
47分钟,BERT训练又破全新纪录!英伟达512个GPU训练83亿参数GP...
新智元报道
来源:英伟达
编辑:元子
【新智元导读】具有92个DGX-2H节点的NVIDIA DGX SuperPOD通过在短短47分钟内训练BERT-Large创下了新纪录。该纪录是通过每个节点上的1472个V100 SXM3-32GB 450W GPU和8个Mellanox Infiniband计算适配器,自动混合精度运行PyTorch来提高吞吐率,并使用本文中的训练方法来实现的。「新智元急聘主笔、编辑、运营经理、客户经理,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」
随着大量基于Transformer的语言模型的出现,例如BERT(来自Transformer的双向编码器表示)和10亿多个参数的GPT-2(Generative Pretrained Transformer 2)模型,语言理解任务得到了飞速的发展。
BERT引发了精确语言模型的新浪潮
BERT可针对许多NLP任务进行微调,非常适合进行例如翻译,问答,情感分析和句子分类等语言理解任务。BERT和基于Transformer架构的模型(例如XLNet和RoBERTa)在流行的基准测试(例如SQuAD(用于问答评估)和GLUE(用于跨多种语言的一般语言理解)上能够达到、甚至超过人类。
BERT的一个主要优点是,不需要使用带标签的数据进行预训练,因此可以使用任何纯文本进行学习。这一优势为海量数据集打开了大门,进而进一步提高了最新的准确性。例如,BERT通常在BooksCorpus(8亿个单词)和English Wikipedia(25亿个单词)的上进行预训练,以形成33亿个单词的总数据集。
模型复杂度是基于Transformer的网络的另一个属性,该属性提高了NLP的准确性。比较两种不同版本的BERT可以发现模型大小与性能之间的相关性:BERTBASE创建了1.1亿个参数,而BERT-Large通过3.4亿个参数,GLUE得分平均提高了3%。预计这些模型将继续增长以提高语言准确性。
NVIDIA Tensor Core GPU训练BERT只需47分钟
具有92个DGX-2H节点的NVIDIA DGX SuperPOD通过在短短47分钟内训练BERT-Large创下了新纪录!该纪录是在使用每个节点上的1472个V100 SXM3-32GB 450W GPU和8个Mellanox Infiniband计算适配器,使用自动混合精度运行PyTorch来提高吞吐率,并使用本文中的训练方法来设置的。对于仅访问单个节点的研究人员,配备16台V100的DGX-2服务器可在3天内训练BERT-Large。下表说明了为各种数量的GPU训练BERT-Large的时间,并显示了随着节点数量增加而进行的有效缩放:
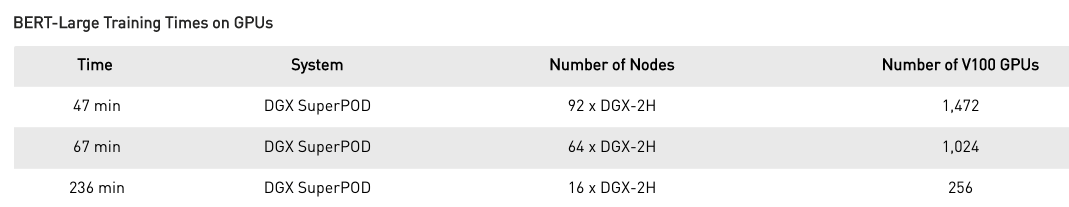
单个DGX-2H节点具有2 petaFLOP的AI计算能力,可以处理复杂的模型。大型BERT型号需要大量内存,并且每个DGX-2H节点为此运行的整个DGX SuperPOD群集提供0.5TB的高带宽GPU内存,总共46TB。NVIDIA互连技术(例如NVLink,NVSwitch和Mellanox Infiniband)可实现高带宽通信,从而实现高效缩放。GPU具有强大的计算能力以及对大量DRAM的高带宽访问以及快速互连技术的结合,使NVIDIA数据中心平台成为大幅加速诸如BERT等复杂网络的最佳选择。
GPT-2 8B:有史以来最大的基于Transformer的语言模型
基于Transformer的语言模型的另一类用于生成语言建模。这些模型旨在预测和生成文本(例如,在给出初始段落的文档中写出下一个句子)。最近,具有15亿参数的GPT-2模型表明,缩放到更大的生成尺寸,甚至比BERT使用的数据集更大的未标记数据集,都可以生成产生连贯且有意义的文本的最新模型。
爆炸性的模型复杂性–网络参数数量
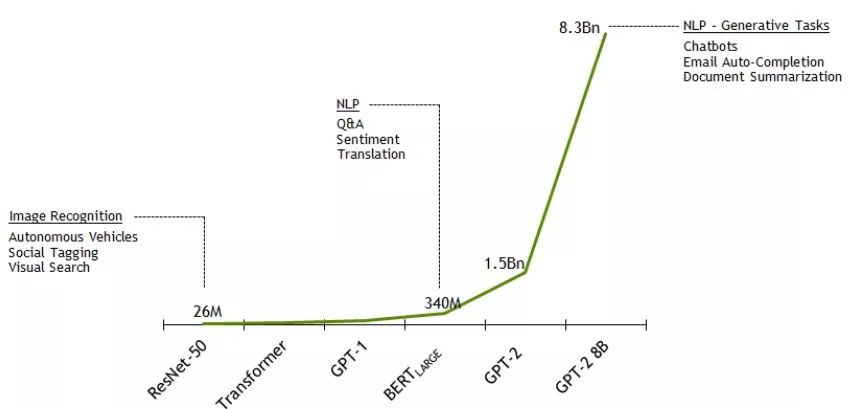 为了调查这些庞大的,超过十亿个基于Transformer的网络,NVIDIA Research推出了Project Megatron。这是为最先进的NLP创建最大的Transformer模型的努力。15亿参数的GPT-2模型已扩展为更大的83亿参数Transformer语言模型:GPT-2 8B。使用本地PyTorch在512 GPU上使用8路模型并行性和64路数据并行性对模型进行了训练。GPT-2 8B是有史以来最大的基于Transformer的语言模型,其大小是BERT的24倍,GPT-2的5.6倍。
为了调查这些庞大的,超过十亿个基于Transformer的网络,NVIDIA Research推出了Project Megatron。这是为最先进的NLP创建最大的Transformer模型的努力。15亿参数的GPT-2模型已扩展为更大的83亿参数Transformer语言模型:GPT-2 8B。使用本地PyTorch在512 GPU上使用8路模型并行性和64路数据并行性对模型进行了训练。GPT-2 8B是有史以来最大的基于Transformer的语言模型,其大小是BERT的24倍,GPT-2的5.6倍。实验是在NVIDIA的DGX SuperPOD上进行的,该模型的基线模型为12亿个参数,可安装在单个V100 GPU上。在单个GPU上运行此基线模型的端到端训练流水线可达到39 TeraFLOPS,这是该GPU的理论峰值FLOPS的30%。NVIDIA团队通过8路模型并行性在512个GPU上将模型缩放至83亿个参数,NVIDIA团队在整个应用程序中实现了高达15.1 PetaFLOPS的持续性能,与基准相比,缩放效率达到76%。
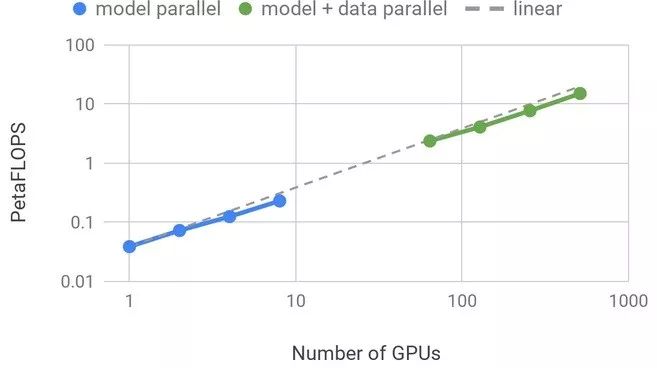
模型并行性固有地会带来一些开销,与可在单个GPU上运行且不需要任何模型并行性的BERT相比,它会稍微影响缩放效率。下图显示了缩放结果,有关技术细节的更多信息可以在单独的博客文章中找到。
计算性能和扩展效率
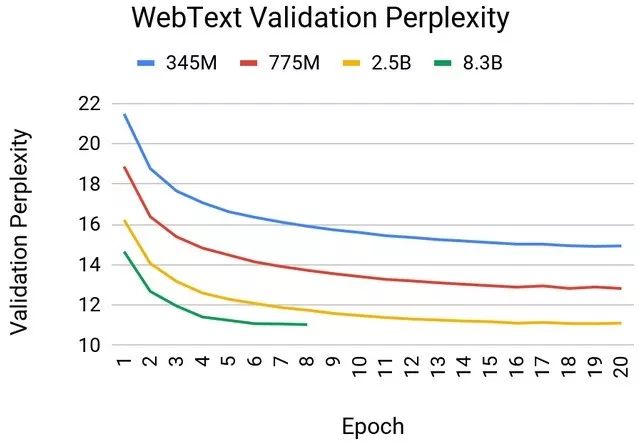
 GPT-2模型从Reddit链接下载的37GB WebText数据集上进行了训练。下图显示了WebText验证困惑度与不同模型大小的时期数的关系。从经验上我们发现,较大的模型训练更快,并导致更好的结果(较低的验证困惑度)。
GPT-2模型从Reddit链接下载的37GB WebText数据集上进行了训练。下图显示了WebText验证困惑度与不同模型大小的时期数的关系。从经验上我们发现,较大的模型训练更快,并导致更好的结果(较低的验证困惑度)。在wikitext-103数据集上评估模型时,会观察到类似的行为。与较小的模型相比,增加到83亿个参数导致准确性显着提高,并且维基文本的困惑度为17.41。这超过了Transformer-xl在Wikitext测试数据集上获得的先前结果。但是,最大的83亿参数模型在经过大约六个纪元的训练之后就开始过拟合,这可以通过移至更大规模的问题和数据集来缓解,类似于XLNet和RoBERTa等最新论文中所使用的模型。
Webtext验证困惑度与各种GPT-2模型大小的历程
 NVIDIA平台上会话AI的未来
NVIDIA平台上会话AI的未来诸如BERT和GPT-2 8B之类的基于Transformer的语言网络对性能的巨大要求,这种组合需要强大的计算平台来处理所有必需的计算,以提高执行速度和准确性。这些模型可以处理大量未标记的数据集,这一事实使它们成为现代NLP的创新中心,并因此成为使用会话AI应用程序的智能助手的选择。
带有Tensor Core架构的NVIDIA平台提供了可编程性,以加速现代AI的全面多样性,包括基于Transformer的模型。此外,DGX SuperPOD的数据中心规模设计和优化与软件库相结合,并且对领先的AI框架提供直接支持,为开发人员提供了无缝的端到端平台,以承担最艰巨的NLP任务。
NVIDIA加速软件中心NGC免费提供持续优化,以加速在多个框架上对GPU进行BERT和Transformer的培训。
NVIDIA TensorRT包括用于在BERT和大型基于Transformer的模型上运行实时推理的优化。要了解更多信息,请查看我们的“会话式AI的实时BERT推理”博客。NVIDIA的BERT GitHub存储库今天有代码来复制此博客中引用的单节点训练性能,并且在不久的将来,该存储库将使用复制大规模训练性能数据所需的脚本进行更新。
评论