
数据分析之AB testing实战(附Python代码)

作者 | Huang supreme
编辑 | JackTian
微信公众号 | 杰哥的IT之旅(ID:Jake_Internet)
作者介绍:
大家可以叫我黄同学(博客名:Huang Supreme),一个应用统计硕士,爱好写一些技术博客,志在用通俗易懂的写作风格,帮助大家学到知识,学好知识!
目录
后台回复:AB testing实战,获取完整代码
1、增长黑客
1)前言
说到 AB testing,就不得不说到增长黑客,这个词大约在 2015 年就引入到中国了,但是在 2018 年开始火热起来。那么互联网公司想要增加活跃用户、增加收入,现在的产品运营还是采用增长黑客这样一种运营方式,并不是产品经理一拍脑袋就可以想到,或者老板直接拍板决定就可以做到的。
大家现在的玩儿法都是“数据驱动”,使用数据驱动方式来帮助运营更好的产品。
那什么是“增长黑客”呢?通俗的说就是“树挪死,人挪活”,互联网公司想要成长,想要变成一个巨头,也需要挪一挪、变一变,不断变换自己的产品,升级自己的产品,否则将会在这样一个弱肉强食、竞争激烈的生态中,被干掉。
我们有时候会觉得互联网公司就是【融资、烧钱、拉新、融资、烧钱、拉新…上市(倒闭)】这样一个流程,运气好的话就上市了,运气不好的话就倒闭了。但其实很多互联网公司内部,即使是烧钱,烧钱的方式也是有很多讲究的,并不是老板、产品经理或某个总监拍头决策的。

2)运用分析指标框架,驱动互联网产品和运营
具体可以看看,增长黑客,怎么运用分析指标框架,驱动互联网产品和运营?
现在分享一个链接,供大家了解:
http://www.woshipm.com/data-analysis/439849.html
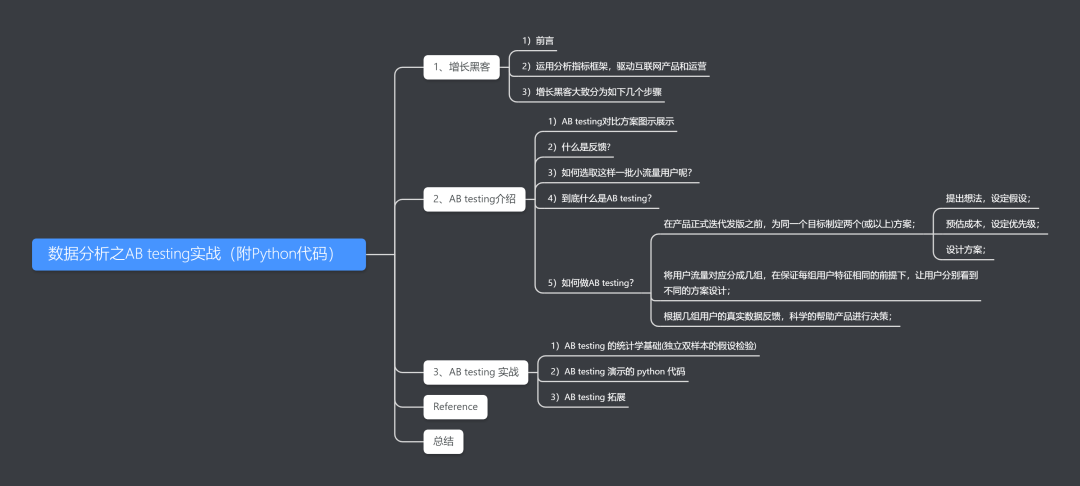
整个互联网内部,无论是产品、营销、销售等,现在基本都是采用“数据驱动”这样一个方式来进行运作的,这也就是“数据分析行业”在最近几年为什么这么火热的原因。“增长黑客”很多人用 AARRR 去总结了一下,如上图所示,下面我们来对上图做一个文字说明。
首选是“获取用户”(Acquisition),怎么样使用一种比较高效的方式(APP、网站、百度或淘宝买一些广告、)来获取到用户,增加用户数。接着是“增加活跃”(Activation),对于获取到的用户,怎么去激活他们,使得他们变得活跃。
然后是“提高留存”(Retention),我好不容易通过各种渠道,将用户拉到我的产品中,怎么让他们成为我们这个产品的忠实用户。再接着就是“实现收益”(Revenue),公司运营需要生存,就必须要赚钱获取收益,那么怎么样获取更多的收益?是订阅更多的VIP用户,还是卖给用户更多的产品或者广告来获取收益?
最后一个是“裂变传播”(Referral),如果我们前面的过程做的好的话,用户是不是会帮助我们做裂变传播,他们自己会口口相传(微信、朋友圈等),帮助我们做宣传,帮助我们拓展更多的用户。
这样上述几个部分就形成了一个良好的闭环,不断地去良性的发展。
3)增长黑客大致分为如下几个步骤
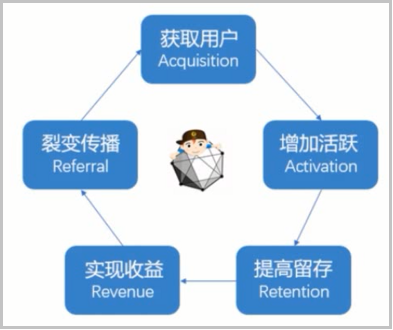
首先是“分析现状”,分析现在的产品有哪些问题?在哪方面可以提高?
然后是“设置目标”,你想干什么?像爱奇艺、腾讯视频等,就是想增加VIP的数量;像淘宝的话,如何更多地增加广告收入;像抖音的话,如何增加日活,怎么样让用户每天不停地去刷抖音,这样我会有更多的广告,更多的活跃用户数,更多的收入。
接着是“提出改进方案”,提出方案后,是不是你的方案就是最优的呢?其实并不是,这就是下面所说的需要进行“小规模测试”。
再接着是“开始小规模测试”,拿出一部分测试用户,让他们去看是否满意,是不是反馈的比较好。怎么知道反馈的好不好呢?就是下面要说的采集分析。
再接着是“采集分析”,对测试用户得到的数据进行数据分析,如果反馈效果好,就调整流量,不断扩大规模去测试。如果反馈效果不好,就停止或者是修改方案(回到前面的步骤),这是一个反复迭代的过程,这个过程也就是“AB testing”。
“AB testing”就是来帮助我们,通过数据分析的方式,来优化增长黑客这样一个流程,使用数据驱动的方式,来帮助分析我们的产品,分析我们的用户反馈。
2、AB testing介绍
1)AB testing对比方案图示展示
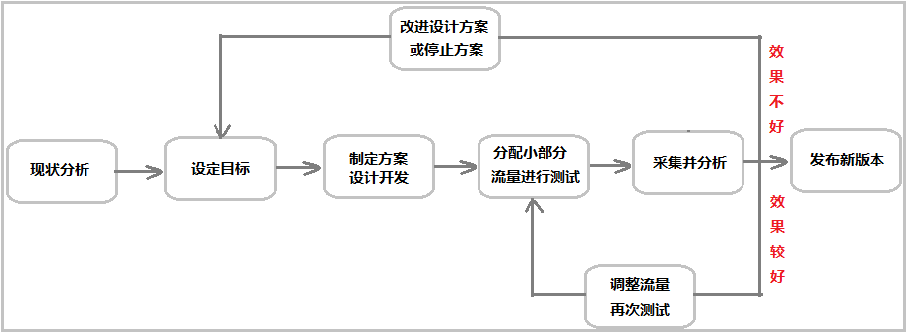
图示一:天猫两个网页的改版
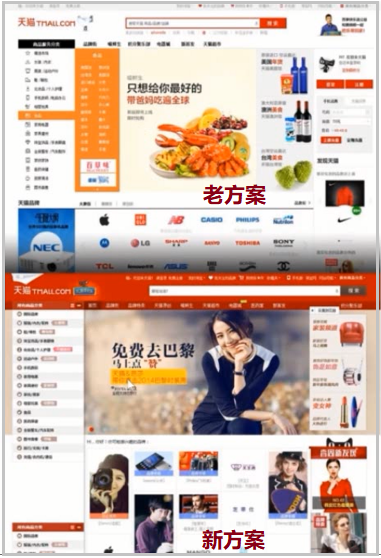
图示二:微信两个版本的改版
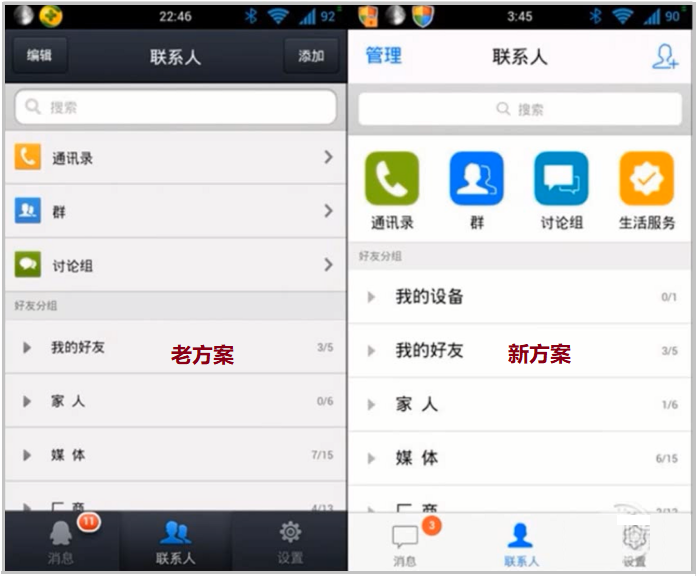
产品经理改了一个新的版本,那它到底好不好呢?可不可以一拍脑袋说,觉得哪个好就用哪个呢?万一反馈不是很好,万一下降了活跃用户数量,减少了用户收入,其实对于大公司来说,都是巨大的损失,谁都承担不起。所以需要使用像 AB testing 这样数据分析的方式,去把这个风险降到最低。
还有一个例子就是 Facebook,他们有一个级别非常高的高管,推动他们的产品,觉得某个产品这么好、那么好,所有 Facebook 产品的发布和版本的迭代都需要使用 AB testing,小范围用户测试的时候,如果发现用户反馈不好,变得不怎么活跃了,觉得非常难用了,即使这个高管再推动呢,也是不行的,必须使用数据说话,这个产品不好,就放弃这个版本,去研发下一个版本或者寻找另外的突破口。
这个东西在国内的好多公司基本都是这么玩儿的,比如说上述微信 1.0 版本和微信 2.0 版本,也不是说随随便便拍拍脑袋就发给大家使用的,其实也是运用 AB testing,很多时候让大家看到不同的页面,找到一部分小流量用户,帮助我们去测试,看看他们的反馈。
2)什么是反馈呢?
上面很多次我们都提到了“用户反馈”,那么什么是“反馈”呢?
其实就是这部分用户的使用时长呀,产生的收益呀,像百度这样的广告(他有没有点广告呀),像爱奇艺这样的付费网站(他有没有从一个普通用户变为一个 VIP 用户呀),这些指标等都可以验证你新的版本是不是好。
3)如何选取这样一批小流量用户呢?
最重的就是随机性。我们不能仅仅选择深圳市的某个地方的一些用户,作为测试用户。我们也不能仅仅选择年龄在 25-30 这样的限定范围的一些用户,作为测试用户。应该是在你的用户中随机抽取比如说 1% 的用户,作为小流量用户去进行版本测试,看看他们的反馈。
如果反馈好,我们考虑扩大流量用户,抽取 2%、5%、10%、20%、50% 甚至是 100%。
如果反馈不好,我们选择是终止此次实验,寻找新的突破口,还是选择改进自己的版本。
4)到底什么是AB testing?
简单地说:确定两个元素或版本( A 和 B )哪个版本更好!

5)如何做AB testing?
在产品正式迭代发版之前,为同一个目标制定两个(或以上)方案;
提出想法,设定假设;
预估成本,设定优先级;
设计方案;
日常中我们总在说 AB testing,做的是两个版本的对比,其实也可以是 ABCD testing,四个版本的对比,只不过实际中我们做得更多的就是 AB testing。再有一个,就是预估成本,这个是很有必要的,如果你切了 50% 的流量(或者更大的流量),将你的新版本上线跑了一周,假如情况非常糟糕,对于大公司来说,可能损失几个亿,或者是几十个亿,因此再进行实验之前,一定要好好预算一下,你究竟可以承担多大的风险,最后在设定你的方案。

将用户流量对应分成几组,在保证每组用户特征相同的前提下,让用户分别看到不同的方案设计;
注意几个术语,这个在后面的实战代码中有用。在做 AB testing 的时候,一般分为 control 组和 treatment 组,其中 control 组看到的是老页面(old page),treatment 组看到的是新页面(new page)。
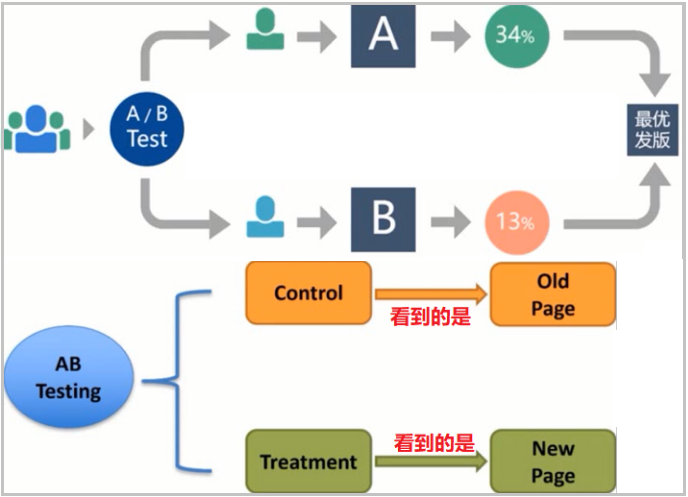
根据几组用户的真实数据反馈,科学的帮助产品进行决策;
通过分析用户使用的日志数据,来决定是扩大实验,还是继续修改方案,重新迭代。如果判定实验成功,则扩大实验范围。如果判定实验失败,终止本次实验,继续修改方案。
3、AB testing 实战
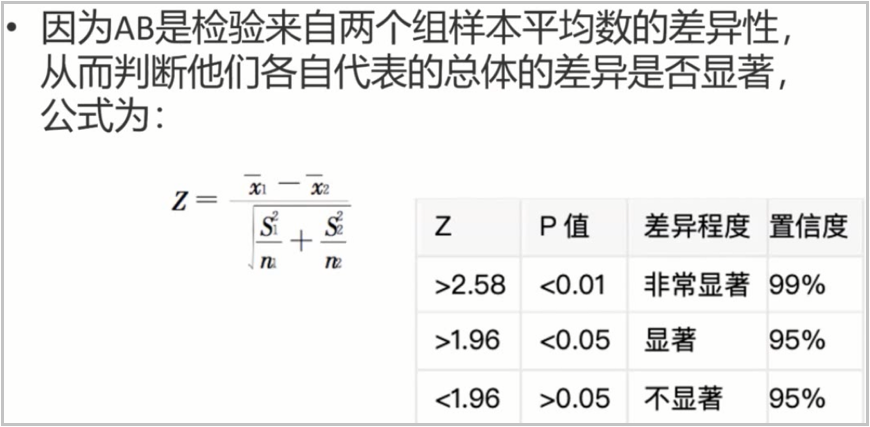
1)AB testing 的统计学基础(独立双样本的假设检验)
关于假设检验这个知识点,我在前面的文章中已经详细介绍过,这里就不一一说明,截取了几张图片供大家参考。
大家如果感兴趣,可以看一下这篇文章:https://blog.csdn.net/weixin_41261833/article/details/104623377


2)AB testing 演示的 python 代码
在进行代码演示之前,我们先对每个字段做一个说明:user_id 是用户的 id;timestamp 是用户访问页面的时间;group 表示把新的落地页分到 treatment 组、把旧的落地页分到了 control 组;landing_page 表示的是落地页;converted 表示的是否转化,1 表示转化(通俗的说:拿爱奇艺会员来说,普通用户是否转换为了 VIP 用户,1 表示转换了,0 表示未转换);
import pandas as pd
---------------------------------------------------------
# 读取数据,查看前5行
df = pd.read_csv("ab_test.csv")
df.head()
---------------------------------------------------------
# 数据预览,查看数据有多少行、多少列
df.shape
---------------------------------------------------------
# 查看数据中是否有空值
df.isnull().any()
df.info()
---------------------------------------------------------
# 查看数据中的错误行
print((True) != (True))
print((True) != (False))
print((False) != (True))
print((False) != (False))
"""
true != true fasle treatment new_page
true != false true treatment old_page
false != true true control new_page
false != false false control old_page
"""
# 下面这句代码,展示的就是group=treatment且landing_page=old_page和group=control且landing_page=new_page,这样的错误行;
num_error = df[((df.group == "treatment")!=(df.landing_page == "new_page"))].shape[0]
num_error
---------------------------------------------------------
# 去掉错误行后,再次查看是否还存在错误行
print("没有删除错误行之前的记录数:", df.shape[0])
df2 = df[~((df.landing_page == "new_page")&(df.group == "control"))]
df3 = df2[~((df2.landing_page == "old_page")&(df2.group == "treatment"))]
print("删除错误行之后的记录数:", df3.shape[0])
print("错误行共有",str(df.shape[0]-df3.shape[0]),"条记录")
num_error2 = df3[((df3.group == "treatment")!=(df3.landing_page == "new_page"))].shape[0]
num_error2
---------------------------------------------------------
# 查看是否有重复行
print("数据的记录数为:", df3.user_id.shape[0])
print("将user_id去重计数后的记录数为:", df3.user_id.nunique())
"""
通过上述分析,可以看出:user_id中有一条记录数是重复的。接下来,我们可以找出这条重复的记录,并去重。
"""
---------------------------------------------------------
# 查看重复的行
df3[df3.user_id.duplicated(keep=False)]
# 去除重复的行
df4 = df3.drop_duplicates(subset=["user_id"],keep="first")
df4.shape[0]
---------------------------------------------------------
# 我们来看一下control组的转化率
control_converted = df4.query('group=="control"').converted.mean()
control_converted
# 再来看一下treatment组的转化率
treatment_converted = df4.query('group=="treatment"').converted.mean()
treatment_converted
"""
自己下去思考一下:根据上述结果,老页面的转化率比新页面的转换率好,是不是就可以说明老页面好呢?
"""
---------------------------------------------------------
# 进行独立两样本的假设检验
import statsmodels.stats.proportion as ssp
converted_old = df4[df4.landing_page == "old_page"].converted.sum()
converted_new = df4[df4.landing_page == "new_page"].converted.sum()
n_old = len(df4[df4.landing_page == "old_page"])
n_new = len(df4[df4.landing_page == "new_page"])
data = pd.DataFrame({"converted":[converted_old, converted_new],
"total":[n_old ,n_new]})
display(data)
z_score, p_value = ssp.proportions_ztest(count=data.converted, nobs=data.total, alternative="smaller")
print("Z值为:", z_score)
print("P值为:", p_value)
---------------------------------------------------------
结果如下:
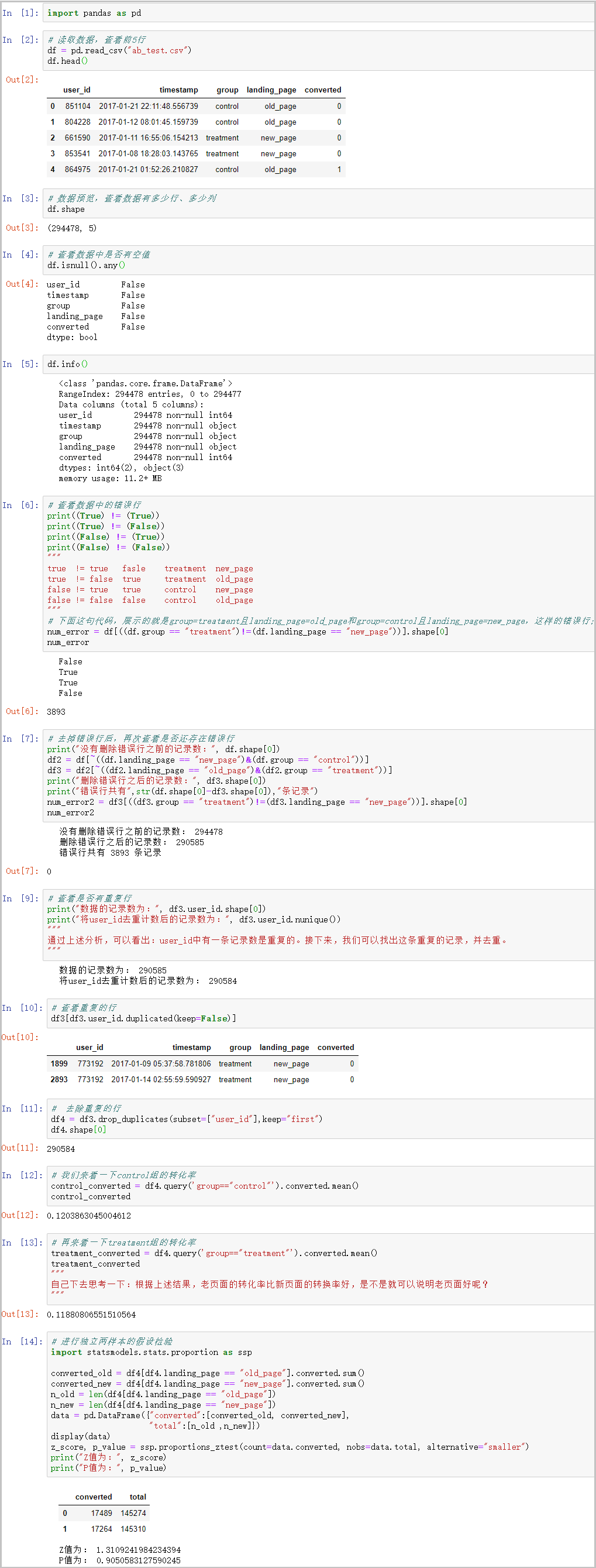
结果分析:
通过上述的结果发现,P 值为 0.9,远大于 0.05,也就是说,我们没有理由拒绝原假设,即只能接受原假设,也就是新老版本之间没有太大的差别。我们接下来要做的就是终止这次试验,继续优化自身的方案。
3)AB testing 拓展
关于 AB testing 的相关知识,我们就简单说到这里。
下面再次提供几个链接供大家参考学习:
Reference
http://www.woshipm.com/data-analysis/439849.html
https://blog.csdn.net/weixin_41261833/article/details/104623377
http://m.blog.itpub.net/31555699/viewspace-2653832/
https://www.jianshu.com/p/61e6c34d0704
本公众号全部博文已整理成一个目录,请在公众号后台回复「
m」获取!
作者往期精彩文章:
1、精心整理的 52 页 Python 操作 excel、word、pdf 文件【附获取方式】
2、520情人节,不懂送女朋友什么牌子的口红?没关系!Python 数据分析告诉你。
3、“罗永浩抖音首秀”销售数据的可视化大屏是怎么做出来的呢?
4、利用 Python 进行多 Sheet 表合并、多工作簿合并、一表按列拆分
5、Python 自动化办公之"你还在手动操作“文件”或“文件夹”吗?"
关注微信公众号『杰哥的IT之旅』,后台回复“1024”查看更多内容,回复“微信”添加我微信。
好文和朋友一起看~
评论