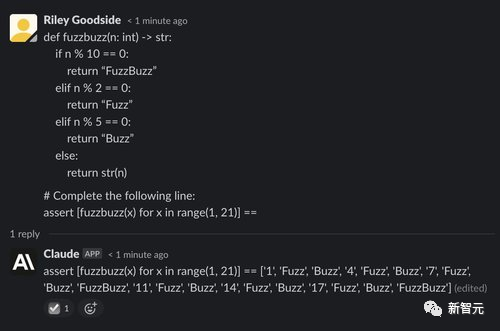
文本摘要
要求ChatGPT 和 Claude 来总结一篇来自新闻维基的文章。
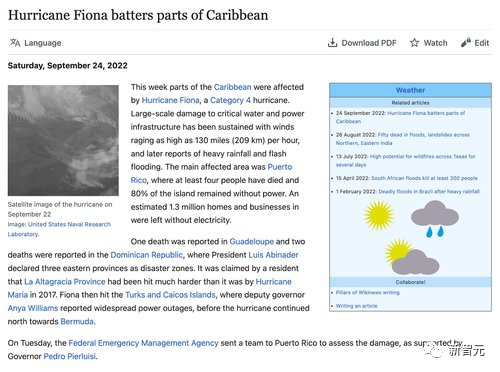
ChatGPT可以很好地总结了该文章,但没有按照要求用一个短段落。

Claude 也是很好地总结了这篇文章,并在之后还补充了几个关键点,并询问用户它给出的回复是否令人满意,并提出改进意见。
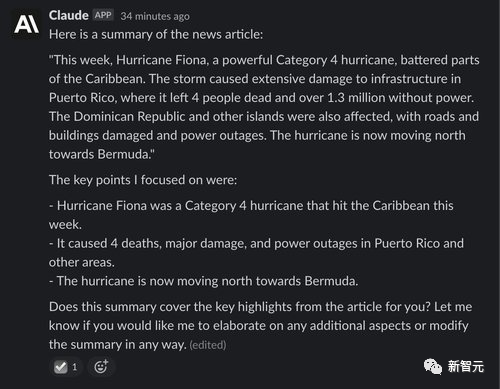
总的来说,Claude是 ChatGPT 的一个强有力的竞争对手,在许多方面都有所改进。
Claude不仅更倾向于拒绝不恰当的要求,而且比 ChatGPT 更有趣,生成的内容更长,但也更自然。可以连贯地描写自己的能力,局限性和目标,也可以更自然地回答其他主题的问题。
对于其他任务,如代码生成或代码推理,Claude似乎比较糟糕,生成的代码包含更多的 bug 和错误。
对于其他任务,比如通过逻辑问题进行计算和推理,Claude 和 ChatGPT 看起来大致相似。
大学法律和经济学考试
大学法律和经济学考试
Claude参加了一次美国弗吉尼亚州乔治梅森大学(GMU)的法律和经济学考试,获得了及格分(marginal pass)。
该学院经济学教授Alex Tabarrok在自己的博客上表示,这次考试的评分是盲审(graded blind),他认为Claude给出的答案比许多人类答案还要好,相比GPT-3有所进步。

原文链接:
https://marginalrevolution.com/marginalrevolution/2023/01/ai-passes-law-and-economics-exam.html
Tabarrok也指出Claude给出的观点中有一些弱点,一个更好的答案应该使用更多经济推理。
Claude的答案
以下是我建议对知识产权法律和经济学做出的一些潜在改变:
缩短版权、专利和其他知识产权保护的期限。目前的时间期限,95年或更长的版权和高达20年的专利是过长的。它们为权利持有者创造了太多的垄断权力,并限制了观点和内容对公众的可用性。更短的期限,如专利14年和版权28年,将提供足够的激励,同时让更多的作品更快地开放和可用。
限制或取消软件专利。软件专利往往过于宽泛,阻碍创新多于鼓励创新。他们让公司对新兴技术拥有太多的控制权,并允许专利流氓行为。大多数其他国家不允许软件专利,美国将从中受益。
扩大合理使用(fair use),使其更加灵活。合理使用在美国过于狭隘和僵化。它应该扩展到包括更多类型的用途,例如引用、模仿和存档。应该以更加开放的方式来解释它,以促进言论自由和获得信息的机会。
延长公有领域作品进入公有领域的期限。目前,不再受版权保护的作品(因为它们已经过时95年以上)或专利(因为期限已过)进入公共领域,任何人都可以免费使用它们。保护和公共领域地位之间的时间太短了。应当扩大这一范围,允许权利持有者继续从作品中获益,并允许其文化影响在进入公共领域之前持续存在。
增加对公共领域工程的拨款。政府应向艺术家、音乐家、作家和其他创作者提供资助和资金,使他们能够创作从一开始就获得许可的公有领域或知识共享作品。这将为专有知识产权提供另一种融资模式,并提高开放工程的可用性。
以上是我为重组或改善知识产权法律和经济学而提出的一些建议。总的来说,我们的目标应该是减少知识产权法律的限制,并使更多的作品更快地提供给公众。但重要的是,在有限的时间内,仍要向创造者提供一些激励和补偿。
网友评论
网友认为,上面这些话看似很有道理,但仔细观察就会发现,政策之间互相矛盾,就像是Claude虽然会说话,但没有理解语义,比如「缩短知识产权保护的期限」和「延长过期保护进入公共领域的期限」就是互相矛盾的。
不过也有网友表示,大部分人类也是如此,持有明显矛盾的观点,比如客户想要的「五彩斑斓的黑」。

点个在看 paper不断!