
超越StyleGAN!TransGAN更新!用纯Transformer构建高分辨率GAN | 附代码

文末附代码 + 论文地址 + 小彩蛋
CV 研究者对 transformer 产生了极大的兴趣并取得了不少突破。这表明,transformer 有可能成为计算机视觉任务(如分类、检测和分割)的强大通用模型。我们都很好奇:在计算机视觉领域,transformer 还能走多远?对于更加困难的视觉任务,比如生成对抗网络 (GAN),transformer 表现又如何?
在今年年初的时候,德克萨斯奥斯汀分校的团队推出了使用纯Transformer构建 Generative Adversarial Network并且在Cifar-10, STL-10, CelebA (64 x 64) 等常见benchmark中取得了不错的成绩。这几个月以来,不同的研究人员都是用Transformer各个方向取得了极大的进展,Vision Transformer的研究获得了计算机社区的广泛关注。最近,TransGAN团队更新了他们的结果,最新的结果表明,TransGAN不仅在低分辨率图像任务中超越了StyleGAN,在更高分辨率(如256x256)图像生成任务中也取得了优异的成绩。

使用Vision Transformer搭建GAN网络不仅来源于对探索Transformer在视觉任务中表现力的好奇,同时也期望解决卷积神经网络(CNN)长久以来面临的多种缺陷。例如,局部感受野不利于捕捉全局信息,以及空间不变性不利于获取随空间位置改变的特征。
首先让我们简单了解一下适用于高分辨率图像生成任务的TransGAN具体结构
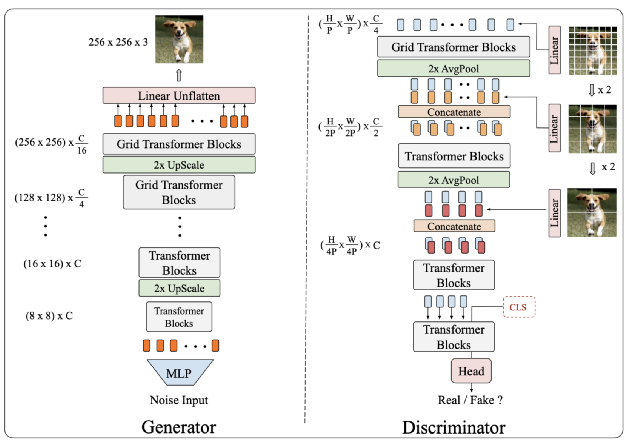
TransGAN包含了一个内存友好的基于 transformer 的生成器和一个多尺度金字塔结构的判别器。其中,生成器采用逐级放大分辨率的方式减小计算量,每一个层级之间采用了上采样模块来提高分辨率。在低分辨率层级中,研究人员采用了简单的Bicubic Upsample,保持模型的宽度而仅放大分辨率,在高分辨率层级中(分辨率大于32x32),则采用Pixelshuffle模块,使得分辨率放大的同时模型宽度减小为原来的1/4。
对于判别器而言,文章采用了多尺度输入的极联判别器,而不是与原始ViT相同的结构。这是因为当分辨率继续上升时,继续将每一张图片视为多个块状图片的组合会面临多种问题。具体而言,当切割的块状图片大小较小时,判别器能够更有效地处理图片的细节和纹理信息,然而,较小的块状图片将导致总块数长度较大,这将造成极大的计算量消耗。另一方面,虽然使用较大的块状图片可以捕捉到丰富的结构信息并解决计算量的问题,每一张块状图片捕捉到细节信息将会损失,不利于生成细节更丰富的图片。为了解决这个问题,研究人员提出来多尺度判别器,通过将输入图片切割成不同大小的块状图片来同时捕捉纹理信息和结构信息。与此同时,判别器采用了金字塔结构,不断地降低特征的分辨率以获取更高的计算效率。
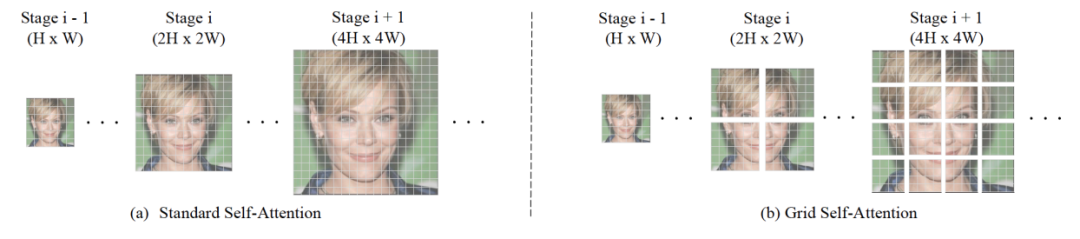
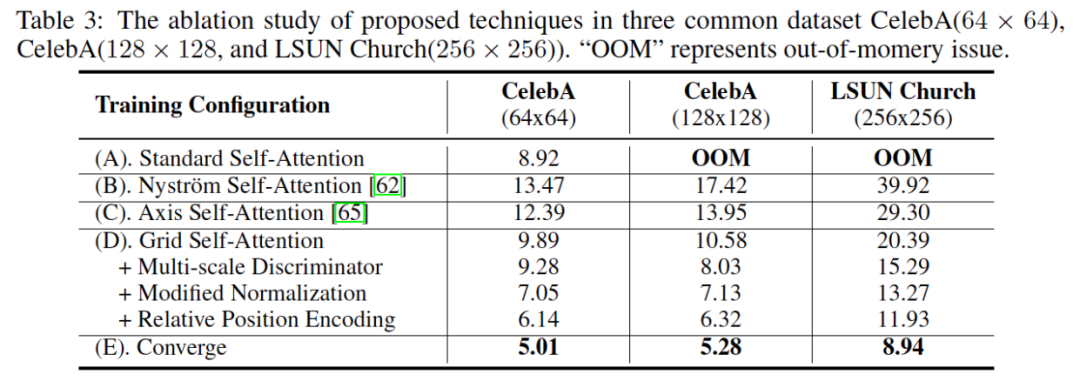
为了将TransGAN应用于更高的分辨率,文中提出了采用Grid Self-attention来替换standard self-attention。研究人员发现原始的self-attention虽然能捕捉全局信息,但是在更高的分辨率上这一优点反而成了累赘。这是由于从低分辨率高分辨率图像时只需要在局部区域捕捉并生成细节信息。文中提出的Grid Self-Attention通过不重叠的窗口将原始特征图分割成同一大小的小图,并只在小图中使用self-attention,这种方法极大地降低了self-attention的计算消耗和显存消耗。文中同时讨论了Grid Self-attention可能带来的潜在问题,如分割的小图之间因为信息交互被阻碍而导致的边界损失。实际上,研究人员发现在足够的训练时间下,这种边界损失会逐渐消失,这是由于判别器的感受野覆盖了整张图片,从而驱动生成器生成不包含边界损失的图片。
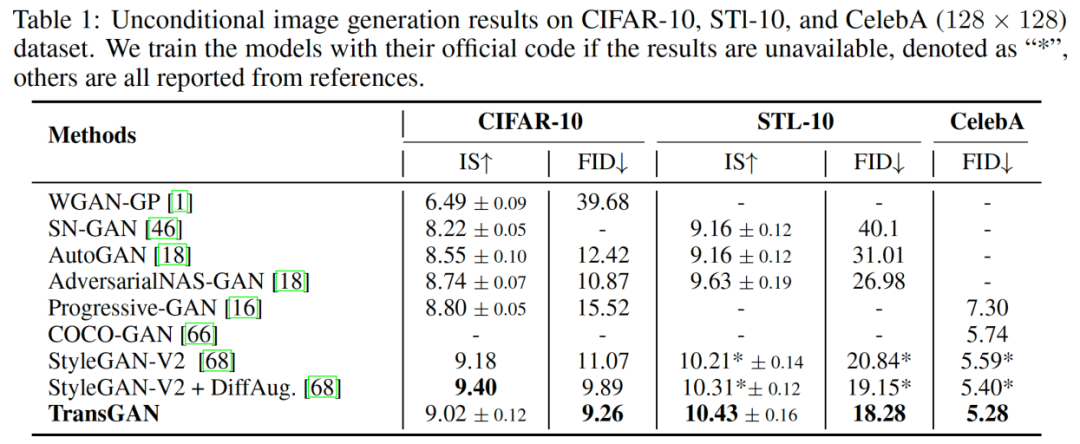
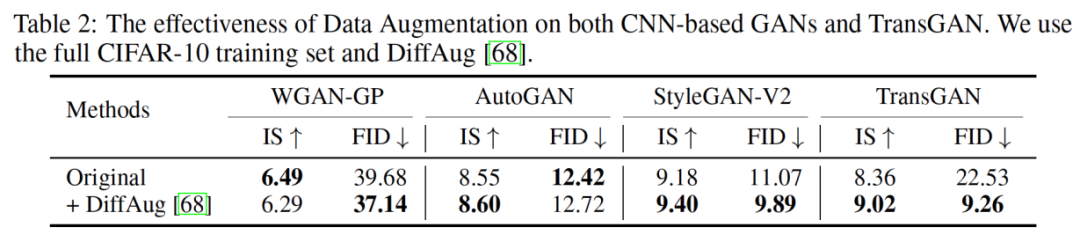
尽管上文描述的生成器和判别器在设计上拥有多种优势,训练由纯Transformer构建的GAN依旧不是一件轻而易举的事,这主要是因为GAN和Transformer都面临着训练及其不稳定的问题。对此,研究人员提出了一系列训练技巧,包括数据增强,相对位置编码,以及改进的归一化结构。最终,在同样使用数据增强的设定下,TransGAN在Cifar-10,STL-10,以及Celeba (128 x 128)等常用benchmark中取得了最好的成绩,并超过StyleGAN-v2等结构。

同时,实验结果表明提出的各种模块的优越性
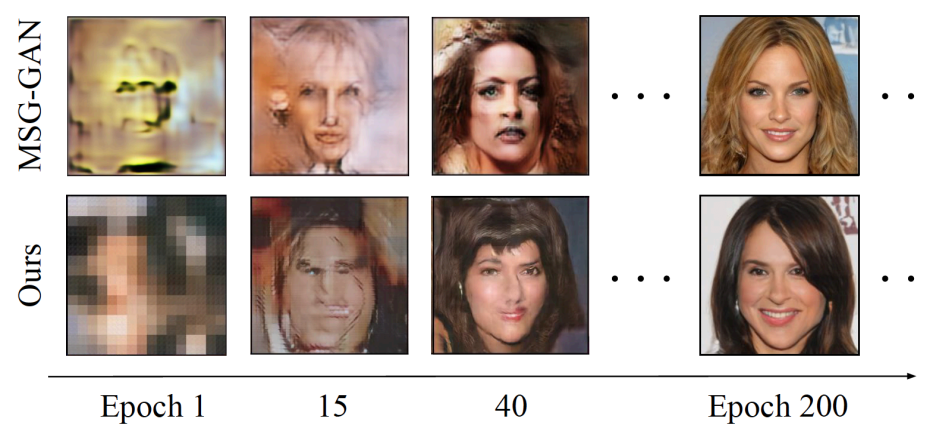
在将应用TransGAN于更高分辨率时,TransGAN继续保持了优越的性能并且生成了细节丰富的高清图像

通过观察比较基于Transformer和卷积神经网络的GAN,研究人员发现,Transformer在训练早起并不能有效生成有意义的图片,例如人脸的五官,这可能是由于缺失了卷积神经网络具备的归纳偏置。但是,在足够的数据和训练下,Transformer逐渐学习到有意义的位置信息和归纳偏置,最终生成细节丰富的高清图片。
在总结中,研究人员表示将继续将纯Transformer应用于更多数据集和更高的分辨率当中。
论文地址:https://arxiv.org/abs/2102.07074
代码地址:https://github.com/VITA-Group/TransGAN

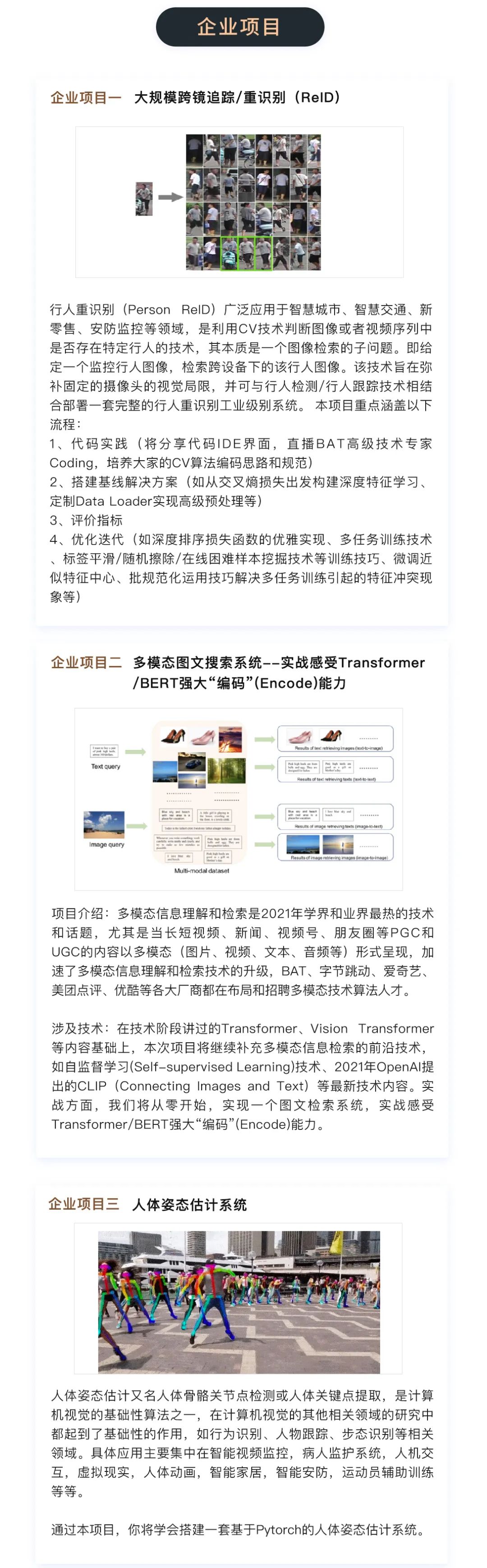
七月在线 【CV高级小班 第八期】将在今晚8:00开班!
如果你打算转行CV,或者你已经有一定基础想要挑战高薪,可以扫描下方二维码试听课程(仅限10人)!
本期CV高级8,继续沿用上一期完整的“作业考试且批改”的教学机制,且在内容、项目、就业三个维度上做了全新升级。
一切为了学员学的更好,最终更好的高薪就业、或跳槽涨薪/升职加薪。
618活动期间报名,还加送价值万元【三年VIP&三年GPU】及【深度学习集训营】。
以下是课程大纲 ↓↓
向下滑动查看更多




学员评价
就业信息
扫码立即试听👇👇
戳↓↓“阅读原文”抢占试听名额!