
TransGAN:两个Transformer可以构造一个强大的GAN
01
GAN
不写GAN的优化公式,看起来更迷糊,直接把GAN的训练过程阐述一下就清清楚楚了。
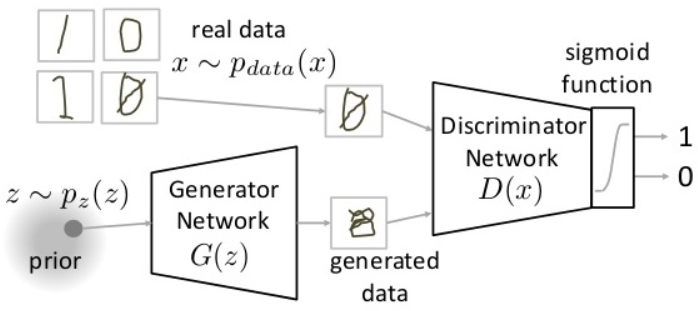
GAN由一个生成器G和一个判别器D构成。随机输入通过G得到生成图片,然后将真实图片和生成图片都送入判别器D中进行判断。
GAN的训练过程:
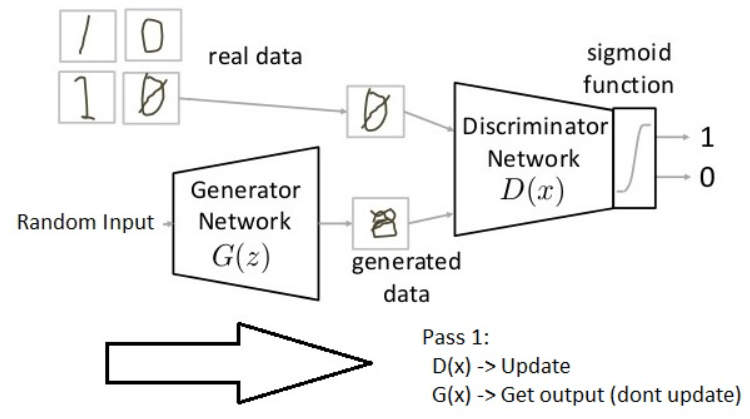
第一步先将生成器G参数固定住,然后将随机输入通过生成器G得到生成图片,最后更新判别器D的参数,将真实图片尽可能的判别为1,将生成图片尽可能的判别为0。(即需要得到更强判别力的判别器)
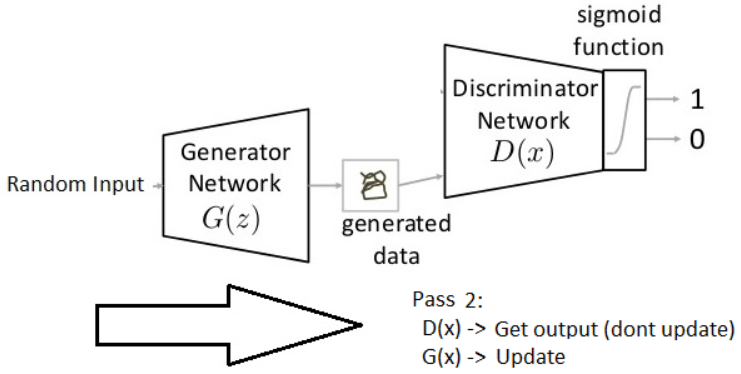
第二步先将判别器D参数固定住,然后将随机输入通过需要更新参数的生成器G得到生成图片,最后通过固定参数的判别器D尽可能的将生成图片判别为1。(即需要得到当前判别器认为的更接近真实图片的生成图片)
然后循环上述两个步骤,生成器G能够产生越来越接近真实图片的生成图片。
02
TransGAN
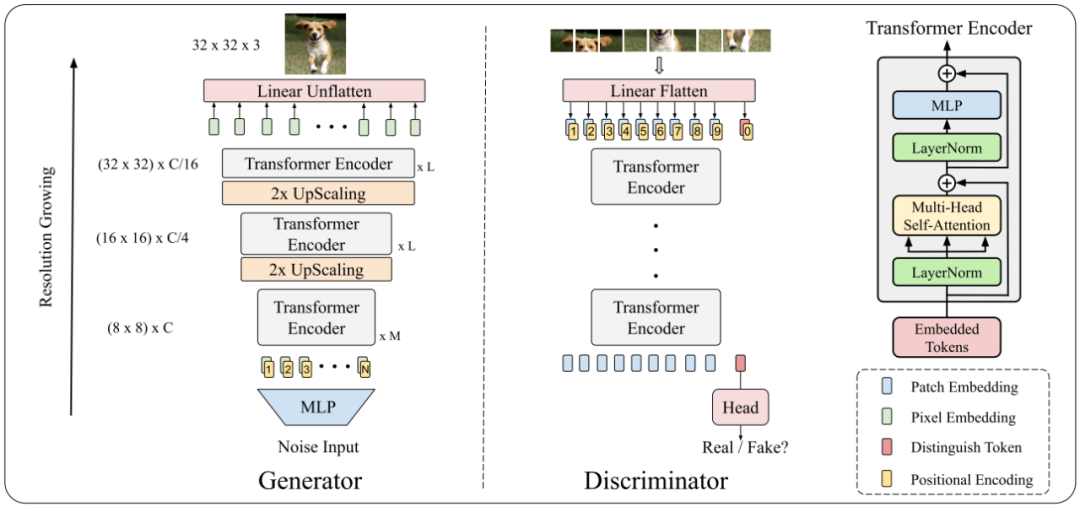
TransGAN整体的原理与GAN相同,主要的不同是Generator和Discriminator都是用Transformer构造的。
Memory-Friendly Generator
Generator的设计是显存友好的,由多个stage组成,每个stage由几个Transformer Encoder堆叠形成。随着stage的增加,不断的增加feature map的分辨率,直到和目标分辨率相同。以左图为例,将随机noise作为输入,通过多个MLP转化成长度为8x8xC的向量,然后将向量reshape成8x8分辨率的feature map,每个点的embedding维度为C。随后将64个维度为C的tokens和可学习的positional encoding相加,送入Transoformer Encoder。为了逐渐得到更大分辨率的feature map,在每个stage之后插入一个UpScaling操作(除了最后一个stage)。最后一个stage后面接一个Linear Unflatten将每个token的维度转化为3,然后reshape成二维RGB图片(左图最终的目标维度为32x32x3)。
其中UpScaling操作由两个reshape和一个pixelshuffle组成。先reshape将一维tokens序列重新组成二维feature map(假设维度维HxWxC),然后通过一个pixelshuffle操作将二维的feature map维度变成2Hx2WxC/4,最后再reshape成4HW个tokens序列,每个token的维度为C/4。
Tokenized-Input For Discriminator
Discriminator部分如右图所示。先将输入图片拆分成8x8个patches,然后通过Linear Flatten转化成64个维度为C的token embeddings,然后加上可学习的positional encoding,并且在tokens序列增加一个[cls] token,最后在[cls] token对应的输出位置增加head来判断是否为真实图片。
Evaluation Of Transformer-Based GAN
简单说明一下GAN的评估指标IS和FID。IS指标可以用来衡量生成样本的多样性和准确性。FID指标可以用来衡量真实样本和生成样本特征空间的距离。所以IS指标越大越好,FID指标越小越好。
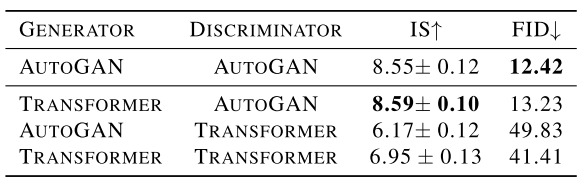
作者通过AutoGAN和Transformer的排列组合,发现Transformer+AutoGAN的IS最好,AutoGAN+AutoGAN的FID最好,说明Generator使用Transformer是有效的,但是Discriminator使用Transformer会损害GAN的性能。
Three Tricks
那么能不能Generator和Discriminator都使用Transformer,并且提升GAN的性能呢?作者通过三个tricks来进一步的进行探索。
Data Augmentation is Crucial for TransGAN
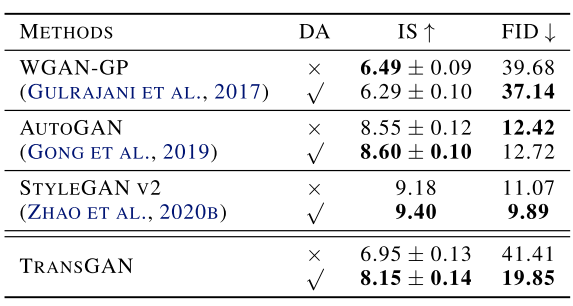
作者对三个CNN-based GAN和TransGAN进行数据增强的实验,发现数据增强对于TransGAN的收益是最大的。
Co-Training with Self-Supervised Auxiliary Task
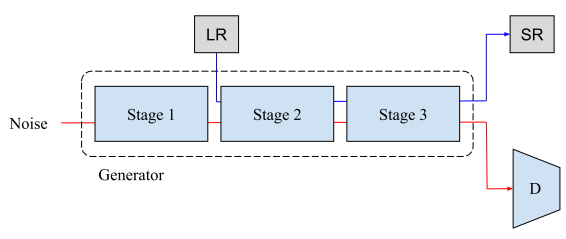
作者在TransGAN中增加了超分任务的辅助训练,具体的是在stage2同时输入低分辨率的图片,然后stage3同时输出高分辨率的图片。
Locality-Aware Initialization for Self-Attention
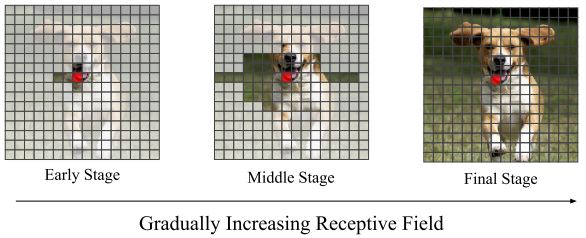
作者还提出了一个随着训练epoch的增加逐渐增加Self-Attention感受野的trick,具体的在训练早期Self-Attention操作mask掉大部分区域(即红点query做相关性计算的key范围是非mask区域),这些mask的部分不进行计算,然后训练中期mask区域逐渐减小,直到训练末期不进行mask。

作者进行消融实验发现辅助训练和Self-Attention局部初始化都能稳定提升TransGAN的性能。
03
实验结果
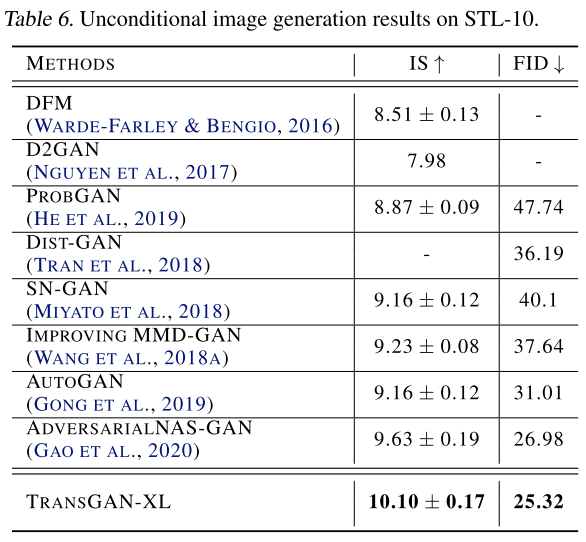
最终TransGAN在STL-10数据集上达到SOTA性能,在cifar10和CelebA数据集上达到和SOTA接近的性能。

最终可视化TransGAN的结果,生成图像的质量还是非常细腻的。
总体上TransGAN把基于Transformer的GAN做work了,同时提出了3个有效的tricks,效果跟之前最好的方法相当。
Reference
[1] Generative Adversarial Networks | Generative Models (analyticsvidhya.com)
[2] TransGAN: Two Transformers Can Make One Strong GAN
✄------------------------------------------------
双一流大学研究生团队创建,一个专注于目标检测与深度学习的组织,希望可以将分享变成一种习惯。
整理不易,点赞三连!