
(附代码)三行代码就能可视化Transformer
点击左上方蓝字关注我们

转载自 | 视学算法
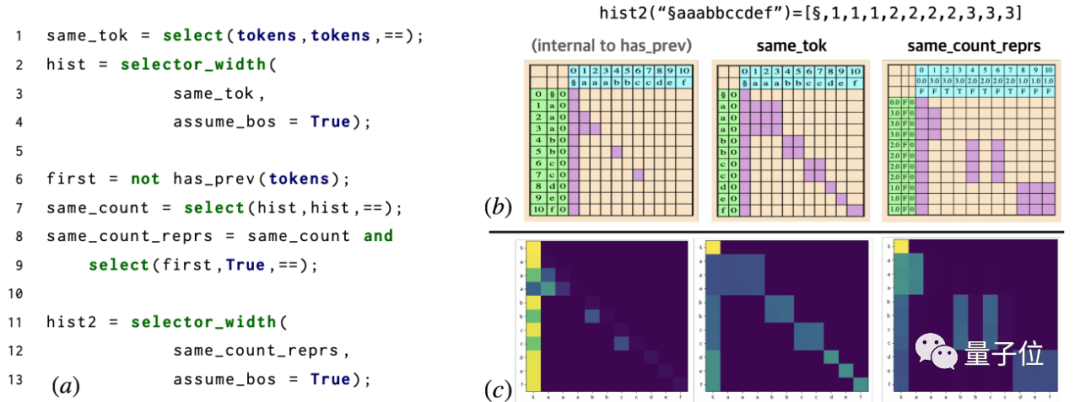
△RASP代码被编译成一个两层三头的Transformer架构。
这就是RASP,以色列科学家最新研发的一种简单的序列处理语言。
他们希望通过这一语言去计算和解决更高层次的抽象问题。
热心网友立马点赞:
我爱这篇论文,因为我在阅读机器学习论文时老是有“可视化Transformer”的想法,现在终于可以拿这个去玩儿了。而且用的都是一些简单的高阶函数,估计移植到Python或者放在Jupyter上跑也不难。

那么,这个叫做RASP的语言到底如何“像Transformer一样思考”的呢?

这门新方法是怎么形成的
让我们先追溯到上个世纪,RNN被抽象成为有限状态自动机(Finite State Automata)这一计算模型的例子。
这一例子说明了RNN与自动机之间存在着非常直观的相似性。
经过这种抽象之后,围绕RNN架构的变体或训练模型就展开了更为直观的讨论和思考。
而Transformer就不够直观,因为它在处理序列时拥有独特的信息流约束。

到了2020年,出现了基于Transformer提出的可以识别Dyck-k语言的构架。
这时的Transformer网络在一阶段的逻辑公式中作为输入时,能够学习并展现出一种多步骤的逻辑推理。
这就对研究团队产生了启发:能不能编写一种程序,对输入表达式也进行类似的逻辑推理呢?
RASP(Access Sequence Processing Language)就这样诞生了。

将Transformer编码器的基本组件:注意力(attention)和前馈计算层(feed-forward computation)映射到简单的原语(primitives)中,然后围绕它们形成一种新的编码语言。
这就是RASP,全称限制性访问序列处理语言。
当然,你也可以将RASP认为是一种Transformer结构的计算方法:
将Transformer网络的技术细节抽象而出,使其支持符号化程序,然后“编译”到Transformer硬件上,再定义一系列的注意力和多层感知器操作。
这就是像Transformer一样思考。
怎样一个计算模型
好,现在来看看这个RASP到底是由什么构成的:
内置的序列操作符(built-in s-ops)
在RASP中编程的目标就是将这些序列操作符组合成起来,去计算最终的目标任务。
元素性操作(Elementwise Operations)
反映了Transformer的前馈子层。
其他操作
所有除元素性操作之外的操作,比如宽度选择(selector_width operation)。
而Transformer的核心是什么?注意力机制。
RASP允许每个输入定义选择一种注意力模式,再通过加权平均,将输入值混合成一个新的输出。
那么它是如何进行编译呢?
当你输入这样3行代码:

RASP就能将序列操作符和输入对的编译流程可视化:
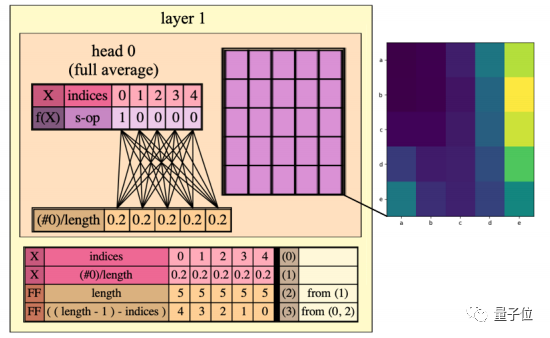
可以看到,第一层的头并不均匀地关注整个序列,而是在序列的最后位置上展示出了偏向性。
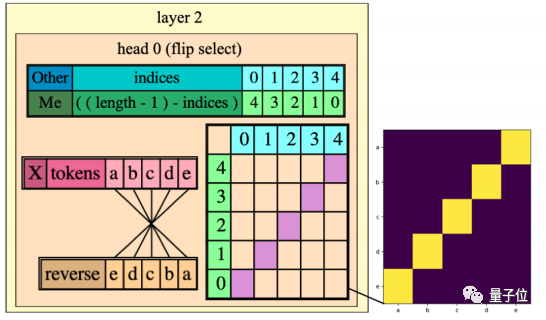
而Transformer第二层的注意头与程序中的反转选择器(flip selector)的行为完全对应:
表现怎么样?
RASP能够有效地预测一个Transformer解决某任务所需的最大层数和头数吗?
研究者在每个任务上训练4个规定大小的Transformer,然后测试它们的准确性:结果是大多数Transformer都达到了99.5%以上的准确率。
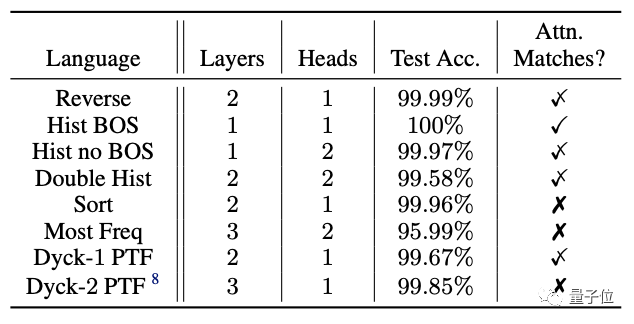
这让RASP可以作为一种用来推断Transformer擅长哪些任务,或其架构如何影响这些任务的工具。
而在根据RASP预测尺寸训练的Transformer减少它的头数和层数时,准确率会发生大幅下降**。
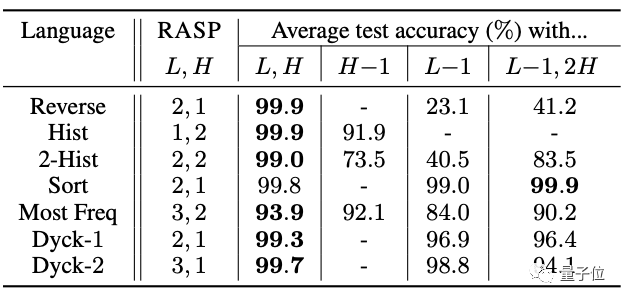
△用L、H表示编译的RASP程序所预测的层数和头数。
这也表示RASP拥有非常严格的约束性,在边界的紧密性(Tightness of the bound)上达到了极高的精度。
团队介绍
论文一作Gail Weiss是以色列理工学院的博士生,目前在学院内的计算机科学系中工作。

其中二作Yoav Goldberg来自以色列的巴伊兰大学,目前就职于艾伦人工智能研究院(Allen Institute for Artificial Intelligence)。

论文地址:
https://arxiv.org/abs/2106.06981
下载:
https://github.com/tech-srl/RASP
参考链接:
https://news.ycombinator.com/item?id=27528004
END
整理不易,点赞三连↓