
深度解读:让你掌握OneFlow框架的系统设计(下篇)
本文主要介绍OneFlow系统的运行时(Runtime)的运行流程,以及参与运行时的各个模块是如何协同工作的,还探讨了OneFlow的Actor机制如何解决流水线和流控问题(Control Flow)。
如果你对OneFlow这套致简致快的框架设计感兴趣,或者对深度学习框架、分布式系统感兴趣的话,本文就会让你全面掌握OneFlow的系统设计。相信读完这篇文章,你就会理解我们是如何看待分布式深度学习训练的,我们为什么要这样设计,这样设计的好处是什么,以及我们为什么相信OneFlow这套设计是分布式深度学习训练框架的最优设计。


深度学习框架原理
OneFlow系统架构设计(简略版)
OneFlow完整运行流程与各模块的交互方式
3.1 分布式集群环境初始化
3.2 Python端搭建计算图
3.3 编译期:OneFlow(JobSet) -> MergedPlan
3.4 编译期:Compiler(Job)->Plan
3.5 运行时:Runtime(Plan)
本篇内容为下篇,上篇请见本次推送第一条,中篇请见本次推送第二条。
3.5. 运行时:Runtime(Plan)
OneFlow的运行时(Runtime)极其简单,总共分3步:
创建所有的Global对象
根据Plan创建本机上的所有Actor
给源节点的Actor发送ActorCmd::kStart启动信号。随后整个计算图中的Actor依次启动,runtime启动完毕。
由于OneFlow的运行时仅是一张全部由Actor组成的计算图(对于分布式训练,是一张跨机器的Actor计算图),当每个机器都把本机上的Actor建立起来以后,仅需要给那些源节点Actor发动启动信号,启动信号就会在整个计算图中传导开来,每个Actor就开始根据自身的状态机工作了。当整个训练(Runtime)要结束时,也是这些源节点发送关闭信号(kEordMsg),关闭信号也会随着Actor之间的通信逐渐传导到整个计算图,所有的Actor就会根据eord信号依次关闭。当所有的Actor都关闭后,Runtime就可以下线了。
对运行时的Actor机制介绍可以参考知乎文章:《都2020年了,为什么我们相信OneFlow会成功》 中的章节三:OneFlow的特色一:Actor机制——用一套简洁的机制解决所有分布式深度学习框架中的技术难题。
3.5.1 创建所有的Global对象
此处会依次创建运行时所需的所有全局对象。
CommNet:CommNet是OneFlow分布式训练中负责多机数据传输和消息通信的模块。底层有基于Epoll的实现和基于RDMA的实现。
boxing::collective::CollectiveBoxingExecutor & boxing::collective::CollectiveBoxingDeviceCtxPoller:负责执行集合通信操作(NCCL)
MemoryAllocator:负责内存(Host内存 和 GPU显存)的申请与释放
RegstMgr:负责创建所有的Regst (Mgr是Manager的缩写)
ActorMsgBus:负责运行时Actor之间的消息通信 (Msg是Message的缩写)
ThreadMgr:负责创建和管理所有的Thread
3.5.2 ThreadMgr与Thread
在创建Global对象ThreadMgr时,ThreadMgr会根据Plan中本机上的所有TaskProto中的ThreadID创建对应的Thread。
Thread
Thread负责创建、运行、销毁Actor。一个Thread会管理多个Actor,Actor收到的消息(ActorMsg)都需要通过Thread中的消息队列获取。
Thread的消息队列分为两级:
msg_channel_(继承自Channel对象)接收跨线程的ActorMsg
local_msg_queue_ (就是一个队列std::queue)接收本线程内的消息通信
通过local_msg_queue_可以加速消息传递的过程。
每个Thread内部都有一个轮询线程actor_thread_负责轮询消息队列PollMsgChannel,将轮询到的消息解析,调用该消息的接收者Actor,并让该Actor处理该消息ProcessMsg。
GpuThread
Thread分为CPU和GPU Thread。CpuThread除了启动轮询线程以外没有其他多余的工作了。GpuThread有两个额外的部分:1)创建ThreadCtx,里面包含了GPU的CUDA stream handle和CUDA callback event channel;2)启动一个额外的轮询线程callback event poller,负责从ThreadCtx中的callback event channel中轮询获取callback,并执行该callback(原因是GPU上的任务是异步执行)。对GPU的架构和使用,我们放在下面的Device章节介绍。
3.5.3 ActorMsgBus与ActorMsg
ActorMsgBus
每台机器都会有一个Global对象ActorMsgBus负责消息通信。只有一个主要的接口:SendMsg
ActorMsgBus相当于一个消息的路由,会判断该消息的目的地是否是本机,如果是本机,则通过ThreadMgr找到对应的Thread,然后EnqueueActorMsg。如果消息的目的地是其他机器,则通过Global对象CommNet将该消息发送给其他机器。其他机器的Global
运行时Actor消息通信机制
示意图见下图:
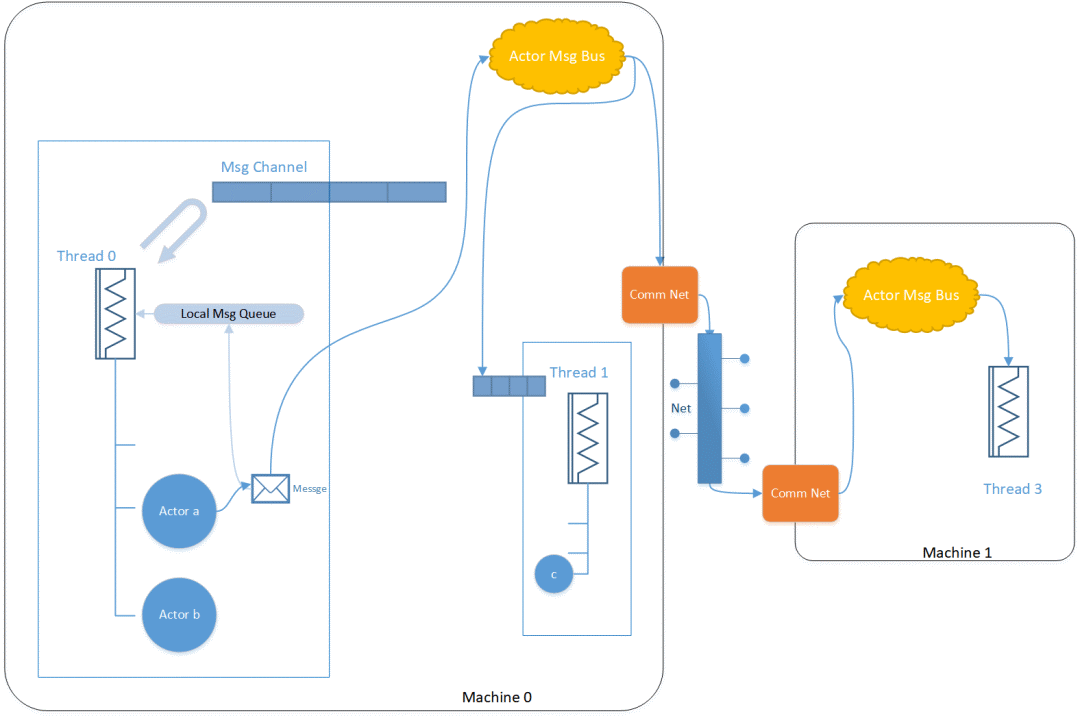
当一个Actor需要给另一个Actor发消息时,会判断接收者Actor:
是否是本线程内:
如果是,则ActorMsgBus会找到本机内的对应线程Thread,传入到该Thread的Msg channel中
否则:调用本机器的CommNet对象传输该消息。接收者所在机器的CommNet对象收到消息后会转给该机器的ActorMsgBus处理。该机器的ActorMsgBus会找到对应的线程Thread将该消息传入线程的MsgChannel中
如果是,则直接压入Thread的LocalMsgQueue中 (最快)
否则:调用本机器的ActorMsgBus传输数据。Actor Msg Bus会判断接收者是否在本机内
Thread会不断轮询自己的LocalMsgQueue,取出对应的消息找到对应的Actor去处理该消息。如果LocalMsgQueue为空,则尝试去从MsgChannel中取消息放到LocalMsgQueue中。
ActorMsg
运行时Actor的消息称之为ActorMsg。ActorMsg有几种类型(ActorMsgType):
kRegstMsg:表示这个ActorMsg包含了一个Regst。这是运行时Actor之间通信最主要的消息,生产者生产一个Regst通知下游消费者的消息、消费者使用完Regst返还给生产者说我用完了,都是RegstMsg。可以从ActorMsg的
regst()接口中拿到该Regst。需要注意的是,无论是生产者通知消费者的消息,还是消费者用完的Ack消息,都是同一种消息。OneFlow的Actor通信中是不需要指明“Ack”的。各个Actor在处理ActorMsg的时候都可以从Regst中得知是不是Ack。
kCmdMsg:一些控制指令信号。不包含数据。如kConstructActor(Thread直接处理的消息,用于Thread创建Actor);kStart,Actor启动并开始工作。运行时靠着Start消息的传染,整个计算图开始工作。
kEordMsg:表示训练结束,Actor可以切换到Zombie状态。运行时靠着Eord消息的传染,整个计算图中的Actor均切换到Zombie状态,等待销毁和RunTime下线。运行时的结束不是一下子就结束的,有可能计算图的源节点已经发出了Eord的信号,并将自己切换成Zombie状态,而计算图中的后半部分还在工作中。
通过数据流以去中心化的方式控制整个计算图的工作,是OneFlow区别于其他框架的一大特色。
3.5.4 Register
oneflow/core/register/路径
在初始化全局对象时,会创建Global对象RegstMgr。每台机器上的RegstMgr管理了所有的Regst。
RegstMgr
RegstMgr在初始化时就会根据Plan申请所有的本机上的内存:HostMemory、HostPinnedMemory(For CUDA CopyH2D)、DeviceMemory、LockedMemory(For RDMA)等。并根据Plan中的Regst配置信息分配相应的内存地址给Regst。Regst的内存地址是固定的,直到运行时结束Regst的内存地址和大小都不会变化。OneFlow的静态内存管理是Runtime启动时统一分配,Runtime结束时统一销毁。运行时的内存调度开销是0。
Regst
Regst是OneFlow运行时的基本内存单元,也是基本的消息单元,Actor之间的通信、所有的数据生产、消费、回收都是Regst。由于OneFlow是静态内存分配,内存的分时复用调度是编译期的内存复用算法已经做好了(通过控制边+offset方式),所以运行时仅需要按照编译期生成的MemChunk、MemBlock、Regst的配置描述(RegstDescProto)信息一次性申请内存,并分配给对应的Regst即可。
Regst存储了两类信息:
生产者Actor id和消费者 Actor ids。一个Regst的生产者是唯一的,消费者可能有多个。
Blob的信息
由于历史原因(在介绍ExecGraph和ExecNode时也提到了),Actor内部可能会有一个执行子图(多个op/kernel),Actor的产出消费Regst均可能包含多个Blob(Tensor)。Regst需要管理blob name in op -> logical blob id -> blob的映射(blob name in op -> logical blob id 是op自己管理的),使得Kernel在执行时可以直接根据blob name拿到对应的blob指针。
未来会精简Regst的设计,一个Regst只包含一个blob;合并Tensor和Blob概念。
Regst相关概念
RegstDesc 编译期的Regst描述类(C++),提供元信息,关联Task,包含mem block,包含regst_num。RegstDesc 与Regst是一对多的关系(相邻Actor流水并行执行的关键)。TaskNode的Build过程中的Produce/ConsumeRegst就是在创建和消费RegstDesc
RegstDescProto 配置文件的proto描述,存储在Plan中
RtRegstDesc 运行时的Regst描述类(C++),关联Actor,提供计算Size的接口
Regst 运行时的Regst,存储真正的blob内存,被Actor所管理。
关系:RegstDesc(Compiler)-> RegstDescProto(Plan)-> RtRegstDesc(Runtime)-> Regst(Runtime, 1 to n)
Blob相关概念
BlobDesc 编译期的Blob描述类(C++),提供元信息:Shape、DataType;Op的InferBlobDesc就是在推导BlobDesc。
BlobDescProto Blob配置文件的Proto描述,存储在Plan中(RegstDescProto中)
RtBlobDesc 运行时的Blob描述类,跟BlobDesc的区别是提供Header和Body的Size/CudaAlignedSize
Blob 运行时Kernel操作的基本数据对象。存储在Regst中。
需要注意的是,由于RegstNum > 1时,同一个RegstDesc会有多个Regst,多个Regst会存储多个相同BlobDesc的Blob,所以Kernel每次运行拿到的Blob指针、Blob中的数据地址也可能是不同的。
Tensor相关概念
user_op::TensorDesc BlobDesc在UserOp框架下的代称
user_op::Tensor Blob在UserOp框架下的代称
3.5.5 Actor
Actor是OneFlow运行时的基本单元。编译期的主要工作就是把用户定义的逻辑计算图和分布式集群环境编译成Plan。Plan由Actor的描述信息TaskProto组成。所以运行时就是根据Plan中的所有TaskProto创建所有的Actor。
3.5.5.1 创建流程
1) Runtime对象通过ThreadMgr->Thread->AddTask的方式新增一个Actor (HandoutTasks)
2) Runtime对象通过ActorMsgBus给每个Actor发送 ConstructActor的指令消息(ActorCmd::kConstructActor)
3)每个Actor所在的Thread收到构造Actor的消息后调用ConstructActor接口构造Actor,其中是使用了NewActor ,传入ThreadCtx,调用Actor的Init方法初始化该Actor。
Actor::Init(JobDesc, TaskProto, ThreadCtx)
我们看看Actor的初始化过程中做了哪些事情:
1) 根据ThreadCtx创建DeviceCtx 。运行时的Context有三级:ThreadCtx->DeviceCtx->KernelCtx 。对于Context的解释我们放在Device部分详细介绍。
2) 构造Kernel(ConstructKernel)
3) 创建Regst(NewRegsts)
在调用RegstMgr->NewRegsts之前,RegstMgr已经给所有的Regst都申请好了内存,NewRegsts更应该像是GetRegsts。对于同一个RegstDesc,根据其regst_num会有多个Regst实例
4) 处理消费的RegstDescId以及Regst之间的Inplace
5) 虚接口VirtualActorInit,供各个子类Actor自己重载自定义的初始化内容
3.5.5.2 Actor状态机
当Actor初始化完毕以后,Actor就进入了等待状态。在Actor收到Eord信号并销毁之前,Actor一直都在等待状态和执行状态之间切换。Actor的状态机我在之前的知乎文章中简要介绍过:
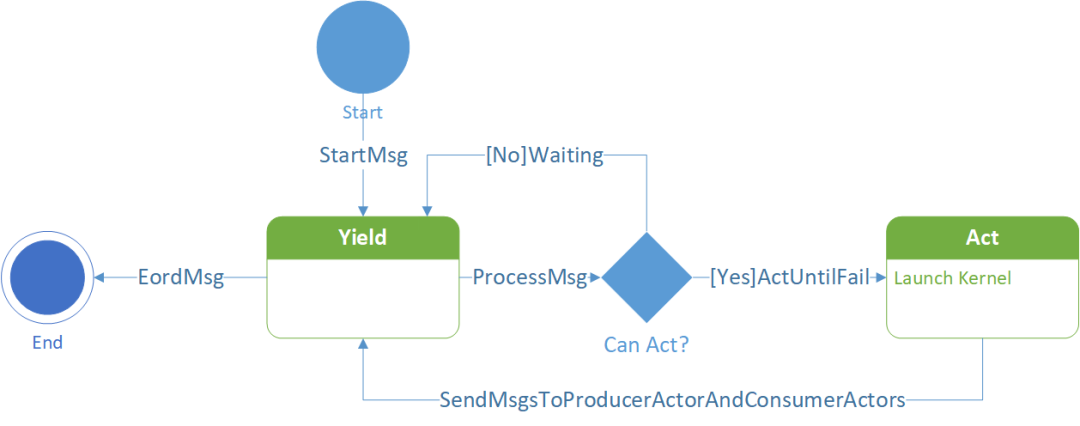
Actor所有的逻辑都通过ProcessMsg来实现。Thread将收到的消息交给Actor处理,Actor处理消息过程中可能会触发执行(Act),执行会Launch其内部的Kernel。执行结束会向上下游Actor发消息。运行时的去中心化调度就是靠着Actor之间的消息通信所实现的。
Actor内部有多种MsgHandler来处理消息(HandlerNormal和HandlerZombie)。在Actor正常运行过程中都使用HandlerNormal来处理消息。HandlerZombie用于Actor在有序退出时的消息管理。
HandlerNormal
Actor正常运行过程中主要处理的消息是RegstMsg,其中包含了上游发来的可供该Actor消费的Regst 或者 下游使用完该Actor产出的某个Regst。在HandlerNormal中,Actor会解析RegstMsg并更新自己的状态,然后触发ActUntilFail。
ActUntilFail
在ActUntilFail中,Actor会判断执行条件是否满足,如果满足就一直执行,直到失败。执行条件是否满足需要两个条件:IsReadReady和IsWriteReady,通常Actor需要判断其消费的Regst都到齐了,且有空闲块可写时,才会触发执行。每次执行都会触发消息的发送:包括给上游和下游Actor发消息。
Act
每次Actor执行称之为一次Act。Act 是一个虚方法,需要子类具体实现。我们可以参考一个最常见的Actor:NormalForwardActor,我们所有的用户级别的Op都使用NormalForward类型的Actor。这种Actor的Act方法里调用了AsyncLaunchKernel,去Launch内部的Kernel执行。
3.5.5.3 异步执行 与 异步消息发送
AsyncLaunchKernel
Actor内部的Kernel是异步调用的。每次Launch Kernel,Actor都要给该Kernel关联此次执行对应的Regst(流水并行对Kernel无感)。
Actor的所有消息发送都是异步的。见ActUntilFail。等Kernel异步执行结束以后,相关的消息才会被发送出去。
Actor中需要对Inplace的Regst/Msg做特殊处理,因为Inplace会改变Regst的生命周期(延长ConsumedRegst的生命周期直到ProducedRegst生命周期结束)
Actor控制逻辑掩盖
异步消息保存在Actor的async_msg_queue中。如果消息的接收者和本Actor在同一个WorkStream(Thread)中时,异步消息可以提前发送,不需要等待Kernel异步执行完就可以通知其他Actor,由于在同一个Stream中,任务的执行是有序的,该Actor的后继Actor可以提前将任务也提交到相同的Stream中,等上一个任务执行完,下一个任务一定可以满足执行条件并执行。OneFlow的Actor机制通过相同Stream提前发消息就可以掩盖GPU上绝大多数Actor的控制逻辑开销。
3.5.5.4 Actor扩展性
Actor子类可以定制消息的处理方式,可以定制执行条件。在NormalForward这类常见Actor中,Actor需要所有的输入和输出都满足才会Act一次,且Act结束会将输入还给上游、输出发给下游。
同时OneFlow也扩展了多种特殊的Actor,如
Repeat,收到一个输入以后,就可以连续重复Act多次(只要有可写的),重复Act结束以后才会返还输入Regst。
Unpack,收到一个输入以后,会将该输入解码,拆成多个Regst分批次发给下游,发完以后才会返还输入Regst。
Input-wise,该Actor有多路输入,每到达一个输入,就可以Act,无需等待所有的输入都到齐才去Act
等等。
需要指出的是:Repeat和Unpack分别对应时间上的Broadcast和Split。OneFlow的BatchAccumulate就是通过插入Repeat和Unpack op来实现的(反向梯度会插入Acc)。一个模型的Repeat num = 4 、数据 Unpack num = 4的单卡训练 跟 4卡数据并行 从数学上是完全等价的。
Actor通过子类的多种自定义行为使得整个系统很容易扩展,一些特殊的需求仅需要在OneFlow中新增一个类型的Actor就能完成。
3.5.5.5 流控机制
Actor天然支持流水线,运行时每个Actor自己通过判断跟自己相关的消息就能得知自己能否执行,不依赖中心调度结点,使用最简单的FIFO原则就解决了流控问题(Control Flow)。我们用一个数据预处理的流水线时间线的例子介绍一下Actor的流水线和流控机制:
一个非常常见的数据预处理流程如下:

为了方便推演,我们假设DataLoding、Preprocessing、Copy、Training都是一个Actor(实际上Preprocessing和Training分别都是由多个Actor所组成的子图)。当这4个Actor之间的RegstNum均为2时,如果训练时间比较长(训练是整个网络的瓶颈),我们看到一种流水线的时间线如下图:

当训练到第3个batch时,4个Actor的执行时间成一种反序递进的方式规律执行。图中灰色表示奇数Batch的数据,蓝色表示偶数Batch的数据,为了方便理解,其中标出了Batch 6 的数据随着时间线的演进在整个pipeline中的流向。图中相邻两条时间线中间的两个小方块表示RegstNum=2的Regst,白色表示空闲状态,蓝色表示被偶数Batch的数据占用,灰色表示被奇数Batch的数据占用。随着时间线的演进,我们罗列出了Regst状态变化时刻的新状态。当训练是瓶颈时,数据加载、预处理、拷贝传输的开销都被完美掩盖在训练时间中了。
那么当数据加载是瓶颈的时候呢?下面这个时间线更容易理解OneFlow流控是如何实现的:
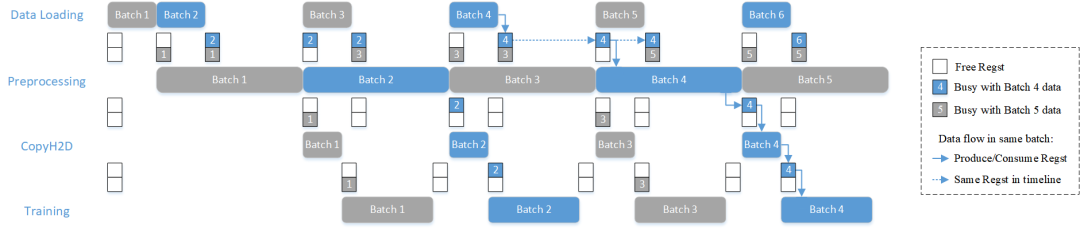
由于Preprocessing是耗时最长的,所以预处理上游的Actor(DataLoading)的工作节奏(背压机制, Back Pressure)以及预处理下游的Actor(Copy、Training)的工作节奏均被预处理这个Actor的执行所控制。
OneFlow使用背压机制解决流控问题。如上面两张图所示,虽然DataLoading的时间很短,但并不会无节制的加载数据,而是当Regst被填满之后就会等待,当Training是瓶颈时,Batch 3的数据在训练时,DataLoading提前准备了Batch 7和Batch 8的数据,然后就等着;当Preprocessing是瓶颈时,DataLoading永远都比Preprocessing提前处理了两个Batch的数据。
3.5.6 Opertor 与 Kernel
Operator是OneFlow计算图(ComputeGraph)的基本单元,是计算图中的节点,Tensor是计算图上的边。Operator是编译期概念,对应的运行时概念就是Kernel。
oneflow/core/operator路径下包含了Operator的基类以及一些系统Op;
oneflow/core/kernel路径下包含了Kernel的基类以及一些系统Kernel;
UserOp(UserKernel)的描述在oneflow/core/framework下定义,而具体的每个UserOp/UserKernel都放在了oneflow/user路径下。
Operator
bn_in_op表示blob name in op。一般的Op都会定义"in"作为输入的Tensor名字,“out”是输出的Tensor名字。
lbi/lbn:分别是LogicalBlobId和LogicalBlobName的缩写,LogicalBlobName是一个Op的输入输出Tensor在逻辑图上的唯一字符串,通常以"op_name/bn_in_op"的方式描述。如Conv1 Op的输出Tensor的LogicalBlobName就是"Conv1/out",LogicalBlobId是LogicalBlobName的结构化表达。
一个具体Op的主要行为是规定输入输出、提供Tensor的推导方法、提供合法的SBP Signature等。
Kernel
Actor中通常都会有一个Kernel,每次执行就是异步Launch一次Kernel。Kernel的Forward函数(对应UserKernel的Compute函数)就是在做实际的数学计算,读输入的Tensor数据,将计算完的数据写到输出Tensor的内存/显存上。对于GPU的Kernel,Kernel的计算实际上是向CUDA Stream提交异步任务(对应Kernel中的cuda kernel的定义和调用)。
向GPU提交异步的计算任务使用到了KernelCtx,KernelCtx由DeviceCtx构造而来,而DeviceCtx又由ThreadCtx构造而来。其中最重要的结构就是CudaStreamHandle。
3.5.7 Device
oneflow/core/device路径
Kernel向Device(GPU)提交计算任务,使用到了cudaStream_t,这个cuda stream是哪里来的呢?
当一个Thread是GPUThread时,创建GPUThread会创建相应的ThreadCtx,其中包含了一个cudaStream以及cuda callback event的Channel。GPUThread除了自己轮询ActorMsgQueue的线程以外,还会有一个callback的轮询线程:cuda callback event poller 。Actor(Kernel)异步执行计算任务结束后,cuda callback event poller线程会拿到相应的callback event,并会执行该event。
Kernel执行结束的callback是什么时候被插入的呢?在Actor每次Act(AsyncLaunchKernel)结束后,都会将发消息的动作作为一个CallBack(Actor::AsyncSendQueuedMsg)通过DeviceCtx->AddCallBack接口压入cuda stream。
DeviceCtx(KernelCtx、ThreadCtx)的主要作用就是提供一个CudaStream供Kernel提交计算任务,同时提供一个callback的channel用于执行Actor发消息的逻辑。通过这种设计,OneFlow的运行时就实现了Actor的异步执行和异步消息机制。
Actor通过DeviceCtx异步LaunchKernel的示意图如下:

由于相同Stream下的多个Actor,可以不用等Kernel的异步计算任务执行完就发消息,所以可以将Actor通信开销、Kernel的CPU代码执行开销完全掩盖在CudaStream的计算开销中。其时间线如下图所示:

其中WithoutOverlap对比了如果没有Actor在同一个Stream中可以提前发消息的优化,CudaStream中的计算会因为消息通信、LauchKernel的开销导致GPU计算资源没有被充分利用。
3.5.8 内存管理
oneflow/core/memory路径
MemCase
Regst通过MemCase标记了自己所属的内存类型,如果是GPU上的显存,还需要标记自己所属的DeviceId。如果是CPU上的主存,会标记该Regst是否是被CopyHD或CommNet所使用的。Regst通过MemBlockId和MemBlockOffset标记了自己所属于哪个MemBlock以及对应的偏移量。
MemoryAllocator
根据MemCase和Size申请对应大小和类型的内存块,返回内存块首地址;根据内存地址回收内存。在Lazy情况下,仅在Runtime的启动/结束时(RegstMgr的构造函数和析构函数里)才会申请/释放内存。
MemBlock与Chunk
这是OneFlow的多级内存设计:Chunk -> MemBlock -> Regst。
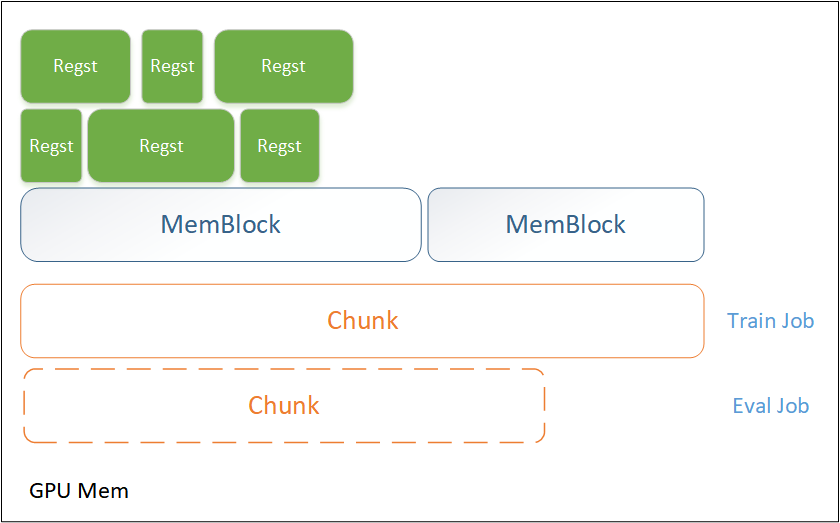
MemBlock:同一个Chain(MemChain,通常是GPU上的前后向的所有activation regsts在一个MemChain中,Optimizer子图部分的Regst在各自的MemChain中)内的Regst根据分时复用的原则共用一个MemBlock的不同段,通过size和offset标记。内存复用算法会尽可能让MemBlock的Size小,同时满足互斥的Regst(生命周期有重叠的)不会有内存区域的重叠。
Chunk:一个Job内在同一块GPU上的MemBlock的合集称为一个Chunk。Chunk的Size是所有内部MemBlock的Size之和。(即同一个Chunk内部的MemBlock之间没有复用内存)
多个Job在同一个块GPU上的Chunk,会根据Job之间的互斥关系,完整复用一个大的Chunk(取最大值)作为最终的Chunk。如TrainJob和EvalJob互斥,所以TrainJob的所有可复用的Regst的总Chunk跟Eval的总Chunk合并复用一块内存。通常情况下,Eval只有前向,比TrainJob计算图要小,可以完全被TrainJob的Chunk所包含。即新增一个EvalJob不会新增任何内存。
3.5.9 网络模块
oneflow/core/comm_network路径
Global对象CommNet提供运行时多机之间收发ActorMsg、传输Regst数据功能。分为Epoll(基于Socket)实现和Ibverbs(基于RDMA)实现。其中RDMA需要注册内存(锁页内存),会将对应的Regst内存注册。
3.5.10 IO模块
oneflow/core/persistence路径
提供一系列磁盘读写操作的接口,主要用于跟IO相关的Kernel实现。
FileSystem 提供文件系统相关操作,如创建文件、查询目录等。(文件、目录的增删改查操作)。目前支持POSIX文件系统和Hadoop文件系统。
Snapshot 分为SnapshotReader和SnapshotWriter,对应Checkpoint的Load和Save操作。
In/OutStream 提供文件读写流操作。如DataReader的Kernel读取OFRecord就使用了PersistentInStream。
oneflow/core/record 路径
除了OFRecord以外其余内容都是即将过时的老版本的decoder/encoder接口。新版本的易于扩展的data reader设计见 oneflow/user/data路径下的各个文件。主要分为了data reader、dataset、parser等抽象。新的DataReader设计后面会专门出一篇文章介绍。
3.5.11 ID manager
Global对象IDMgr(ID编址系统)严格意义上不能称之为一个模块,在OneFlow中是一个很小的单元。负责id的压缩和映射、负责编译期Task、运行时Actor的唯一标识符TaskId/ActorId的编码和解码。64位的task id包含了10位的machine id、11为的thread id、21位的local work stream id、21位的task id。
IDMgr还提供各种映射接口,主要是GPU相关的各个线程id映射(计算、copy、nccl等)。

总结
OneFlow的运行时是一套非常简洁、高效的Actor系统,通过简单的消息机制就解决了分布式训练中的复杂调度问题、流控问题,流水线的实现等。相比于其他框架的运行时,OneFlow的Actor实际上是对Kernel的一层很简单很浅层的封装,但是这一套抽象解决了运行时众多Kernel对各种资源的管理、分布式并行引入的Kernel间复杂的时序依赖、状态依赖等问题。Actor系统还非常的模块化,同时易于扩展和组合,可以支持各种复杂的分布式深度学习训练需求。
点击“阅读原文”,前往OneFlow代码仓库。