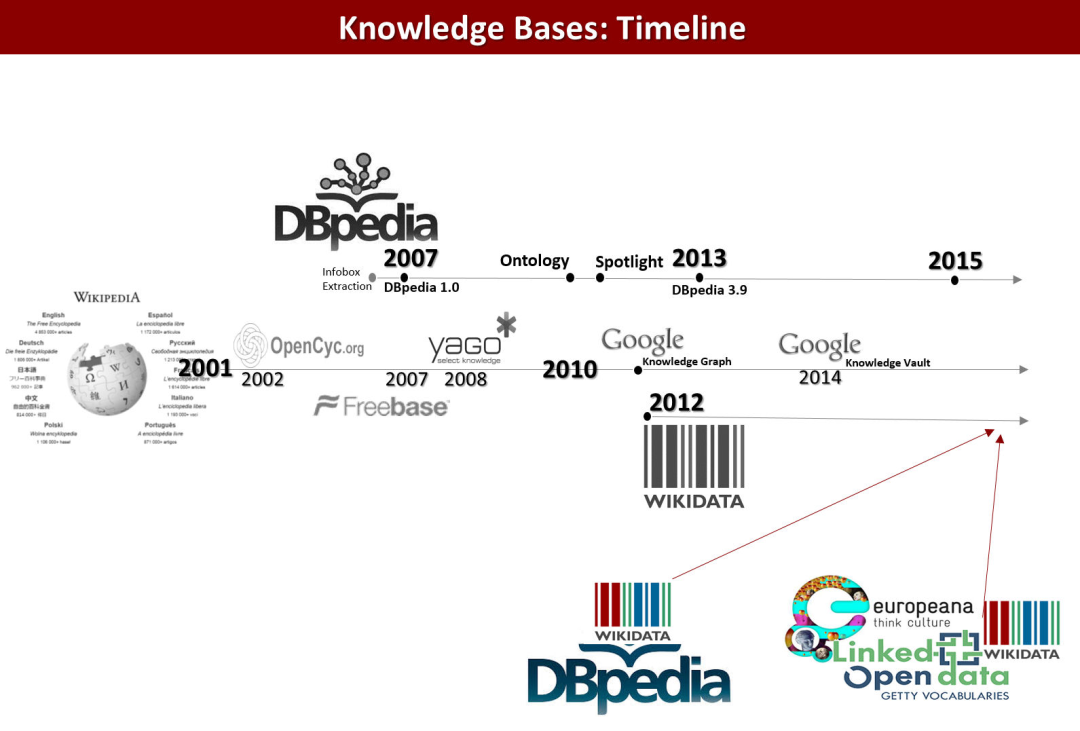
多语言互通:谷歌发布实体检索模型,涵盖超过100种语言和2000万个实体新智元关注共 1526字,需浏览 4分钟 ·2020-11-13 08:15 新智元报道 编辑:QJP【新智元导读】实体链接(Entity linking)通常在自然语言理解和知识图谱中起着关键作用。谷歌AI研究人员近期提出了一种新的技术,在这种技术中,可以将特定语言解析为与语言无关的知识库。如果一段文本中提到一个实体 ,算法将识别出该实体在知识库中的相应条目(例如一篇维基百科文章)。谷歌最近提出了一个单一实体检索模型,该模型涵盖了100多种语言和2000万个实体,表面上表现优于有限的跨语言任务。多语言实体链接涉及将某些上下文中的文本片段链接到与语言无关的知识库中的对应实体。 知识库本质上是包含实体信息的数据库,包括人、地点和事物等。2012年,谷歌推出了一个知识库的新概念:知识图谱,以提高搜索结果的质量。 这个知识库收集了来自 Wikipedia, Wikidata 和 CIA World Factbook 的数千亿事实。微软也曾推出一个知识库,其中有超过150,000篇文章是由为客户解决问题的支持专业人员创建的。多语种实体链接中的知识库可能包括一种或多种语言中关于每个实体的名称和说明等文本信息。但是他们并没有对这些知识库语言和其他语言之间的关系做出预先的假设。谷歌的研究人员使用了所谓的增强型双编码器检索模型(enhanced dual encoder retrieval models )和 WikiData 作为他们的知识库,这些知识库包括大量不同的实体。WikiData 包含名称和简短的描述,通过与所有维基百科版本的紧密联系,它还将实体连接到从相应语言的维基百科页面提取出来的描述和其他特性当中。 研究人员从104种语言的与 WikiData 实体相关的大规模数据集中提取了6.84亿个 mention ,他们说这个数据集至少是以前只用英语进行实体链接工作时使用的数据集的六倍。此外,两位作者还创建了一个匹配数据集: Mewsli-9,该数据集横跨多种语言和实体,其中包括 WikiNews 的58717篇新闻文章中提到的289087个实体。在 Mewsli-9的82,162个不同的目标实体中,只有11% 没有维基百科的英文页面,这为专注于英文维基百科实体的系统设置了一个上限。研究人员表示,实体链接能够更好地反映稀有实体或低资源语言在现实世界中面临的挑战。 通过对 Wikipedia 和 WikiData 的操作,使用增强双编码检索模型和基于频率的评估实验提供了令人信服的证据,证明用一个涵盖100多种语言的单一模型来执行这项任务是可行的。谷歌通过自动提取的 Mewsli-9 数据集作为一个起点,用于评估超越根深蒂固的英语基准和扩大的多语言环境下的实体链接。不过,研究人员目前对于模型是否能够显示出统计学偏差还不清楚。在今年早些时候发表的一篇论文中,Twitter 研究人员声称已经在流行的命名实体识别模型中发现了带有偏见的证据,尤其是对黑人和其他「非白人」名字的偏见。但是谷歌的合作者们通过使用非专家的人工评分员来为提高训练数据集的质量和合并关系知识敞开了大门。参考链接:https://venturebeat.com/2020/11/11/googles-ai-lets-users-search-language-agnostic-knowledge-bases-in-their-native-tongue/ 浏览 40点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 Yahoo FEL多语言实体链接工具包FastEntityLinker用于训练模型,以将实体链接到文档和查询中的知识库(维基百科),是一款无监督、准确、可扩展多语言实体名称识别和链接系统,同时包含英语、西班牙语和中文数据包。在算法上,使用Yahoo FEL多语言实体链接工具包Fast Entity Linker 用于训练模型,以将实体链接到文档和查询中的知识库(维基百科),短实体,长句实体抽取机器学习AI算法工程0StarSpace实体嵌入通用神经网络模型StarSpace 是用于高效学习实体嵌入(Entity embeddings) 的通用神经模型,可StarSpace实体嵌入通用神经网络模型StarSpace是用于高效学习实体嵌入(Entity embeddings)的通用神经模型,可解决各种各样的问题:学习单词、句子或文档级嵌入文本分类或其他标签任务信息检索:实体/文件或对象集合的排序Dos.ToolsDos.ORM实体生成器Dos.ORM的实体生成器!成熟轻量级ORM、上手简单、性能高、功能强大!UnamperXML 实体解码器Unamper 是纯Swift实现XHTML,HTML,和XML的实体解码器。XHTML,HTML,和XML实体解码let string = ""Peas & Car书生·浦语多语言大型语言模型InternLM(书生·浦语)是在过万亿 token 数据上训练的多语千亿参数基座模型。通过多阶段的书生·浦语多语言大型语言模型InternLM(书生·浦语)是在过万亿token数据上训练的多语千亿参数基座模型。通过多阶段的渐进式训练,InternLM基座模型具有较高的知识水平,在中英文阅读理解、推理任务等需要较强思维能力的场为 Gopher 打造 DDD 系列:领域模型-实体Go语言精选0点赞 评论 收藏 分享 手机扫一扫分享分享 举报






 下载APP
下载APP