
事务隔离:为什么你改了我还看不见?
预热
比较喜欢的一段话:不经一番寒彻骨,怎得梅花扑鼻香,学习是枯燥的请大家坚持!这篇文章的是向丁奇老师学习的。不懂的自己搜一下哈! 阅读这篇文章大概需要25分钟!
大家好前面我们大概了解了一个更新语句的执行流程,并介绍了执行过程中涉及 两种重要的日志模块 innodb的redo log,server层的binlog。相信你还记得他们两者之间的区别以及为什么要有二阶段提交这一流程?今天我们介绍一下数据库的事务一些知识点!
开始
隔离性与隔离级别
谈到事务绝对是要谈一些隔离性与隔离级别的。首先隔离级别就是大家常说的ACID。对应的分别就是原子性,一致性,隔离性,持久性。今天主要介绍一下隔离性。
先介绍一下常见的事务问题,当多个事务同时执行时会出现脏读,不可重复读,幻读等问题,为了 解决这一问题,隔离性级别的概念就出来了,因为只有真正把每个事务做到隔离这一才不会互相访问,冲突。
世间万物相生相克,如果想保证效率吗,自然要牺牲安全。如果要保证安全,必然要牺牲效率。隔离级别主要分为:读未提交,读提交,可重复读,串行化。下面我们一一解释一下。
读未提交代表着,当一个事务执行时,另一个事务也执行了并且访问了同一个数据,而且还是支持访问被修改的。
读提交代表着,当一个事务执行时,另一个事务也执行了并且访问了同一个数据,只有等第一个事务提交了 第二个事务才会看到
可重复读代表着,当一个事务执行时,另一个事务也执行了并且访问了同一个数据,其中一个事务的启动时观察到的数据一定是跟结束后是一致的。未提交时候时,对其他事务是不可见的。
串行化代表着,写会加锁写,读会加读锁。用的不多。
下面举个简单的例子,论述一下四中隔离级别的数据变化。

读未提交时,V1是2(事务2还没有提交但是已经被看到了),v2是2,v3也是2
读提交时,v1是1(事务2没有提交),v2是2(因为事务2提交了),v3是2(已经被事务2改过了)
可重复读
可重复读,v1是1(不受外事务干扰),v2是1(不受外事务干扰),v3是2(正常数值)
串行化,谁先修改谁就先锁住,等另一个事务提交之后再继续行动,如果谁都不放那就死锁啦(后续会讲述这个问题)
事务隔离的实现
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。
在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。
在“读提交”隔离级别下,这个视图是在每个 SQL 语句开始执行的时候创建的。
“读未提交”隔离级别下直接返回记录上的最新值,没有视图概念;
“串行化”隔离级别下直接用加锁的方式来避免并行访问。
我们可以看到在不同的隔离级别下,数据库行为是有所不同的。Oracle 数据库的默认隔离级别其实就是“读提交”,因此对于一些从 Oracle 迁移到 MySQL 的应用,为保证数据库隔离级别的一致,你一定要记得将 MySQL 的隔离级别设置为“读提交”。
配置的方式是,将启动参数 transaction-isolation 的值设置成 READ-COMMITTED。你可以用 show variables 来查看当前的值。 show variables like 'transaction_isolation';
具体实现 read-view 展开说明一下 可重复读
在 MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。
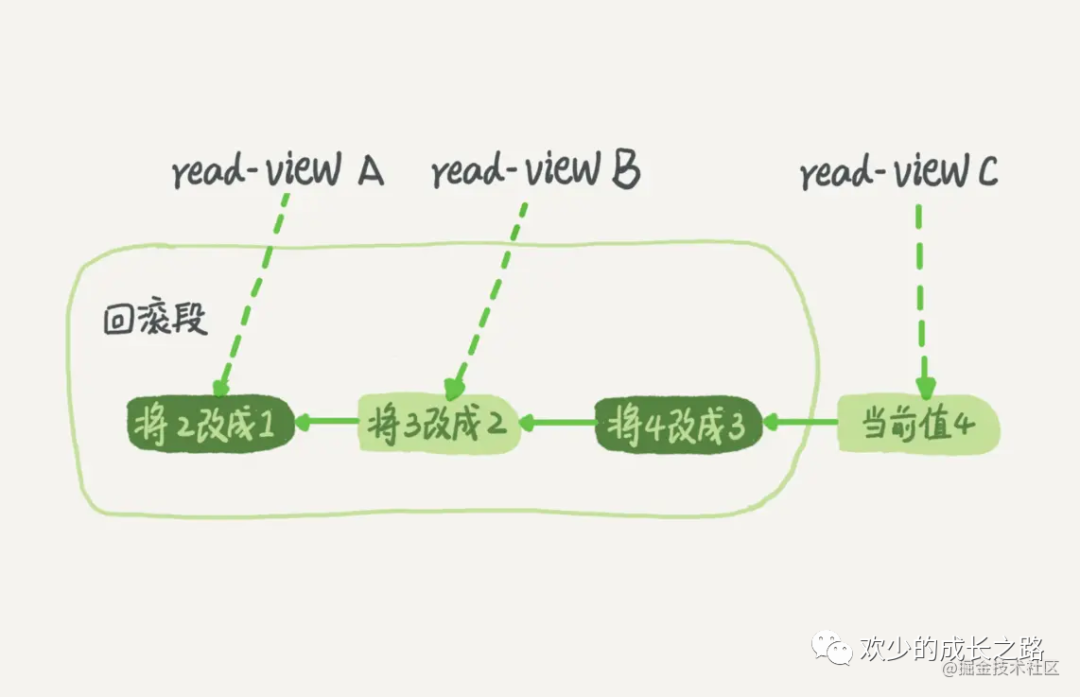
当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
同时你会发现,即使现在有另外一个事务正在将 4 改成 5,这个事务跟 read-view A、B、C 对应的事务是不会冲突的。
你一定会问,回滚日志总不能一直保留吧,什么时候删除呢?答案是,在不需要的时候才删除。也就是说,系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。
什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的 read-view 的时候。
基于上面的说明,我们来讨论一下为什么建议你尽量不要使用长事务。长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。在 MySQL 5.5 及以前的版本,回滚日志是跟数据字典一起放在 ibdata 文件里的,即使长事务最终提交,回滚段被清理,文件也不会变小。我见过数据只有 20GB,而回滚段有 200GB 的库。最终只好为了清理回滚段,重建整个库。
除了对回滚段的影响,长事务还占用锁资源,也可能拖垮整个库,这个我们会在后面讲锁的时候展开。
事务的启动方式
第一种启动方式是 显式启动:通过start transaction或者begin启动事务,配套的是commit,rollback
第二种启动方式是 先设置一下数据库配置 set autocommit=0 这个命令会关闭线程的自动提交。也就是说如果只执行一个select这个事务也就启动了,不会自动提交。直到你主动执行commit或rollback才会停止。
有些客户端连接框架会默认连接成功后先执行一个 set autocommit=0 的命令。这就导致接下来的查询都在事务中,如果是长连接,就导致了意外的长事务。、
因此,我会建议你总是使用 set autocommit=1, 通过显式语句的方式来启动事务。
但是有的开发同学会纠结“多一次交互”的问题。对于一个需要频繁使用事务的业务,第二种方式每个事务在开始时都不需要主动执行一次 “begin”,减少了语句的交互次数。如果你也有这个顾虑,我建议你使用 commit work and chain 语法。
在 autocommit 为 1 的情况下,用 begin 显式启动的事务,如果执行 commit 则提交事务。如果执行 commit work and chain,则是提交事务并自动启动下一个事务,这样也省去了再次执行 begin 语句的开销。同时带来的好处是从程序开发的角度明确地知道每个语句是否处于事务中。
你可以在 information_schema 库的 innodb_trx 这个表中查询长事务,比如下面这个语句,用于查找持续时间超过 60s 的事务。

结尾
我们下期见。接下来打算更新一些关于索引的文章