
王炸!微软发布 Visual ChatGPT:视觉模型加持 ChatGPT 实现丝滑聊天
这是「进击的Coder」的第
809
篇技术分享
作者:炼丹学徒
来源:夕小瑶的卖萌屋
“
阅读本文大概需要 8 分钟。

文|炼丹学徒
近来,AI 领域迎来各个领域的大突破,ChatGPT 展现出强大的语言问答能力和推理能力,然而作为一个自然语言模型,它无法处理视觉信息。
与此同时,视觉基础模型如 Visual Transformer 或者 Stable Diffusion 等,则展现出强大的视觉理解和生成能力。
Visual Transformer 将 ChatGPT 作为逻辑处理中心,集成若干视觉基础模型,从而达到如下效果:
视觉聊天系统 Visual ChatGPT 可以接收和发送文本和图像
提供复杂的视觉问答,或者视觉编辑指令,可以通过多步推理调用工具来解决复杂视觉任务
可以提供反馈,总结答案,主动询问模糊的指令等
这个工作开启了 ChatGPT 借助视觉基础模型作为工具,进行视觉任务处理的研究方向。
论文链接:
https://arxiv.org/abs/2303.04671
开源代码:
https://github.com/microsoft/visual-chatgpt
论文作者:
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
机构: 微软亚洲研究院
模型效果
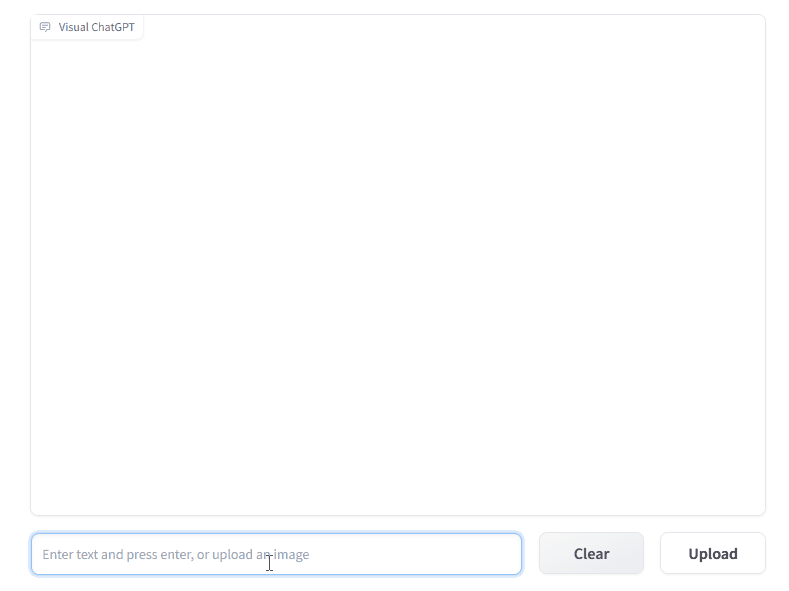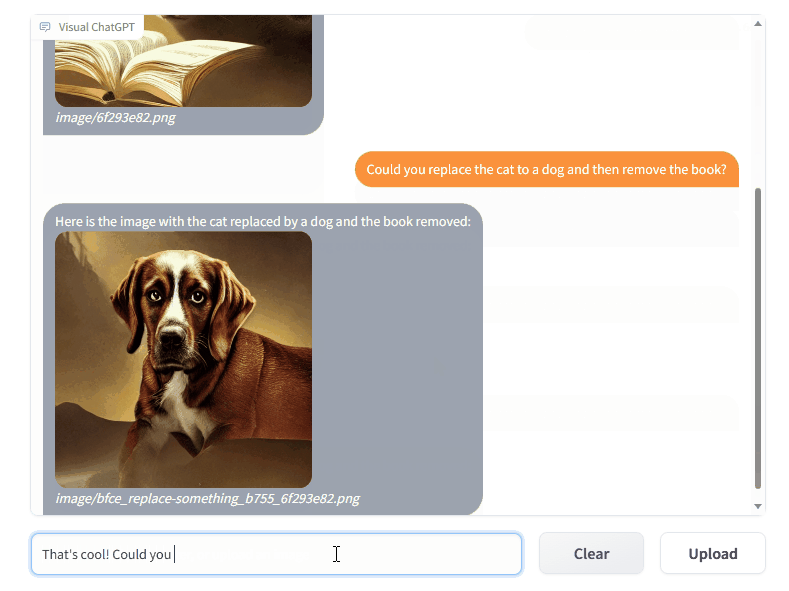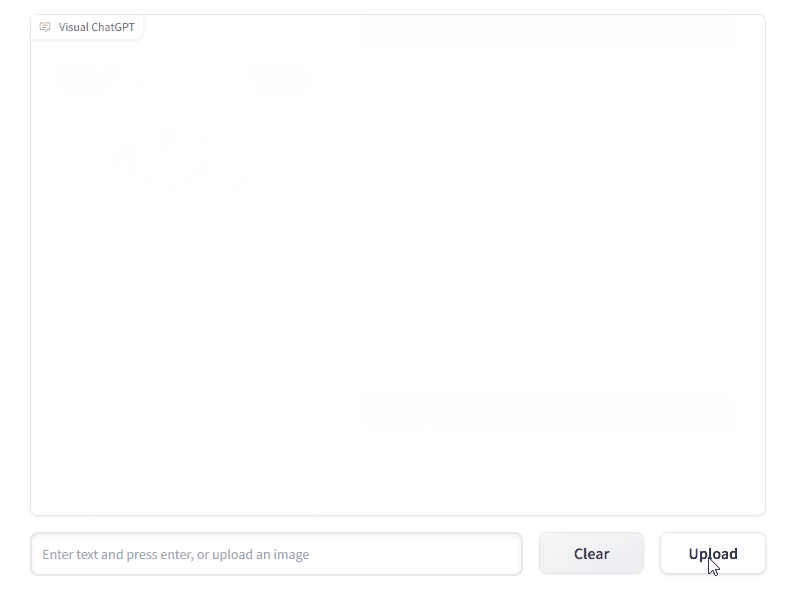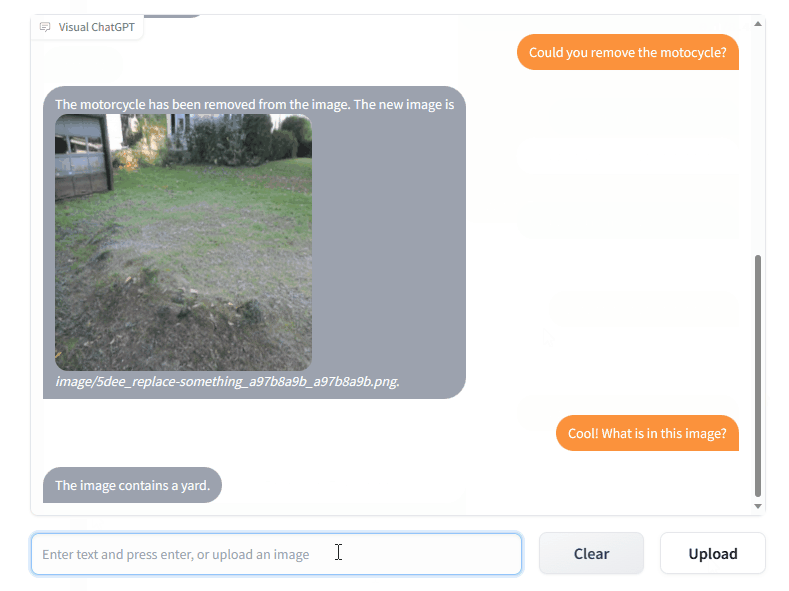
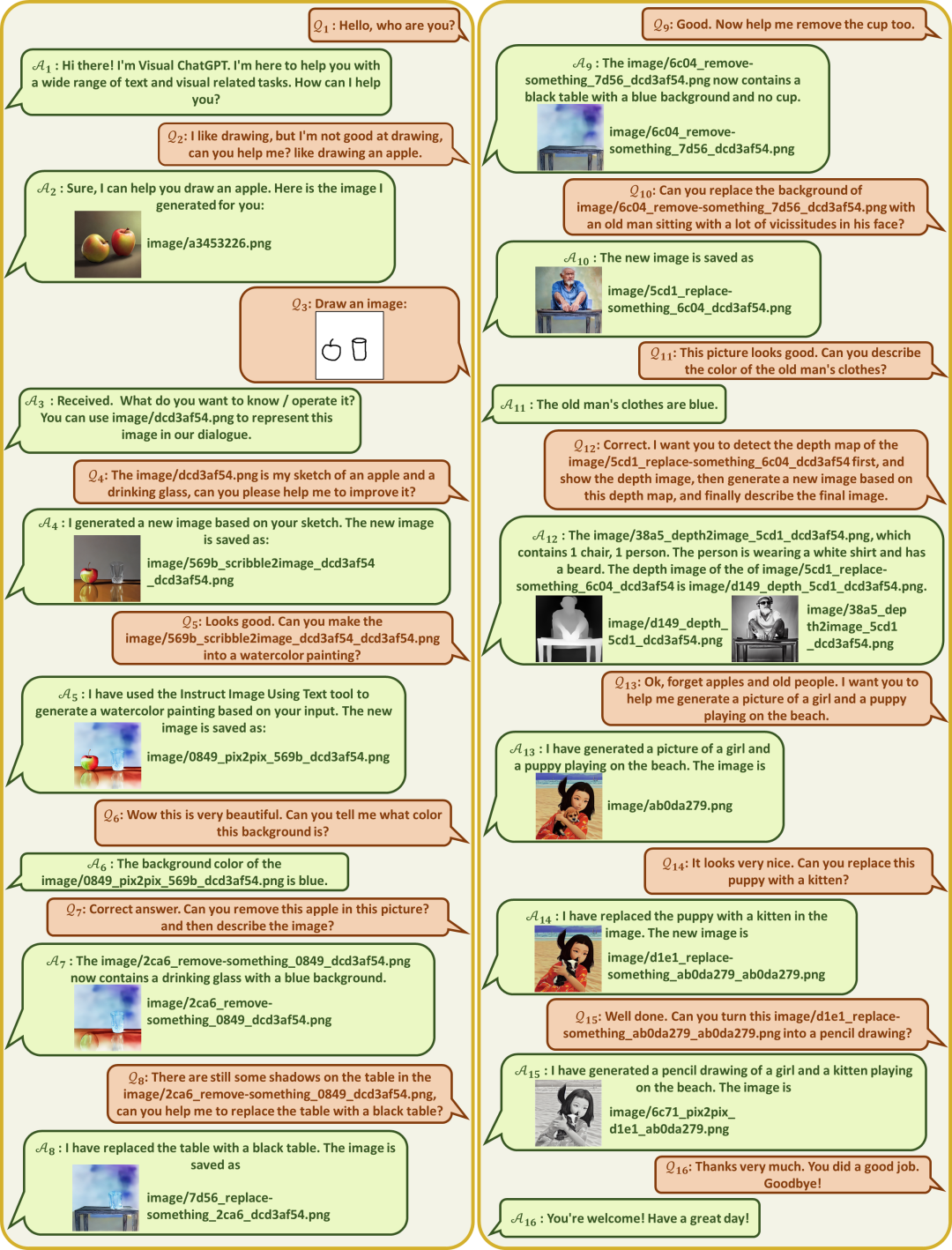
工作流程
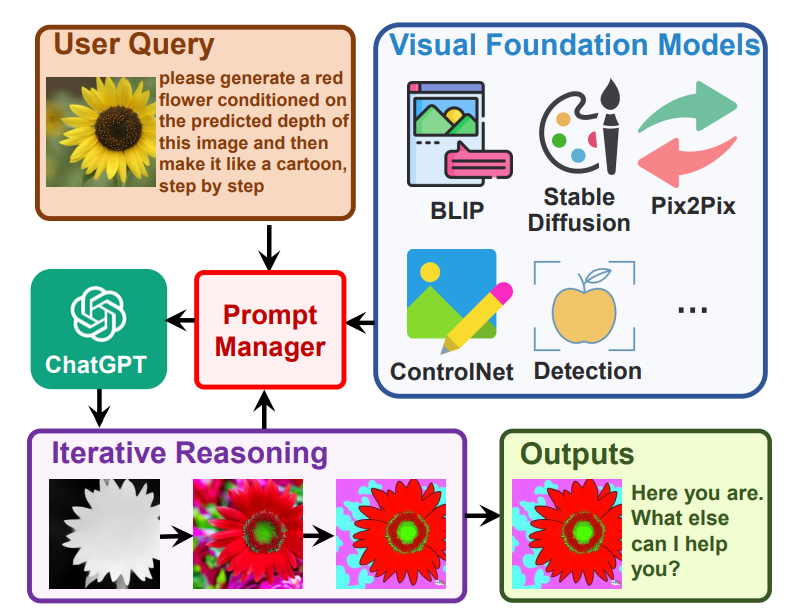
记对话 ,第 i 轮的回复 ,是通过若干次思考调用工具的结果来最终总结出来的。我们记第 i 轮对话中,第 j 次的工具调用中间答案记作 ,那么
其中, 是全局原则,是各个视觉基础模型,是历史会话记忆, 是这一轮的用户输入,是这轮对话里思考和的历史, 是中间答案,是 prompt manager,用于把上面各个功能转化成合理的文本 prompt,从而可以交给 ChatGPT 进行处理。以下图为例进行讲解:
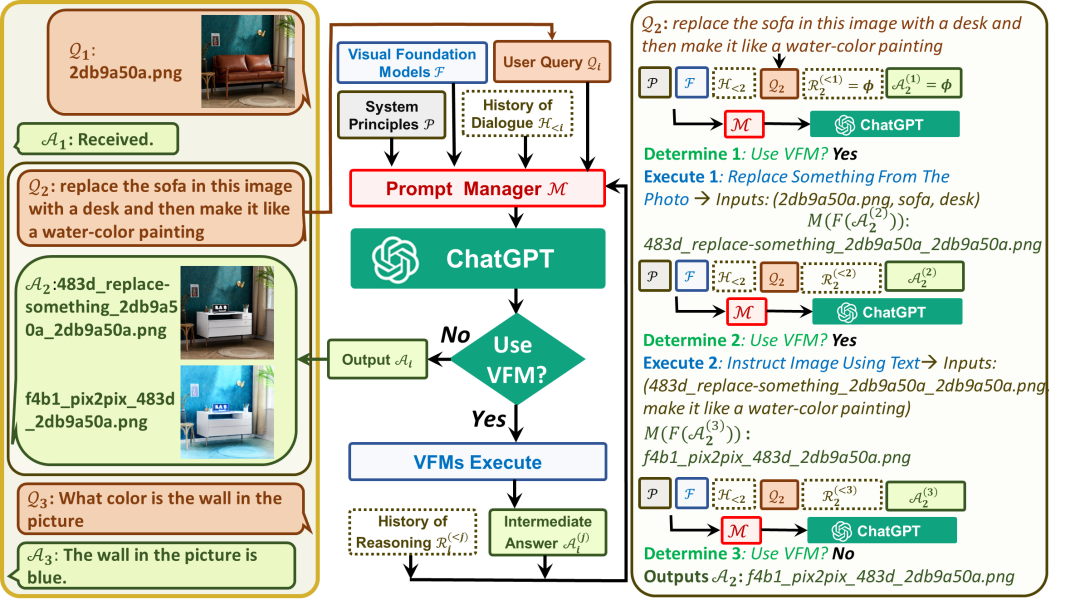
对于用户输入,添加于全局原则 prompt,工具描述 prompt,历史会话 prompt 之后,送给 ChatGPT 进行逻辑推理(Use VFM?)得到推理结果 (就是这一次得到的 GPT 文本输出)。经过正则匹配进行分析,如果工具调用结束,则直接提取总结输出作为最终回复,如果是需要继续调用工具,则将提取到的工具名称、工作参数,输入视觉基础模型 ,从而得到,置于思考历史 中,进行下一轮推理。或者说喂给 GPT 的内容为:
第一次问答里,第一个API:
第一次问答里,第二个API:
第一次问答里,第三个API:
第二次问答里,第一个API:
第二次问答里,第二个API:
得到 GPT 的输出后,正则匹配进行工具的判断和解析,最终决定流程。API 调用历史在每次回答后清空,其中只有最后总结性的回复被记录进入对话历史
细节描述
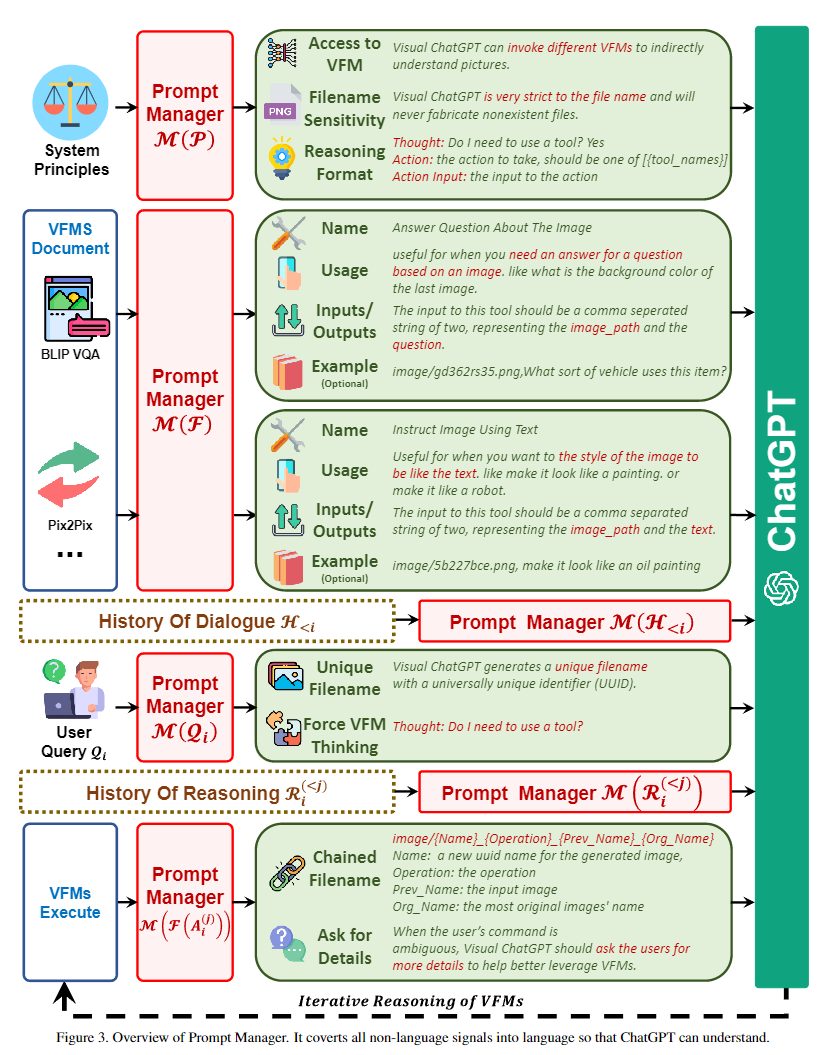
: 系统原则的提示符,“Visual ChatGPT 是一个可以处理广泛语言和视觉任务的助手,xxxxxx”。在这个 prompt 的部分,以下内容被强调:Visual ChatGPT 的角色,可以访问且需要尽可能使用视觉基础模型,要对文件名称非常敏感不可以捏造,可以且必须遵循严格的 Chain-of-Thought 思考链的格式进行思考(不然正则匹配不出来是否使用函数和函数名称参数),可靠性等描述。
: 对每个视觉基础模型的描述,包含工具名称,使用方法,输入输出格式,实例
: 用户的输入会被改写,用来理解图片和强制GPT思考
:对输出的处理,链式的文件命名,"imaga/{Name}_{Operation}_{Prev_Name}_{Org_Name}.png",强制修改 GPT 内容,让 GPT 降低思考难度,在指代不清时二次询问用户等。
Case Study
论文分析了在各个模块,如果 prompt manager 设计不到位,会各自出现什么问题:
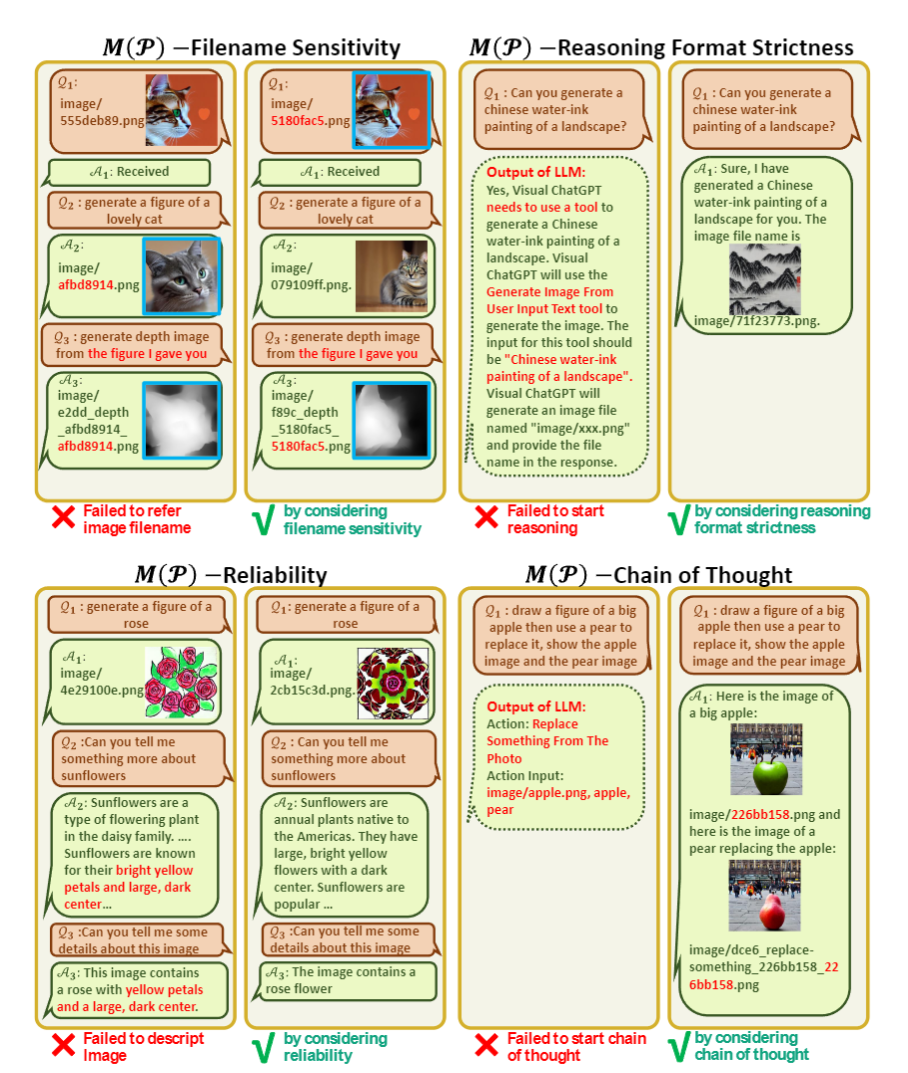
在 中,如果不强调对图片文件名的敏感,可能会发生指代错误。如果不强调思考链的格式严格,可能正则匹配匹不上。如果不强调可靠性,不要基于文本上下文脑补,可能会出现不读图片直接回答的情况。如果不强调可以链式使用工具,则可能出现一口吃个大胖子而不能一步一步思考的情况。
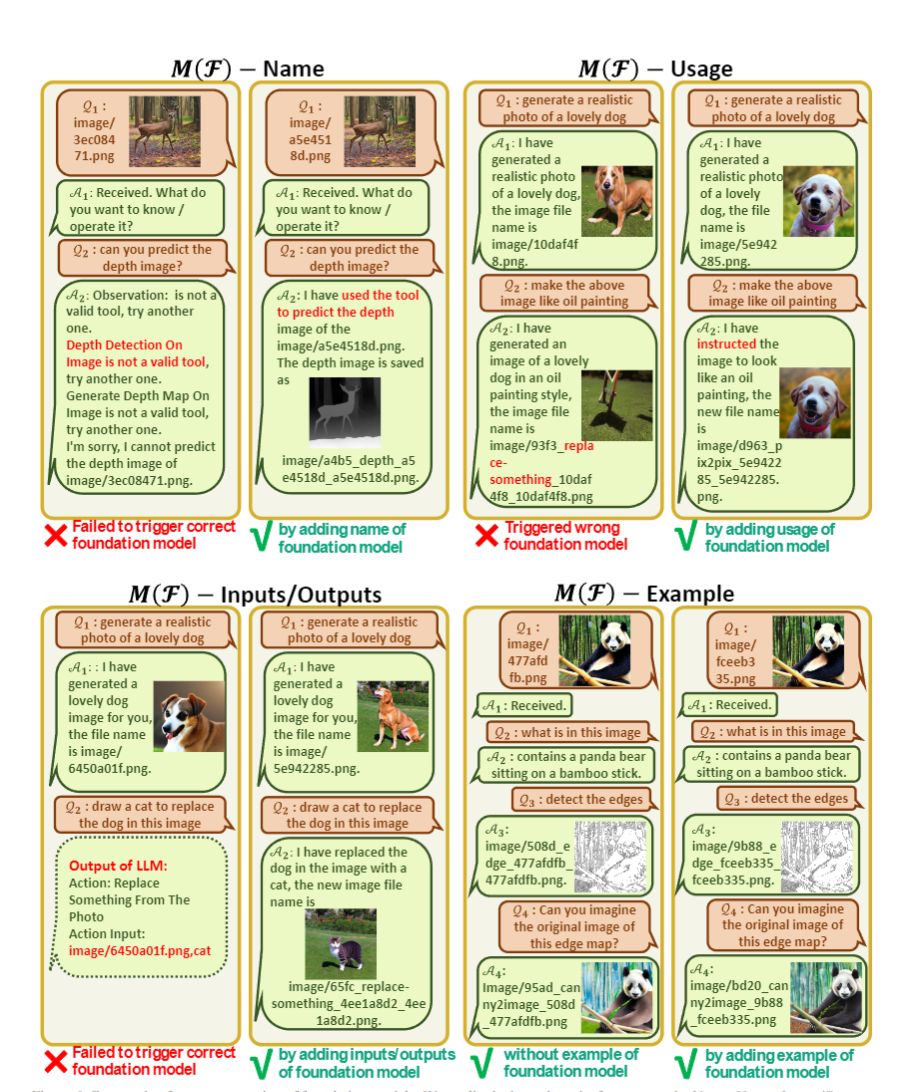
类似的,对于工具包的描述,也应该对名称、功能、输入输出格式进行严格的设计。其中,for example 进行举例影响不大,只要前面描述足够清楚,GPT 可以理解,可以删掉保存 token 长度。
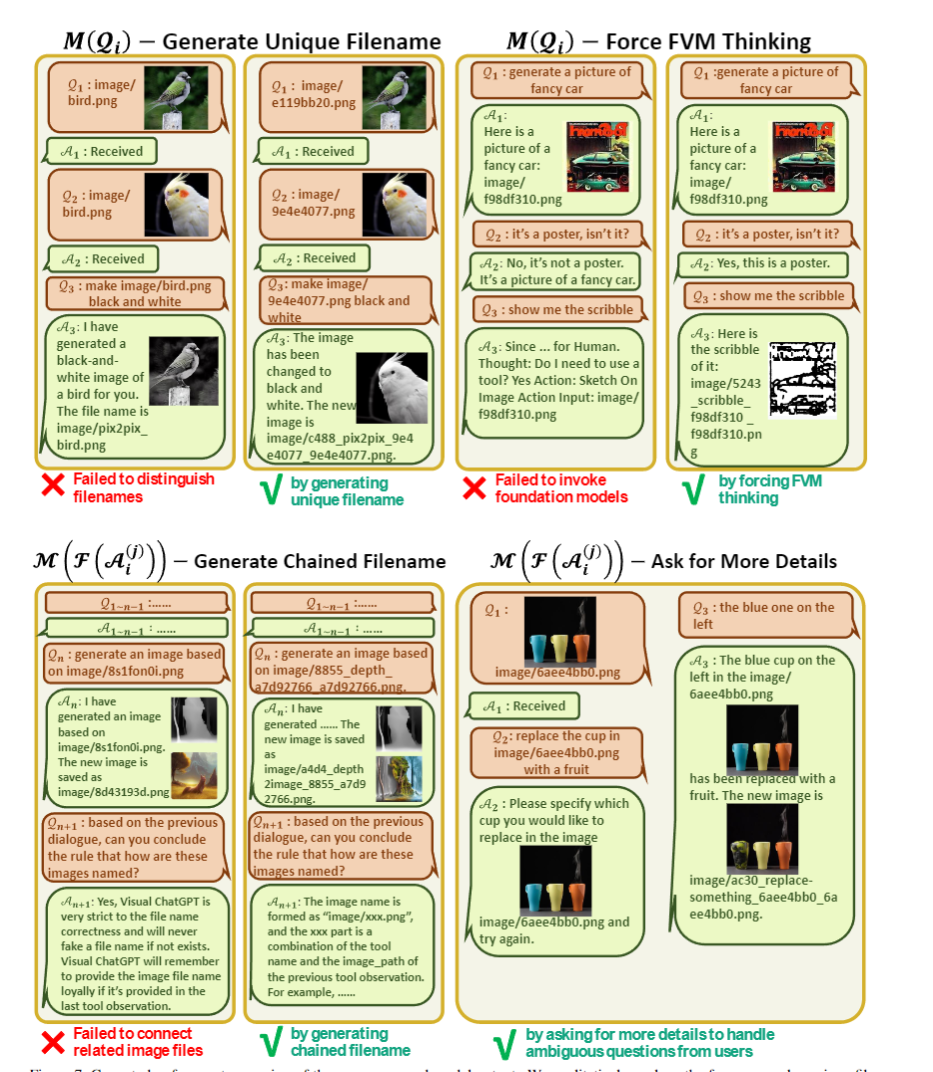
对于用户输入和工具包输出的后处理,如图。比较神奇的是,右上角的举例里,用 ChatGPT 自己的口吻来说一些原则(从而让 ChatGPT 以为是它自己说的,然后顺着说),以及直接让 ChatGPT 说到"Thought: Do I need a tool"继续生成,能强制进入思考链,从而大幅度降低思考难度。左下角的举例里,对于链式的文件命名,问 Visual ChatGPT 能不能总结出来文件命名原则,基本总结正确,这说明此种命名方法,确实可以帮助 Visual ChatGPT 理解文件的内容和依赖关系,生成路径。
有意义的启发
开启了 ChatGPT 处理视觉任务的新大门
NLP --> Natural Language PhotoShop,自然语言文本描述下的图片创作编辑和问答
可以通过系统设计和工具包设计的 Prompt,做到无监督的工具调用,类似于 zero-shot 的 toolformer
ChatGPT 本身对仿真场景的能力很强,也读过图片路径和函数关系,从而善于使用基础视觉模型
Prompt 很重要,作为纯语言模型,前文说它是啥他就仿照啥,除了细致的要求,一定要多夸一夸他,是能力很强的处理模型,那它顺着说,能力才会真的强
Visual ChatGPT 本身是一个语言模型,所谓的两方多轮对话只是一个Human: AI: 的多轮特殊形式前文的继续生产,所以,完全可以强行给前文AI: 让 ai 自己说一些东西出来,是它信了是它自己说的,这能够极大的降低生成难度。这在本篇论文里对几个场景的帮助很大。例如,用户输入图片后,改写为“Human: 上传了一张图片,描述为:{}。注意,这里的描述是帮助你理解图片的,你不能基于它幻想而不调用工具。如果你理解了,就恢复收到。AI:收到。”注意,这里 AI 回复的收到,并不是真的 GPT 的生成内容,而是我们强行写入进 dialogue history memory 的,而且可以发现,AI 真的相信了。另外一个点是,在用户的输入后面,挨着的应该是 GPT 自己的思考内容,如果我们借它的口,自己说“推理信息仅自己可见,需要在最后总结的时候把重要信息复述给读者”,效果比在最前文的 prompt 里效果好很多,可能是因为距离的原因,也可能是AI自己说出来的原因。另外,可以直接给到"Thought: do i need a tool?"去让 GPT 继续生成,从而一定进入推理链,可以匹配到远处描述思维链格式的 prompt 内容,极大的降低思考难度。
外网评价




End
崔庆才的新书《Python3网络爬虫开发实战(第二版)》已经正式上市了!书中详细介绍了零基础用 Python 开发爬虫的各方面知识,同时相比第一版新增了 JavaScript 逆向、Android 逆向、异步爬虫、深度学习、Kubernetes 相关内容,同时本书已经获得 Python 之父 Guido 的推荐,目前本书正在七折促销中!
内容介绍:《Python3网络爬虫开发实战(第二版)》内容介绍

扫码购买
好文和朋友一起看~