
神经网络模型特征重要性-谷歌解决方案
背景
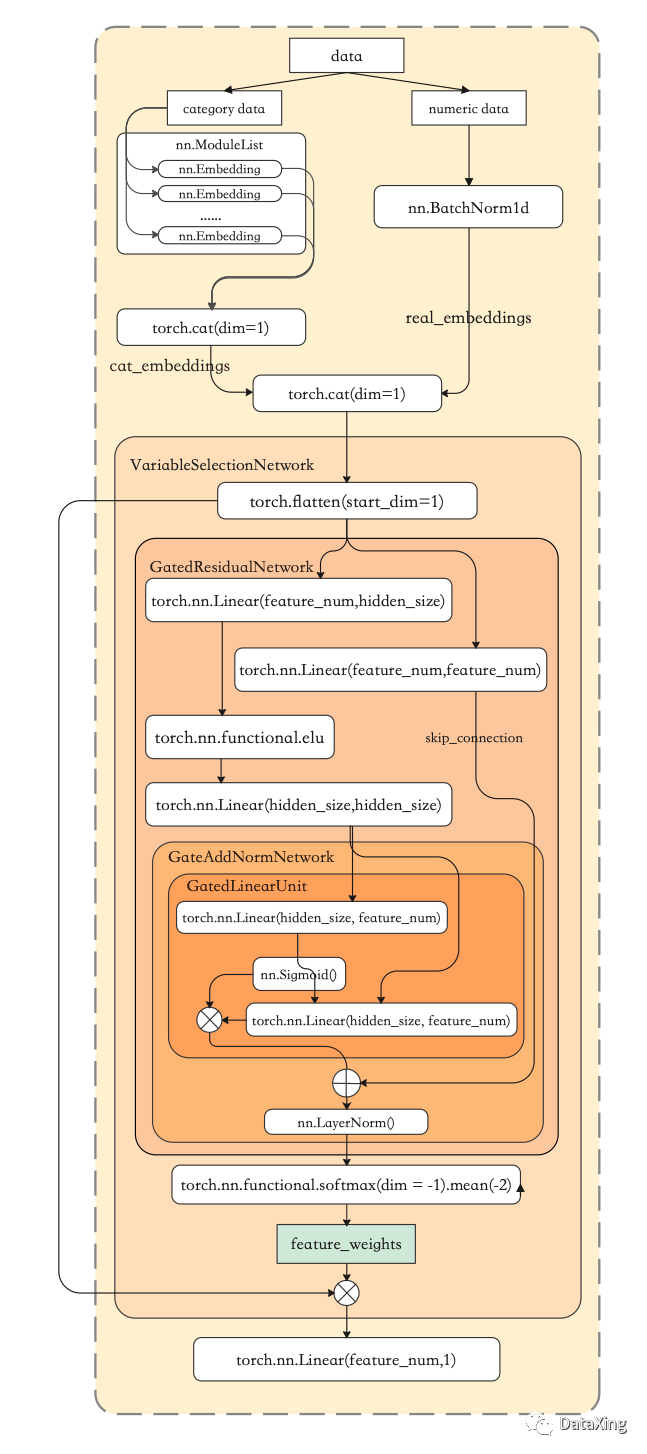
树模型的特征重要性是相对容易计算出来的,那么对于神经网络我们该如何得到其特征重要性呢?网上的方法包括permutation importance, null importance, 随机对特征进行mask等方法,本文要介绍的是牛津大学和谷歌提出的基于Gated Residual Networks (GRN) and Variable Selection Networks (VSN)的特征重要性计算方法。
使用GRN计算特征重要性的基本逻辑
1
提供特征列和target列,特征根据数据类型指定为数值型或离散型;
2
将数据划分为验证集和训练集;
3
在训练集上,根据第一步提供的列定义,对数值型特征分别进行归一化,对离散型特征进行embedding(相当于给每一列离散特征创建一个类别词典),然后将两者拼接后传给GRN模块,计算得到每个特征的权重,再将权重和前面拼接后的结果按元素相乘,最后接全连接层,获得预测结果,与真实值计算loss,迭代训练。
其中,GRN模块获取拼接输入后,分成两路,其中一路经过多层变换最后额外使用sigmoid激活函数作为“门”对变换结果进行选择性加权,另一路则作为residual connection直接与前者的输出相加,起到防止过拟合的作用。
4
取验证集得分最优的情况下各个特征的权重为特征的重要性。
使用案例
我们的开源项目AutoX把GRN计算特征重要性以及特征选择的函数进行了封装:
使用GRN_feature_selection进行特征重要性计算:
from autox.autox_competition.feature_selection import GRN_feature_selectionGRN_feature_selection = GRN_feature_selection()column_definition = {"cat":['investment_id'],"num":[]}for i in range(300):column_definition['num'].append((f'f_{i}'))GRN_feature_selection.fit(train[used], train[target], column_definition)# Train[used]是完成了包含所有特征的dataframe# Train[target]是标签列# column_definition中指定了特征的类型(特征属于类别型变量还是连续型变量)
查看所有特征的重要性:
GRN_feature_selection.feature2weight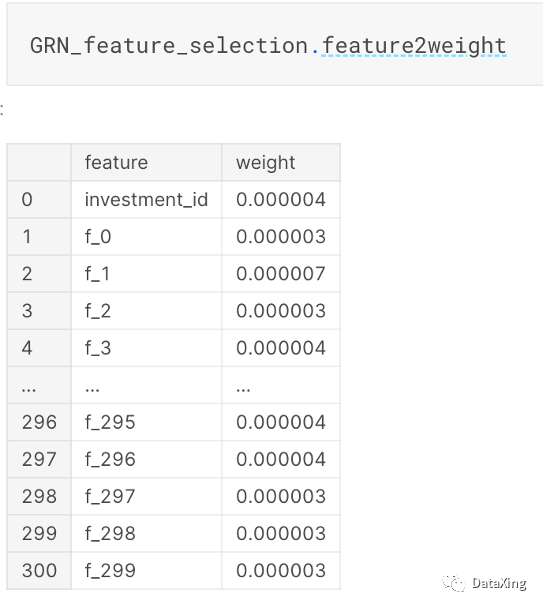
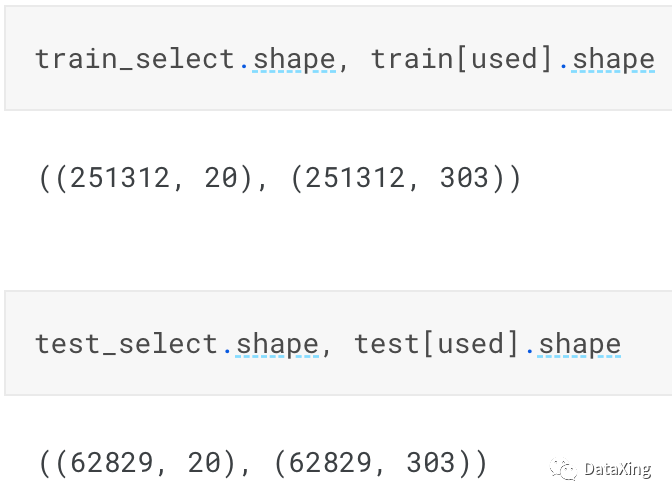
选择top_k重要性的特征:
train_select = GRN_feature_selection.transform(train[used], top_k=20)test_select = GRN_feature_selection.transform(test[used], top_k=20)
完整案例地址
https://www.kaggle.com/code/hengwdai/grn-featureselection-autox
开源项目地址
https://github.com/4paradigm/AutoX
参考资料
Lim B, Arik S O, Loeff N, et al. Temporal fusion transformers for interpretable multi-horizon time series forecasting[J]. arXiv preprint arXiv:1912.09363, 2019.
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: