
优化!1000元的Python副业单子,爬取下载美国科研网站数据
前情提要
此前已经结单的美国科研数据爬虫(详情见1000元的Python副业单子,爬取下载美国科研网站数据)虽然完结了,但是还是存在一些缺陷:
方案一爬取效率高,但是需要解析R关系,而R关系是手工整理的,且只整理到了2013年以前数据,2014年起的数据就无法解析了; 方案二是每次请求一行数据,虽然绕过了解析R关系,能够达成目标,但其最大的缺陷是运行时间太长了,爬虫部分整整运行了近6个小时,向服务器发送了近18万次请求。
以上缺陷是否可以进行优化呢?
本着精益求精的态度,花点时间将项目进行一下优化,看看能做到哪一步,Let's go!!!
优化方案思路
将上述方案一和方案二进行结合,在爬取全量数据时使用方案一,在解析R关系是使用方案二,那么就能大大的提高运行效率,具体如下:
已知批量获取的数据,从第2行开始,若与上一行数据相同,则返回的数据中将不包括相同数据,取而代之的是一个R关系的参数,此外,还有一个Ø参数,代表该行数据中,有部分列本身内容为空值;那么要解析批量数据,只需要推导出R与Ø两个参数所对应的规则; 推导规则只需要取得不同的R与Ø两个参数组合数据的行样例,以及其上一行数据,即可进行推导; 那么处理步骤应为: 1正常请求所有数据 -> 2汇总数据,取得R与Ø两个参数组合对应的样例行 -> 3以单行请求的方式获取样例行 -> 4解析样例行,推导出R与Ø参数组合与列的关系,制作成字典 -> 5正常解析第1步骤取得的所有数据行。
具体步骤
爬取全量数据
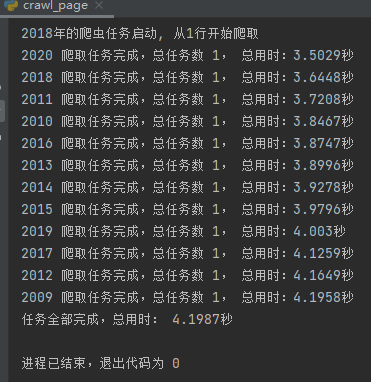
使用此前已经完成的crawl_page.py爬虫,nrows设置为20000行,即可一次请求完成该步骤,如下图:
汇总分析已爬取的数据(使用jupyter notebook进行探索)
obj1 = ParseData() # 创建方案一解析对象
# 使用方案1解析对象中的汇总功能,将爬取到的数据合并成一个dataframe
data = obj1.make_single_excel()
# R关系与Ø关系用0填充空值,并修改为整数形式
data['R'] = data['R'].fillna(0).astype(int)
data['Ø'] = data['Ø'].fillna(0).astype(int)
# 添加年份
data['year'] = data['year'].astype(int)
data.head()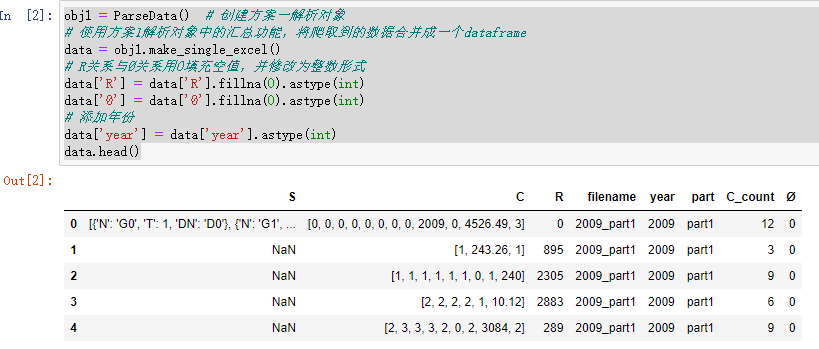
运行截图 # 删除不需要的列
data = data.drop(columns=['S', 'C', 'filename', 'part'])
# 按关系组合去重,保留第一条不重复的数据
data = data.drop_duplicates(['R', 'Ø'], keep='first')
# 列重新排序
data = data[['R', 'Ø', 'year']]
# 筛选去除0, 0 关系,该关系无需查询
data = data.loc[~((data['R'] == 0) & (data['Ø'] == 0))]
data
近18万行数据中,存在的关系组合共154种 整理获取不重复的关系组合 首先汇总已经爬取到的全量数据,代码如下: 要解析上述154种R和Ø的组合关系,那么需要这154行数据,以及其上一行数据,共308行数据进行比对解析,因此问题转变为如何取得这308行数据。
前期进行页面分析时,可知每个请求的第1行都是完整的数据,因此,只要定位到这154行的上一行位置,然后再请求2次单行数据即可获得需要的数据。因此修改了部分PageSpider代码,满足该需求:
class PageSpiderv2(PageSpider):
"""
继承并修改PageSpider对象的部分功能
"""
def make_params(self, year: int = None, nrows: int = None, key: list = None) -> dict:
"""
制作请求体中的参数
:param year: 修改Post参数中的年份
:param nrows: 修改Post参数中的count
:param key: 下一页的关键字RestartTokens,默认空,第一次请求时无需传入该参数
:return: dict
"""
params = self.params.copy()
if key:
params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][
'Primary']['Window']['RestartTokens'] = key
if year:
self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Query']['Where'][0][
'Condition']['In']['Values'][0][0]['Literal']['Value'] = f'{year}L'
if nrows:
self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][
'Primary']['Window']['Count'] = nrows
return params
def crawl_page(self, year: int, nrows: int, key: list = None):
"""
按照传入的参数单独爬取数据
:param year: 需要爬取的数据的年份
:param nrows: 需要爬取的数据的count值
:param key: 下一页的关键字RestartTokens,默认空,第一次请求时无需传入该参数
:return: None
"""
while True: # 创建死循环,直至爬取的结果是200时返回response
try:
res = requests.post(url=self.url, headers=self.headers, json=self.make_params(year, nrows, key),
timeout=self.timeout)
except Exception as e: # 其他异常,打印一下异常信息
print(f'{self.year} Error: {e}')
time.sleep(5) # 休息5秒后再次请求
continue # 跳过后续步骤
if res.status_code == 200:
return res
else:
time.sleep(5)
def write_data(data: dict, filename: pl.Path):
"""
将爬取到的数据写入TXT文件
:param data: 需要写入的数据
:param filename: 输出的文件名称
"""
with open(filename, 'w', encoding='utf-8') as fin:
fin.write(json.dumps(data))
return data
# 定义并创建存储爬取到的R和Ø组合关系的文件夹
relation_path = pl.Path('./tmp/relation')
if not relation_path.is_dir():
relation_path.mkdir()
"""
遍历不重复的R和Ø组合关系,逐一爬取数据,
爬取数据的逻辑是:
1.进行3次请求
2.第1次请求,根据index值取到R和Ø组合关系的上一行数据的RT值,
3.第2、3次请求,获取R和Ø组合关系的上一行与当前行,根据R和Ø组合关系创建文件夹,存储文件
"""
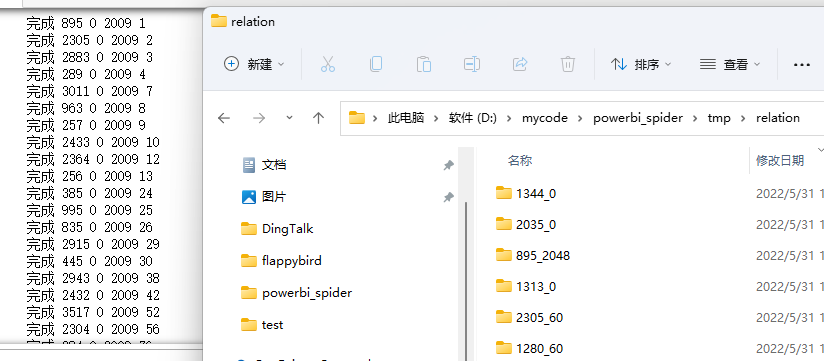
for idx in data.index:
r, q, year = data.loc[idx] # 拆包获取r,q,year数据
# 定义并创建R和Ø组合关系文件夹,文件夹名以R和Ø组合关系命名
out_path = relation_path / f'{r}_{q}'
if not out_path.is_dir():
out_path.mkdir()
# 第1次爬取,获取定位的RT值
req = PageSpiderv2(year)
res = json.loads(req.crawl_page(year, nrows=idx).text)
key = res['results'][0]['result']['data']['dsr']['DS'][0].get('RT')
# 第2、3次爬取,获取2行数据用于比对,解析R和Ø组合关系
for n in range(2):
res = json.loads(req.crawl_page(year, nrows=2, key=key).text)
res = write_data(res, out_path / f'{r}_{q}_{n}.txt')
key = res['results'][0]['result']['data']['dsr']['DS'][0].get('RT')
print('完成', r, q, year, idx)
整理数据推导出R与Ø参数组合与列关系:
# Ø参数的空列数值字典
blank_col_dict = {
60: ['Manufacturer Full Name', 'Manufacturer ID', 'City', 'State'],
128: ['Payment Category'],
2048: ['Number of Events Reflected']
}
# 创建方案二的解析对象
obj2 = ParseDatav2()
# 初始化定义relation_df,第一行为R和Ø组合为0值,所有列均为1
relation_df = pd.DataFrame(['R', 'Ø'] + obj2.row.columns.tolist()[:-1])
relation_df[1] = 1
relation_df.set_index(0, inplace=True)
relation_df = relation_df.T
relation_df[['R', 'Ø']] = [0, 0]
relation_df

# 遍历爬取到的R和Ø组合数据文件夹,解析R和Ø组合关系
for r_dir in relation_path.iterdir():
r_files = list(r_dir.iterdir())
r, q = r_dir.stem.split('_')
res0 = obj2.parse_data(r_files[0])
res1 = obj2.parse_data(r_files[1])
# 两行数据对比,当不一致时是1,否则是0
res = res0 != res1
# 获取Ø关系的空列
blank_cols = blank_col_dict.get(int(q))
# 如有空列数据,则将对应列值清除
if blank_cols:
res[blank_cols] = False
res[['R', 'Ø']] = [r, q]
res = res[['R', 'Ø'] + obj2.row.columns.tolist()]
res = res.drop(columns='idx')
relation_df = pd.concat([relation_df, res])
# 整理组合关系dataframe
relation_df[['R', 'Ø']] = relation_df[['R', 'Ø']].astype(int)
relation_df.sort_values(by=['R', 'Ø'], inplace=True)
relation_df.set_index(['R', 'Ø'], inplace=True)
# 输出关系字典
relation_df.to_csv('./cols_dict.csv', encoding='utf-8')
relation_df
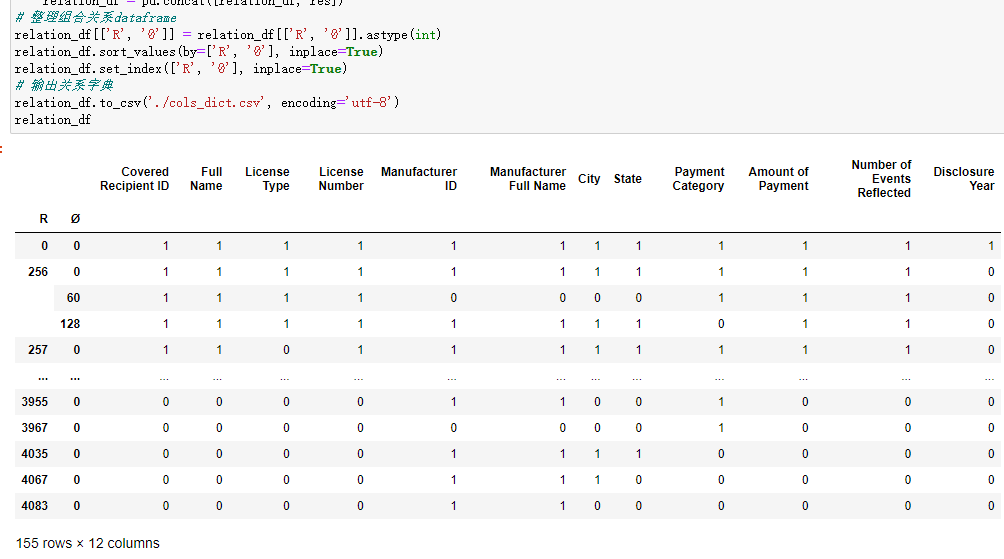
使用解析得到R和Ø的组合的关系,解析输出CSV文件
该步骤因相比第一版增加了Ø关系,因此有对ParseData对象的方法进行了部分修改,具体详见代码,运行示例如下:

总结
本次流程优化主要就是希望提高数据处理的效率,优化后:
全量数据请求,用时仅秒级,可以忽略不计; 在获取R和Ø的组合关系上,使用单线程请求,用时8分多钟:
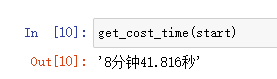 3. 解析输出文件5分多种
3. 解析输出文件5分多种
总用时,在15分钟以内,与方案二的时间近6个小时相比,效率提升极为明显:
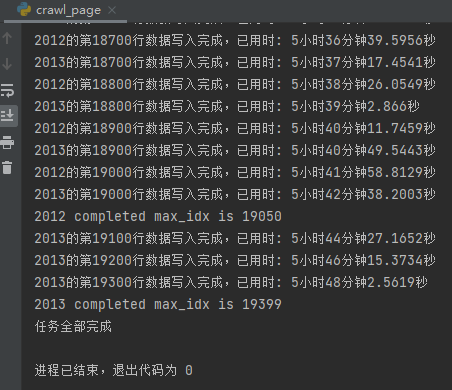
同时在本次流程优化中并没有使用到太多新的技术,没能JS逆向解析出关系规则,还是没能解析,但是通过灵活使用参数,组合不同方案优势,还是能够极大的提升运行效率。
回过头来看,如果在接单的初期,在尝试JS逆向失败后,要是能够直接想到这个解决方案,那么5个小时的人工查询R关系时间,5个小时的单行爬虫运行时间,可以节约的时间大大的有啊!!!嗯,下次一定要提醒自己,要多打开思路,多尝试不同的方向思考,不要一条道走到黑,也许换个方向就能取得突破。总而言之,方法总比困难多,还是多思考,多尝试,多积累经验吧!!!
扫码下方,购买蚂蚁老师课程
提供答疑服务,和副业渠道
抖音每晚直播间购买,便宜100元优惠!
