
主动学习(Active Learning)概述及最新研究
Datawhale干货
作者:
你Sony@知乎
,编辑
:极市平台
导读
作者将自己对于主动学习的理解和最新研究的感悟都整理为这篇文章,供大家参考、讨论,一起学习和交流主动学习。
作者将自己对于主动学习的理解和最新研究的感悟都整理为这篇文章,供大家参考、讨论,一起学习和交流主动学习。同时,作者以后继续阅读主动学习领域的文章,有不错和值得推荐的文章,会实时更新到 github 【awesome-active-learning】— https://github.com/baifanxxx/awesome-active-learning 的 paper list 里,大家可以通过这个list最快地阅读最新最重要的文章,也欢迎大家推荐一些文章和一起交流。
Note: 前1、2、3节都是一些主动学习基础内容,也有很多文章做过类似的整理和介绍,如果你已经很了解了,可以直接跳到4节以后阅读。
1. 介绍
主动学习是一种通过主动选择最有价值的样本进行标注的机器学习或人工智能方法。其目的是使用尽可能少的、高质量的样本标注使模型达到尽可能好的性能。也就是说,主动学习方法能够提高样本及标注的增益,在有限标注预算的前提下,最大化模型的性能,是一种从样本的角度,提高数据效率的方案,因而被应用在标注成本高、标注难度大等任务中,例如医疗图像、无人驾驶、异常检测、基于互联网大数据的相关问题。
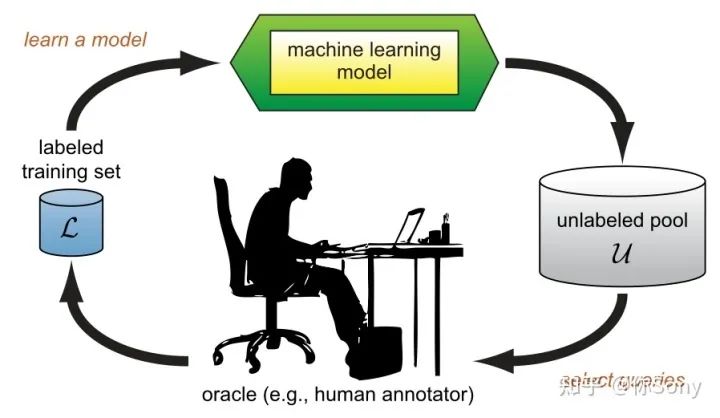
The pool-based active learning cycle. (Burr Settles, 2010)
Settles, Burr的【Active Learning Literature Survey】— https://minds.wisconsin.edu/bitstream/handle/1793/60660/TR1648.pdf%3Fsequence%3D1%26isAllowed%3Dy 文章为经典的主动学习工作进行了总结。上图是经典的基于池的主动学习框架。在每次的主动学习循环中,根据任务模型和无标签数据的信息,查询策略选择最有价值的样本交给专家进行标注并将其加入到有标签数据集中继续对任务模型进行训练。因为主动学习的过程中存在人的标注,所以主动学习又属于Human-in-the-Loop Machine Learning的一种。
主动学习为什么是有用的?下面通过一个直观的小例子让大家感受一下。

(a) 一个由400个实例组成的数据集,从两类高斯分布均匀采用。实例表示为二维特征空间中的点。(b) 从问题域中随机抽取30个标记实例,训练一个逻辑回归模型。这条蓝线代表了分类器的决策边界(70% 的准确率)。(c) 使用不确定性抽样对30个主动查询实例进行训练的逻辑回归模型(90%)。(Burr Settles, 2010)
由此说明,样本对模型的贡献并不是一样的,选择更有价值的样本具有实际意义。当然,如何确定和评估样本的价值也是主动学习研究的一个重点。
2. 模型分类
根据应用场景,主动学习的方法可以被分为membership query synthesis,stream-based and pool-based三种类型。其中,pool-based是最常见的场景,并且由于深度学习基于batch训练的机制,使得pool-based的方法更容易与其契合。在membership query synthesis的场景中,算法可能挑选整个无标签数据中的任何一个交给oracle标注,典型的假设是包括算法自己生成的数据。
但是有时候,算法生成的数据无法被oracle识别,例如生成的手写字图像太奇怪,oracle也不能识别它属于0~9?或者生成的音频数据不存在语义信息,让oracle也无法识别。在stream-based的场景中,每次只给算法输入一个无标签样本,由算法决定到底是交给oracle标注还是直接拒绝。有点类似流水线上的次品检测员,过来一个产品就需要立刻判断是否为次品,而不能在开始就根据这一批产品的综合情况来考量。在pool-based的场景中,每次给算法输入一个批量的无标签样本,然后算法根据策略挑选出一个或几个样本交给oracle进行标注。
这样的场景在生活中更容易出现,算法也可以根据这一批量样本进行互相比较和综合考虑。
3. 基本查询策略
在主动学习框架中,最重要的就是如何设计一个查询策略来判断样本的价值,即是否值得被oracle标注。而样本的价值并不是一成不变的,它不仅与样本自身有关,还和任务和模型等因素有关。一个简单的例子,在猫狗二分类问题中,一张长得像猫的狗的照片,对分类模型的训练往往是有价值,因为它难以分辨。但是,同样是这张照片,出现在动植物二分类问题中,就变得不那么重要了,因为模型想分辨它并不难。因此,查询策略的设计并不是简单和一成不变的,需要根据具体环境、问题和需要进行设定。这样就产生了各种各样的查询策略,下面,我介绍一些基本的查询策略供大家参考。
不确定性采样 (Uncertainty Sampling):也许是最简单直接也最常用的策略。算法只需要查询最不确定的样本给oracle标注,通常情况下,模型通过学习不确定性强的样本的标签能够迅速提升自己的性能。例如,学生在刷题的时候,只做自己爱出错的题肯定比随机选一些题来做提升得快。对于一些能预测概率的模型,例如神经网络,可以直接利用概率来表示不确定性。比如,直接用概率值,概率值排名第一和第二的差值,熵值等等。
多样性采样 (Diversity Sampling) :是从数据的分布考虑的常用策略。算法根据数据分布确保查询的样本能够覆盖整个数据分布以保证标注数据的多样性。例如,老师在出考试题的时候,会尽可能得出一些有代表性的题,同时尽可能保证每个章节都覆盖到,这样才能保证题目的多样性全面地考察学生的综合水平。同样地,在多样性采用的方法中,也主要分为以下几种方式:
基于模型的离群值——采用使模型低激活的离群样本,因为现有数据缺少这些信息;
代表性采样——选择一些最有代表性的样本,例如采用聚类等簇的方法获得代表性样本和根据不同域的差异找到代表性样本;
真实场景多样性——根据真实场景的多样性和样本分布,公平地采样。
预期模型改变(Expected Model Change) :EMC通常选择对当前模型改变最大、影响最大的样本给oracle标注,一般来说,需要根据样本的标签才能反向传播计算模型的改变量或梯度等。在实际应用中,为了弱化需要标签这个前提,一般根据模型的预测结果作为伪标签然后再计算预期模型改变。当然,这种做法存在一定的问题,伪标签和真实标签并不总是一致的,他与模型的预测性能有关。
委员会查询 (Query-By-Committee):QBC是利用多个模型组成的委员会对候选的数据进行投票,即分别作出决策,最终他们选择最有分歧的样本作为最有信息的数据给oracle标注。
此外,有些研究者将多种查询策略结合起来使用混合策略进行查询,例如即考虑不确定性又考虑多样性的。还有一些其他的查询策略,例如预期误差减少、方差减少、密度加权法等。
4. 经典方法
下面我给大家分享几个经典的主动学习方法,这些方法经常被拿来作对比。在自己以后的文章里也可以考虑和以下经典的方法进行比较。
Entropy
可直接根据预测的概率分布计算熵值,选择熵值最大的样本来标注。
BALD
【Deep Bayesian Active Learning with Image Data】— https://arxiv.org/abs/1703.02910
BGADL
【Bayesian Generative Active Deep Learning】— https://arxiv.org/abs/1904.11643
Core-set
【Active Learning for Convolutional Neural Networks: A Core-Set Approach】— https://openreview.net/forum%3Fid%3DH1aIuk-RW
LLAL
【Learning Loss for Active Learning】— https://arxiv.org/abs/1905.03677%3Fcontext%3Dcs.CV
VAAL
【Variational Adversarial Active Learning】— https://arxiv.org/abs/1904.00370
5. 应用场景
由于主动学习解决的是如何从无标签数据中选择价值高的样本进行标注,所以在数据标签难以获得、标注成本大的场景和实际问题中被广泛应用。
互联网大数据相关的应用:在互联网的大数据场景中,无标签的数据不计其数,但是又不可能把所有的数据都打上标签。在有限的资金和时间下,最有效的方法就是利用主动学习挑选最有价值的样本交给人去打标签。例如,
【阿里巴巴淘系技术】— https://www.zhihu.com/question/265479171/answer/1495497483
【中科智云全球首发全新主动学习算法框架,颠覆传统大量样本和人力标注模式】— https://www.ofweek.com/ai/2021-07/ART-201713-8210-30509389.html
在安全风控异常检测等领域,异常数据远远少于正常的数据,而对网络上的大量数据都进行标注也是极其不合理的,但是主动学习能够选择性地标注这些数据。
无人驾驶等机器人领域的应用:在很多机器人领域,都需要收集大量的有标签数据来训练。尤其是非常火的无人驾驶领域。在无人驾驶领域,无人驾驶汽车对环境的感知尤为重要,感知的好坏直接影响决策的质量,对无人驾驶汽车的安全性有至关重要的作用。感知模型多用深度学习构建,数据的重要性不言而喻,尤其是标注数据。而真实场景的无人驾驶环境种类多、复杂,为了保证模型性能,大多数公司需要利用汽车在实际场景中运行收集到的图像、点云等数据进行训练。面对这样庞大的数据量,给每一个样本都打上标签几乎是不可能实现的任务,而利用主动学习选择最有价值的样本(可能是当前模型预测的不确定性大)再人工标注,继续训练模型,从而尽可能地提高模型的性能,提高了稳定性和安全性。例如,特斯拉等
【特斯拉挑战视觉极限】— https://www.bilibili.com/read/cv7621643
[主动学习如何改善自动驾驶夜间行人检测【NVIDIA】]— https://www.bilibili.com/video/BV1xV411o72V/
【Waymo和特斯拉背后的训练系统究竟有什么特别之处?】— https://zhuanlan.zhihu.com/p/400834629
智能医疗诊断等领域:在医疗领域,深度学习的发展为包括诊断在内的多个方面带来了革命性的发展。数据驱动的方法必然需求大量的有标注数据,而标注医疗图像不仅耗时耗力,而且需要特定的专业知识,所以利用主动学习选择模型难以预测的样本进行选择地标注是非常有实际意义的。有很多论文在研究主动学习在医疗领域的应用,但在实际应用和落地中,医疗诊断面临的最首要的问题还是精度和泛化性能。由于医疗数据是小样本,这些最重要和最基本的问题没有被彻底解决,所以主动学习的热度并不大。但是还是有一些公司在应用,例如腾讯AI Lab使用主动学习和难例挖掘方案
【中国首款智能显微镜获批进入临床:病理诊断AI化,腾讯AI Lab打造】— https://new.qq.com/omn/20200409/20200409A0BGWI00.html
在我看来,医疗数据获得的量本身就少的话,就没必要应用主动学习了,因为在有限的样本下,即使都标注都很难达到一个满意的性能,更别说去做选择了。但是真正有需求的场景是,
1. 有大量的无标签医疗数据,需要从中选择有价值的进行标注,例如从视频数据(胃肠镜视频)标注图像进行检测等;
2. 真正实现基本性能,能够落地部署后,仍需要长期在使用过程中收集数据,进行标注,但是由于这个过程是一直持续下去,长久的工作,所以对于这样大量的无标签数据也需要进行主动学习选择标注。
总之,主动学习应用的场景是针对有大量无标签数据(至少不缺),如何节省标注工作量使得模型达到满意的性能。在深度学习爆炸的时代,各种任务和应用都考虑采用数据驱动的learning的方法来解决,这就对数据的需求更高了。实际应用中,既不可能完全放弃标签,也不可能放弃无标注数据,而主动学习恰恰能够提供一个较合理的权宜之计,既要标注有价值的数据,又不需要全部标注,选择性地标注。
6. 实际应用可能存在的问题
虽然考虑到主动学习的出发点和要解决的问题都比较实际,但是目前的主动学习方法在实际应用的话还是存在一些问题。
性能不稳定:制约主动学习最大的问题就是性能不稳定。主动学习是根据自己指定的选择策略从样本中挑选,那么这个过程中策略和数据样本就是影响性能的两个很重要的因素。对于非常冗余的数据集,主动学习往往会比随机采样效果要好,但是对于样本数据非常多样,冗余性较低的数据集,主动学习有的时候会存在比随机采样还差的效果。数据样本的分布还影响不同主动学习的方法,比如基于不确定性的方法和基于多样性的方法,在不同数据集上的效果并不一致,这种性能的不稳定是制约人们应用主动学习的一个重要因素。在实际应用中,需要先根据主动学习进行数据选择和标注,如果此时的策略还不如随机采样,人们并不能及时改变或者止损,因为数据已经被标注了,沉没成本已经产生了。而优化网络结构和性能的这些方法就不存在这个问题,人们可以一直尝试不同的方法和技巧使得性能达到最好,修改和尝试的损失很小。而主动学习被要求得更加苛刻,几乎需要将设计好的策略拿来直接应用就必须要work才行,如果不work,那些被选择的样本还是被标注了,还是损失时间和金钱。苛刻的要求和不稳定的性能导致人们还不如省下这个精力,直接采用随机的标注方式。
脏数据的挑战:现在几乎所有的论文都在公开的数据集、现成的数据集上进行测试和研究。而这些数据集其实已经被选择和筛选过了,去除了极端的离群值,甚至会考虑到样本平衡,人为的给少样本的类别多标注一些,多样本的类别少标注一些。而实际应用中,数据的状况和这种理想数据集相差甚远。主动学习常用不确定性的选择策略,不难想象,噪声较大的样本甚至离群值总会被选择并标注,这种样本可能不仅不会提升模型的性能,甚至还会使性能变差。实际中还存在OOD(out of distribution)的问题,例如想训练一个猫狗分类器,直接从网络中按关键字搜索猫狗收集大量图片,里边可能存在一些老虎、狮子、狼等不在猫狗类别的无关样本,但是他们的不确定性是非常高的,被选中的话,并不会提升模型的性能。
难以迁移:主动学习是一种数据选择策略,那么实际应用中必然需求更通用、泛化性更好的主动学习策略。而目前的主动学习策略难以在不同域、不同任务之间进行迁移,比如设计了一个猫狗分类任务的主动学习策略,基于不确定性或多样性,达到了较好的性能,现在需要做一个新的鸡鸭分类的任务,那么是否还需要重新设计一个策略?如果任务是病变组织的分类呢?由于不同任务的数据分布特点可能不一样,不同任务的难易不一样,无法保证主动学习的策略能够在不同数据不同任务中通用,往往需要针对固定的任务设计一个主动学习策略。这样就耗费了精力,如果能有一个通用性好的主动学习策略,那么就可以被不同任务迁移,被更广泛地应用,甚至直接将其部署为通用标注软件,为各种任务、数据集,提供主动选择和标注功能。
交互不便:数据选择策略与标注过程联系紧密,理想的流程是,有一个整合的软件能够提供主动数据选择,然后提供交互界面进行标注,这就是将主动学习流程与标注软件结合。仅有高效的主动学习策略,而不方便标注交互,也会造成额外的精力浪费。在流程上,现在主动学习普遍是选择出一批待标注的样本后,交给人们去标注,而期望人们能尽快标注交给模型,模型继续训练后再次选择。人们标注的时候,模型既不能训练,主动学习也不进行其他操作,是个串行的过程,需求等待人工标注结束后,才能进行接下来的训练。这样的流程就不那么方便和高效,想象把主动学习+标注的系统给医生应用,策略先选出了一些样本,医生仅标注这些样本就标注了几天,然后再给模型训练,模型训练一段时间后,又选择出一些样本给医生,医生和模型互相等待对方的操作,降低了效率和便利性。
7. 最新研究方向及论文推荐
下面我介绍一些主动学习目前最新的阅读价值较高的论文,供大家把握研究方向和热点。如果大家有兴趣,可以持续关注我github上的【awesome-active-learning】— https://github.com/baifanxxx/awesome-active-learning 中的 paper list,我会实时更新有价值的主动学习方面的工作,供大家学习和交流。
主动学习问题和方法的探究
目前主动学习的基本方法和问题还存在一些不足,有一些最新的方法试图解决这些问题。
【Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering】— https://arxiv.org/abs/2107.02331(作者之一,李飞飞)
主动学习有望缓解监督式机器学习的海量数据需求:它已成功地将样本效率提高了一个数量级,例如主题分类和对象识别等传统任务。然而,作者发现与这一现象形成鲜明对比的是:在视觉问答任务的 5 个模型和 4 个数据集中,各种各样的主动学习方法未能胜过随机选择。为了理解这种差异,作者在每个示例的基础上分析了 8 种主动学习方法,并将问题确定为集体异常值——主动学习方法更喜欢获取但模型无法学习的一组示例(例如,询问文本的问题在图像中或需要外部知识)。通过系统的消融实验和定性可视化,作者验证了集体异常值是导致基于池的主动学习退化的普遍现象。值得注意的是,作者表明,随着主动学习池中集体异常值的数量减少,主动学习样本效率显着提高。
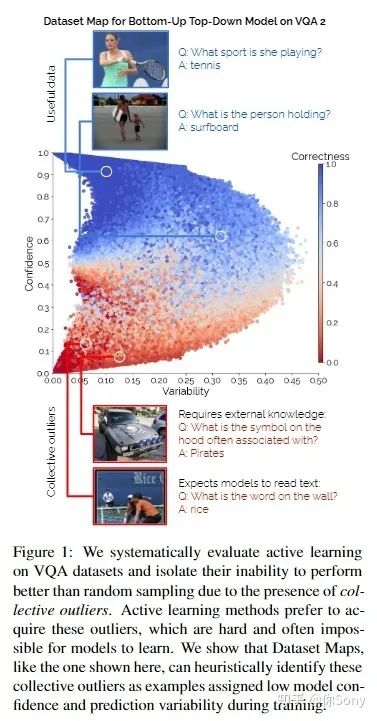
【Contrastive Coding for Active Learning Under Class Distribution Mismatch】https://openaccess.thecvf.com/content/ICCV2021/html/Du_Contrastive_Coding_for_Active_Learning_Under_Class_Distribution_Mismatch_ICCV_2021_paper.html
基于以下假设:标记数据和未标记数据是从同一类分布中获得的,主动学习 (AL) 是成功的。然而,它的性能在类别分布不匹配的情况下会恶化,其中未标记的数据包含许多标记数据的类分布之外的样本。为了有效地处理类分布不匹配下的AL问题,作者提出了一种基于对比编码的 AL 框架,名为 CCAL。与现有的 AL 方法专注于选择信息量最大的样本进行标注不同,CCAL 通过对比学习提取语义和独特的特征,并将它们组合在查询策略中,以选择具有匹配类别的信息量最大的未标记样本。理论上,作者证明了 CCAL 的 AL 误差具有严格的上限。
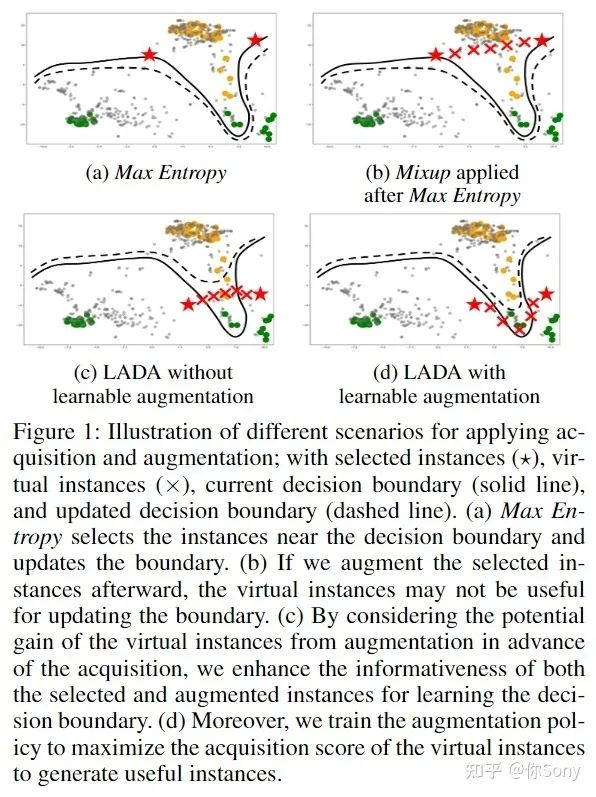
【LADA: Look-Ahead Data Acquisition via Augmentation for Active Learning】— https://arxiv.org/abs/2011.04194
在主动学习的获取过程中尚未考虑从数据增强产生的虚拟实例的潜在收益。在数据获取的过程中,数据增强将选择并生成对训练模型提供信息的数据实例。因此,作者提出了通过增强或 LADA 的前瞻数据采集来集成数据采集和数据增强。在获取过程之前,LADA 考虑 1) 选择未标记的数据实例和 2) 通过数据增强生成的虚拟数据实例。此外,为了增强虚拟数据实例的信息量,LADA 优化了数据增强策略以最大化预测获取分数,从而产生了 InfoMixup 和 InfoSTN 的提议。由于 LADA 是一个可推广的框架,作者试验了各种采集和增强方法的组合。
主动学习与半监督学习结合
由于半监督学习展示出了优异的性能,在标签不足的情况下,如果能将主动学习与半监督学习结合,将会取得更优异的性能。
【Semi-Supervised Active Learning for Semi-Supervised Models: Exploit Adversarial Examples With Graph-Based Virtual Labels】— https://openaccess.thecvf.com/content/ICCV2021/html/Guo_Semi-Supervised_Active_Learning_for_Semi-Supervised_Models_Exploit_Adversarial_Examples_With_ICCV_2021_paper.html
尽管当前主流方法开始结合 SSL 和 AL(SSL-AL)来挖掘未标记样本的多样化表示,但这些方法的全监督任务模型仍然仅使用标记数据进行训练。此外,这些方法的 SSL-AL 框架存在不匹配问题。在这里,作者提出了一个基于图的 SSL-AL 框架来释放 SSL 模型的能力并进行有效的 SSL-AL 交互。在该框架中,SSL 利用基于图的标签传播为未标记的样本提供伪标签,渲染 AL 样本的结构分布并提升 AL。AL 在决策边界附近找到样本,利用对抗性示例帮助 SSL 执行更好的标签传播。闭环中的信息交换实现了SSL和AL的相互增强。
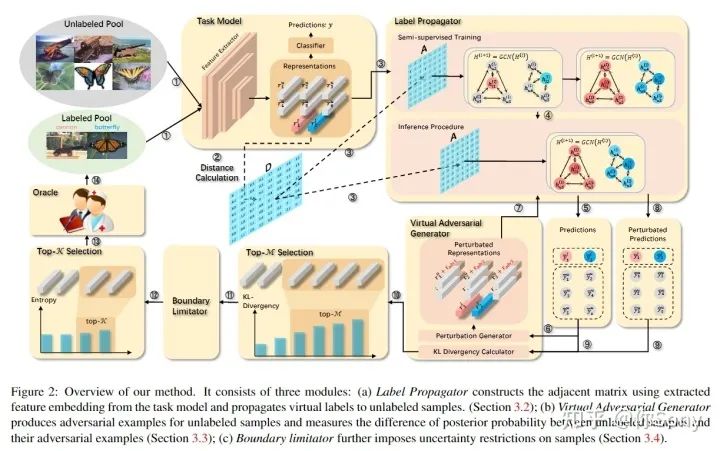
主动学习与无监督域自适应结合
无监督域自适应要对齐目标域与源域,使模型利用源域的数据和标签,在无标签的目标域上取得较好的性能。目前出现一些工作考虑源域和目标域的关系,设计了主动学习策略提升模型在目标域的性能。
【Multi-Anchor Active Domain Adaptation for Semantic Segmentation】— https://arxiv.org/abs/2108.08012
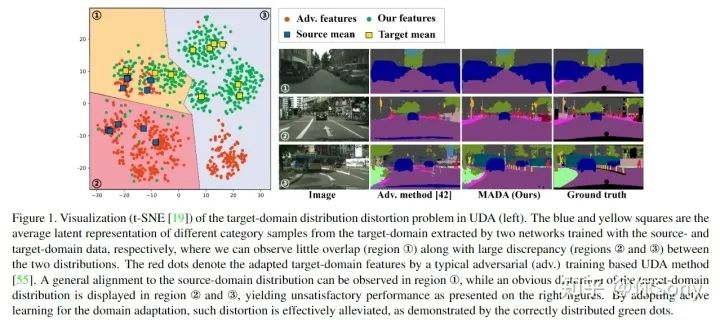
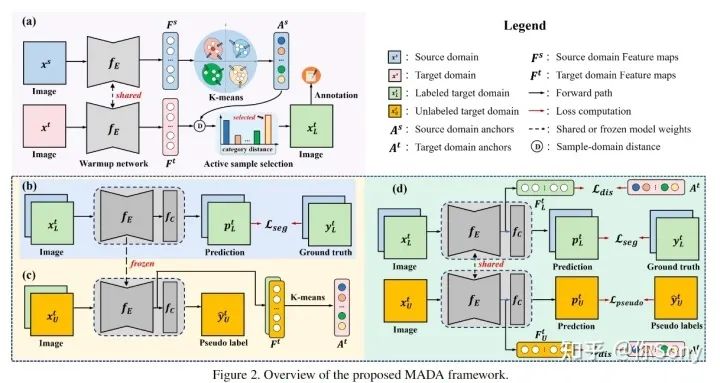
将目标域的分布无条件地与源域对齐可能会扭曲目标域数据的特有的信息。为此,作者提出了一种新颖的基于多锚点的主动学习策略,以协助域自适应语义分割任务。通过创新地采用多个点而不是单个质心,可以更好地将源域表征为多模态分布,实习从目标域中选择更具代表性和互补性的样本。手动注释这些样本的工作量很小,可以有效缓解目标域分布的失真,从而获得较大的性能增益。另外还采用多锚策略来对目标分布进行建模。通过软对齐损失,对多个锚点周围紧凑的目标样本的潜在表示进行正则化,可以实现更精确的分割。
主动学习与知识蒸馏结合
知识蒸馏过程中,teacher给student传递知识,但是什么样的样本能够帮助这一过程,也是主动学习可以研究的一个方向。
【Active Learning for Lane Detection: A Knowledge Distillation Approach】— https://openaccess.thecvf.com/content/ICCV2021/html/Peng_Active_Learning_for_Lane_Detection_A_Knowledge_Distillation_Approach_ICCV_2021_paper.html
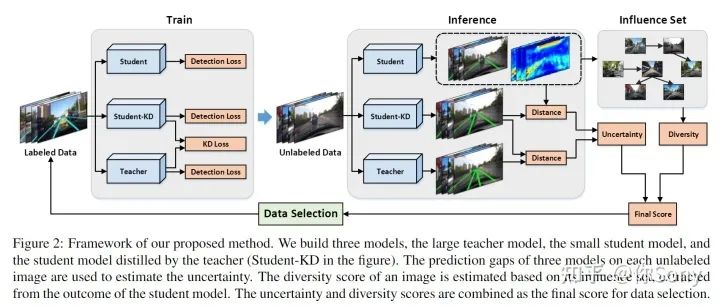
作者发现现有的主动学习方法在车道检测方面表现不佳,原因是两方面的。一方面,大多数方法基于熵来评估数据不确定性,这在车道检测中是不可取的,因为它鼓励选择车道很少甚至根本没有车道的图像。另一方面,现有的方法没有意识到车道标注的噪声,这是由严重遮挡和车道标记不清晰引起的。在本文中,作者构建了一个新颖的知识蒸馏框架,并基于student模型所学的知识评估图像的不确定性。作者表明,所提出的不确定性度量克服了上述两个问题。为了减少数据冗余,作者研究了图像样本的影响集(influence set),并提出了一种新的多样性度量。最后,作者结合了不确定性和多样性指标,提出了一种用于数据选择的贪婪算法。
主动学习与对比学习结合
对比学习最近势头比较猛,最近也有主动学习与对比学习结合解决对比学习的问题,大家可以欣赏一下。
【Active Contrastive Learning of Audio-Visual Video Representations】— https://arxiv.org/abs/2009.09805
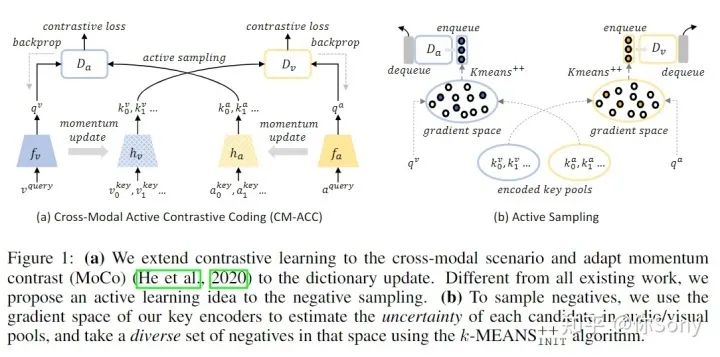
对比学习已被证明可以通过最大化实例的不同视图之间的互信息 (MI) 的下限来生成音频和视觉数据的可概括表示。然而,获得严格的下限需要 MI 中的样本大小指数,因此需要大量的负样本。我们可以通过构建一个大型的基于队列的字典来合并更多的样本,但是即使有大量的负样本,性能提升也存在理论上的限制。作者假设随机负采样导致高度冗余的字典,导致下游任务的次优表示。在本文中,作者提出了一种主动对比学习方法,该方法构建了一个actively sampled字典,其中包含多样化和信息丰富的样本,从而提高了负样本的质量,并提高了数据中互信息量高的任务的性能,例如,视频分类。
利用强化学习进行主动学习
【Reinforced active learning for image segmentation】— https://arxiv.org/abs/2002.06583
基于学习的语义分割方法有两个固有的挑战。首先,获取像素级标签既昂贵又耗时。其次,现实的分割数据集是高度不平衡的:某些类别比其他类别丰富得多,使性能偏向于最具代表性的类别。
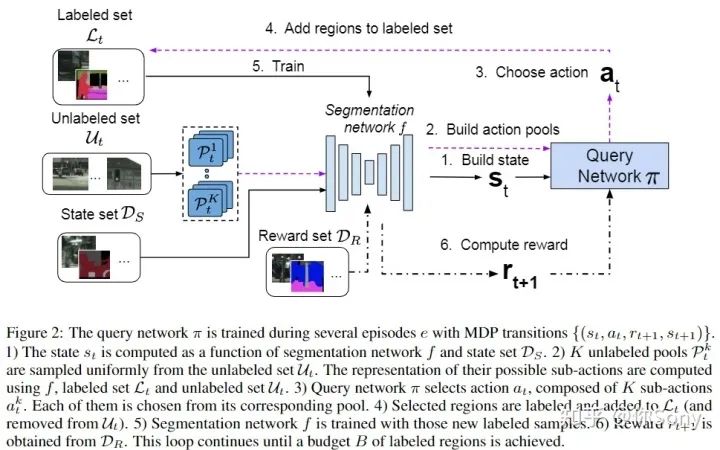
在本文中,作者感兴趣的是基于池的方式进行人工标记工作,最大限度地减少这种工作,同时最大限度地提高分割模型在测试集上的性能。作者提出了一种新的基于深度强化学习 (RL) 的语义分割主动学习策略。智能体学习一种策略,从未标记的数据池中选择一小部分信息丰富的图像区域进行标记。区域选择决策是基于被训练的分割模型的预测和不确定性做出的。作者的方法提出了一种用于主动学习的DQN,使其能适应大规模的语义分割问题。作者在 CamVid和大规模数据集 Cityscapes 中测试。在 Cityscapes 上,在相同性能下,作者的基于深度强化学习的区域的 DQN 方法比最具竞争力的基线减少大约 30% 的额外标记数据。此外,作者发现与基线相比,作者的方法选择了更多代表性不足的类别标签,从而提高它们的性能并有助于减轻类别不平衡。
主动学习在点云方面
点云比图像的标注时间更长更费精力,尤其是像素级的点云标注。近期主动学习在点云方面的工作渐渐崭露头角,而且效果非常惊人,值得期待。下面我介绍一篇有代表性的点云语义分割的工作。
【ViewAL: Active Learning with Viewpoint Entropy for Semantic Segmentation】— https://arxiv.org/abs/1911.11789
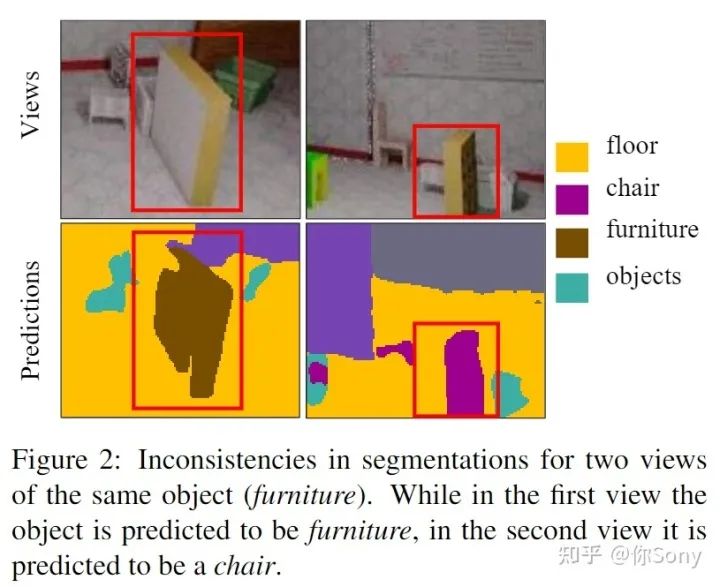
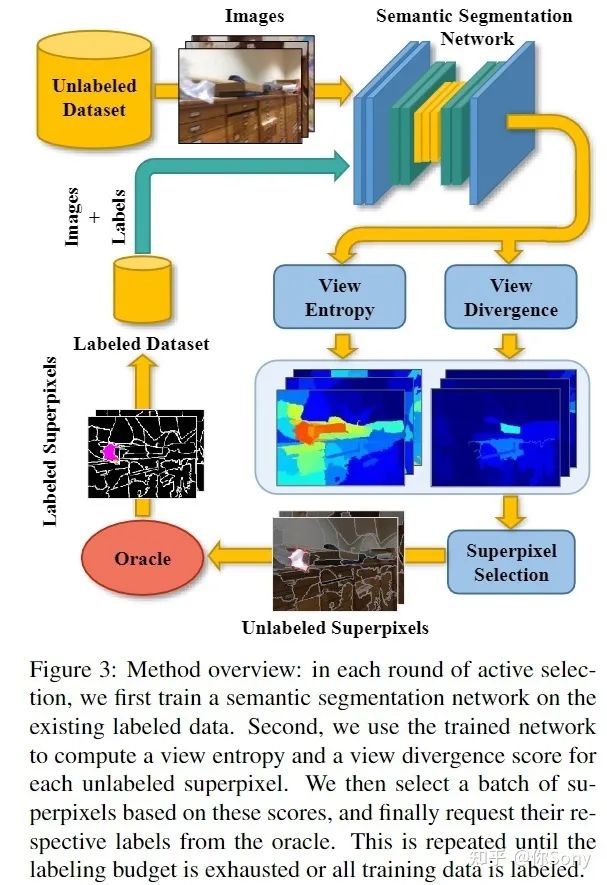
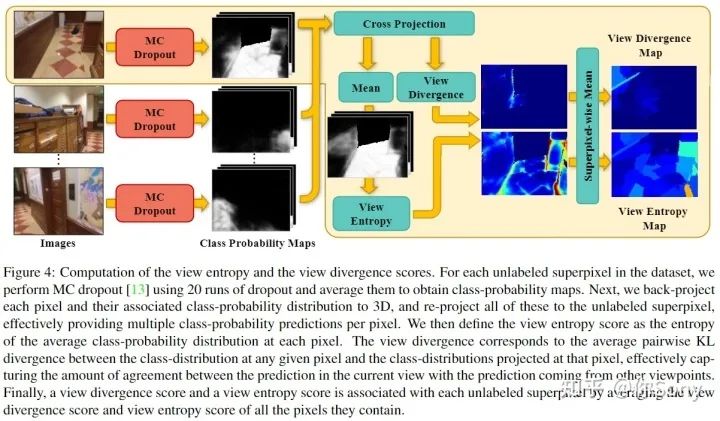
作者提出了 ViewAL,这是一种新颖的语义分割主动学习策略,它利用了多视图数据集中的视点一致性。作者的核心思想是,跨视点的模型预测的不一致提供了非常可靠的不确定性度量,并鼓励模型在不考虑观察对象的视点的情况下表现良好。为了结合这种不确定性度量,作者引入了一种新的视点熵公式,这是作者主动学习策略的基础。此外,作者提出了超像素级别的不确定性计算,它利用了分割任务中固有的局部信息,直接降低了注释成本。视点熵和超像素的联合使用有效地选择了具有高度信息量的样本。
主动学习在目标检测方面
最新也有一些主动学习的文章开始结合到目标检测中,针对目标检测定义策略。目标检测不仅存在分类还存在定位,所以对于图像的不确定性定义和建模更加多样,使得更容易创新自己的主动学习方法,大家可以尝试做做这方面的工作。
【Multiple instance active learning for object detection】— https://arxiv.org/abs/2104.02324
尽管用于图像识别的主动学习取得了实质性进展,但仍然缺乏指定用于目标检测的实例级主动学习方法。在本文中,作者提出了多实例主动目标检测(MI-AOD),通过观察实例级的不确定性来选择信息量最大的图像进行检测器训练。MI-AOD 定义了一个实例不确定性学习模块,它利用在标记集上训练的两个对抗性实例分类器的差异来预测未标记集的实例不确定性。MI-AOD 将未标记的图像视为实例包,将图像中的特征锚点视为实例,并通过以多实例学习 (MIL) 方式重新加权实例来估计图像的不确定性。反复迭代实例不确定性学习和重加权有助于抑制噪声实例,弥合实例不确定性和图像级不确定性之间的差距。
总结
总而言之,主动学习现在还有很多点可以继续研究,包括但不限于:
从主动学习基本理论和问题出发,完善和改进;
与其他learning方法或概念结合,改进主动学习或该方法,例如半监督、域自适应、知识蒸馏和强化学习等等;
应用到新的背景和任务(和主动学习结合的paper少的)中,例如点云分类分割、医疗图像、目标检测等等。
......
既可以在现有的方法的基础上改进,又可以针对新的特定任务和具体问题设计自己的主动学习策略。无论是哪方面,主动学习都是存在很多继续研究的点。
主动学习既有重要的应用价值又还存在着一些问题,是学术界和工业界都可以进行研究的点。希望对主动学习感兴趣的朋友,可以一起多多讨论和交流。我以后也会在知乎和【awesome-active-learning】— https://github.com/baifanxxx/awesome-active-learning 上持续为大家更新一些主动学习领域优异的工作。
整理不易,
点
赞
三连
↓