
主动学习(Active Learning) 概述、策略和不确定性度量

来源:DeepHub IMBA 本文约2400字,建议阅读9分钟
主动学习是解决标注数据问题的一个方向,并且是一个非常好的方向。
主动学习是一种学习算法可以交互式查询用户(teacher 或 oracle),用真实标签标注新数据点的策略。主动学习的过程也被称为优化实验设计。 主动学习的动机在于认识到并非所有标有标签的样本都同等重要。 主动学习通过为专家的标记工作进行优先级排序可以大大减少训练模型所需的标记数据量。降低成本,同时提高准确性。 主动学习是一种策略/算法,是对现有模型的增强。而不是新模型架构。 主动学习容易理解,不容易执行。
主动学习背后的关键思想是,如果允许机器学习算法选择它学习的数据,这样就可以用更少的训练标签实现更高的准确性。——Active Learning Literature Survey, Burr Settles
主动学习简介
主动学习的策略
首先需要做的是需要手动标记该数据的一个非常小的子样本。 一旦有少量的标记数据,就需要对其进行训练。该模型当然不会很棒,但是将帮助我们了解参数空间的哪些领域需要首标记。 训练模型后,该模型用于预测每个剩余的未标记数据点的类别。 根据模型的预测,在每个未标记的数据点上选择分数(在下一节中,将介绍一些最常用的分数) 一旦选择了对标签进行优先排序的最佳方法,这个过程就可以进行迭代重复:在基于优先级分数进行标记的新标签数据集上训练新模型。一旦在数据子集上训练完新模型,未标记的数据点就可以在模型中运行并更新优先级分值,继续标记。
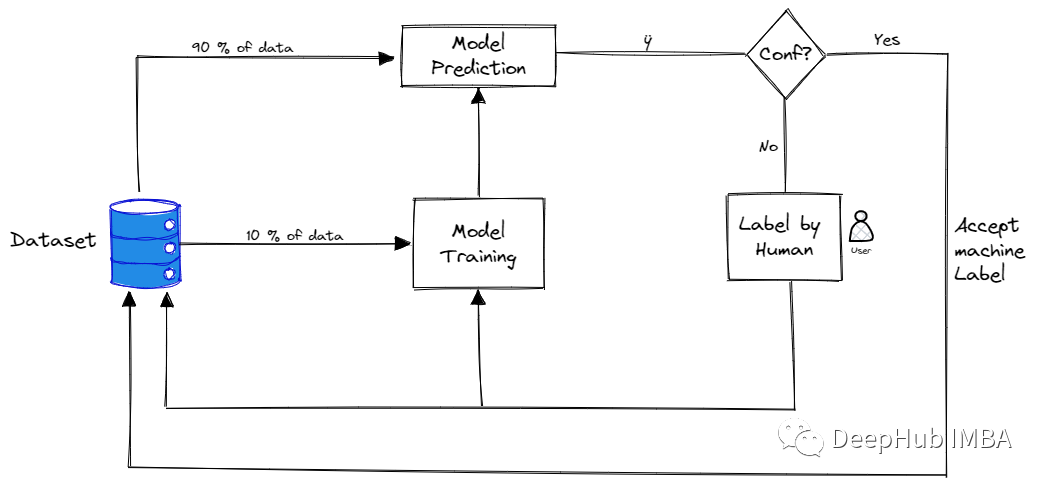
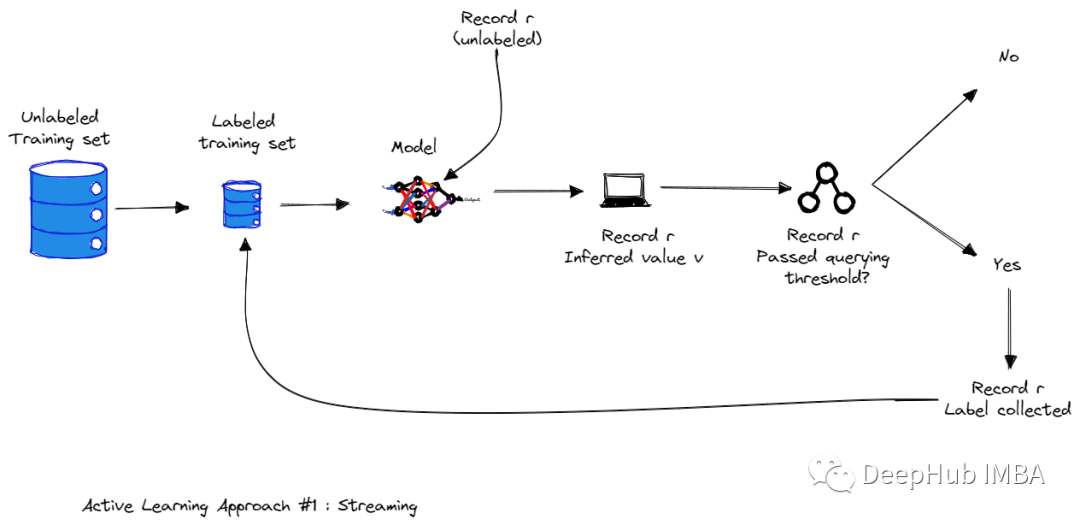

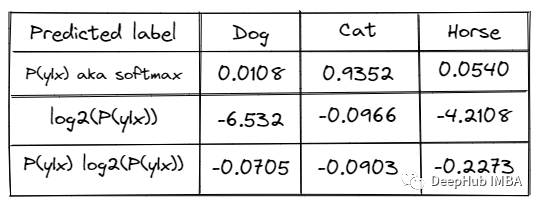
不确定性度量
{"Prediction": {"Label": "Cat","Prob": {"Cat": 0.9352784428596497,"Horse": 0.05409964170306921,"Dog": 0.038225741147994995,}}}
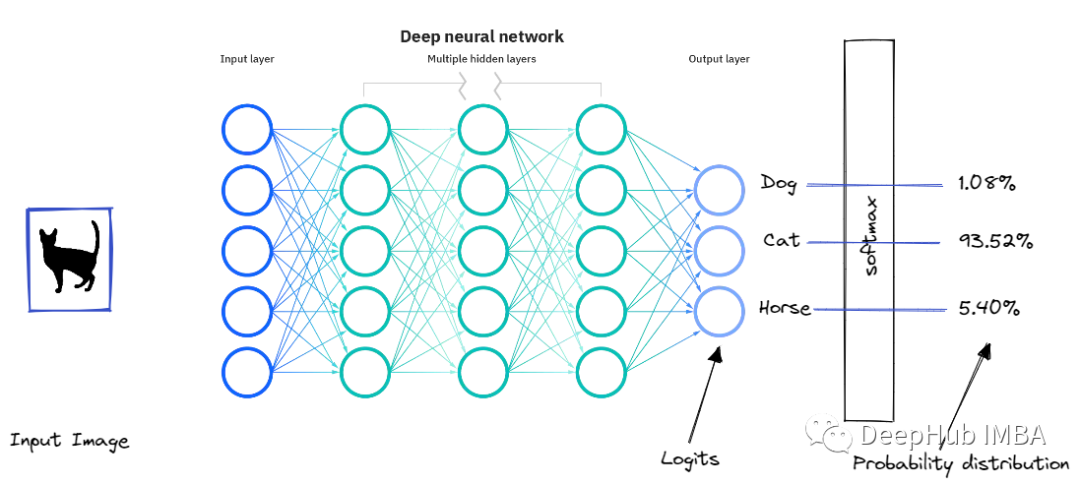
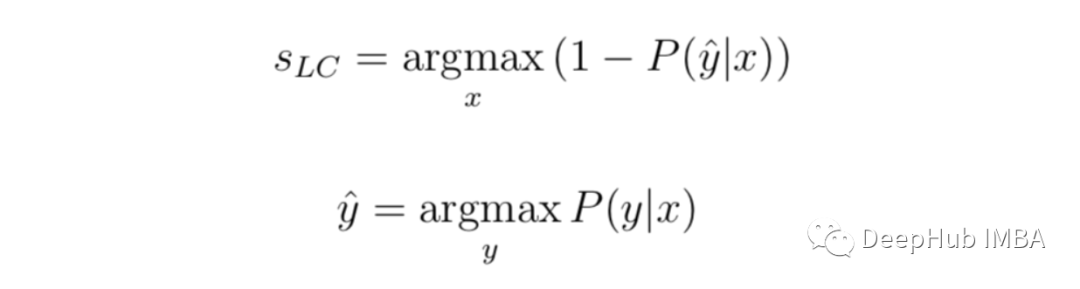

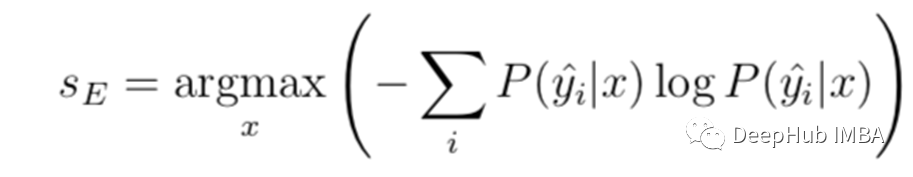
总结
编辑:黄继彦
评论