
MySQL锁机制与事务隔离级别
日志系统主要有Redo Log(重做日志)、Undo Log和binlog(归档日志)。Redo Log是InnoDB存储引擎层的日志,binlog是MySQL Server层记录的日志, 两者都是记录了某些操作的日志(不是所有),自然有些重复(但两者记录的格式不同)

事务的原子性是通过undo log来实现的
事务的持久性是通过redo log来实现的
事务的隔离性是通过(读写锁+MVCC)来实现的
事务的一致性是通过原子性、持久性、隔离性来实现的
和Undo Log相反,Redo Log记录的是新数据的备份。在事务提交前,只将Redo Log持久化即可,不需要将数据持久化,当系统崩溃时,虽然数据没有持久化,但是Redo Log已经持久化,系统可以根据Redo Log的内容,将所有数据恢复到最新的状态。
在MySQL的InnoDB存储引擎中,锁可以分为两类:
(1)共享锁: 共享锁定是将对象数据变为只读形式,不能进行更新,所以也成为读取锁定,简称读锁。
(2)排他锁: 排他锁定是当执行插入/修改/删除操作的时候,其它事务不能读取该数据,因此也成为写入锁定,简称写锁。
(1)表级锁: 开销小、加锁快、不会出现死锁、锁定粒度大、发生锁冲突的概率最高、并发度最低。
(2)行级锁: 开销大、加锁慢、会出现死锁、锁定粒度最小、发生锁冲突的概率最低、并发度也最高。
(1) Redo Log重做日志,提供前滚操作; Undo Log是回退日志,提供回滚操作。
(2) Redo Log通常是物理日志,记录的是数据页的物理修改而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页恢复数据页,且只能恢复到最后一次提交的位置)。
(3) Undo Log用来回滚行记录到某个版本。Undo Log一般是逻辑日志,根据每行记录进行记录。
竟然说到了MySQL的日志,binlog不得不提,它记录了所有的DDL和DML语句(除了数据查询语句select),以事件形式记录,还包含语句所执行的消耗的时间。
(1) statement: 基于SQL语句的模式,某些语句中含有-些函数,例如UUID NOW等在复制过程可能导致数据不一致甚至出错。
(2)row: 基于行的模式,记录的是行的变化,很安全。但是binlog的磁盘占用会比其他两种模式大很多,在一些大表中清除大量数据时在binlog中会生成很多条语句,可能导致从库延迟变大。
(3) mixed: 混合模式,根据语句来选用是statement还是row模式。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改和删除,幻读侧重于新增。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
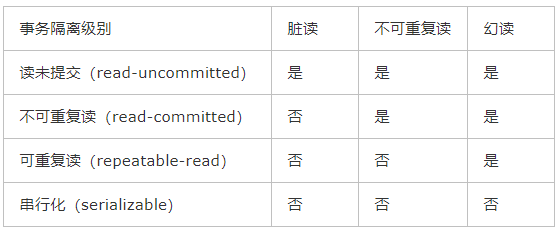
1、读未提交
(1)打开一个客户端A,并设置当前事务模式为read uncommitted(未提交读),查询表account的初始值。
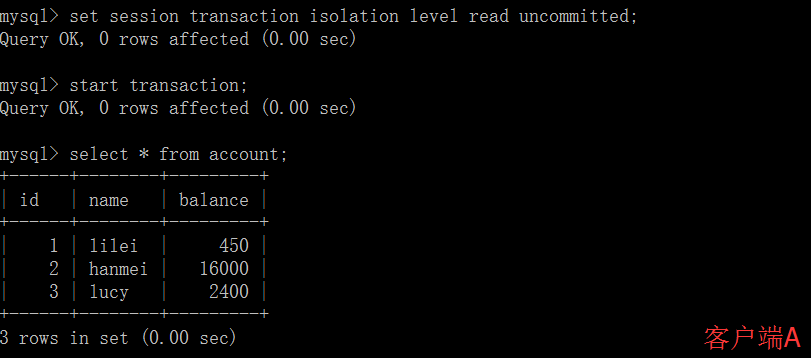
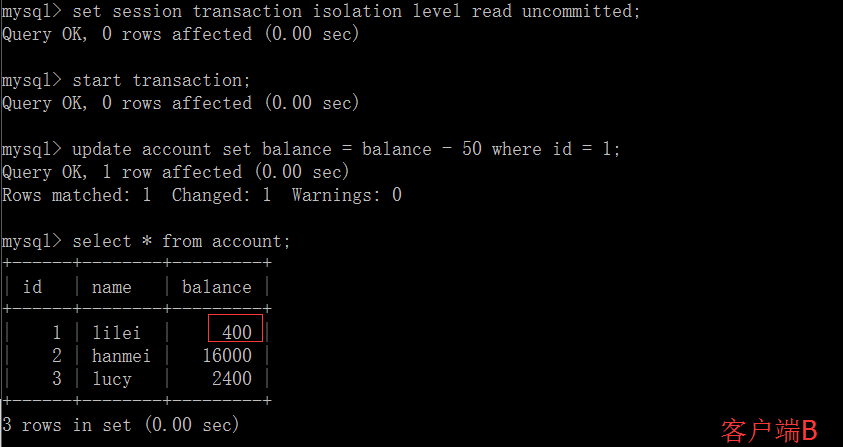
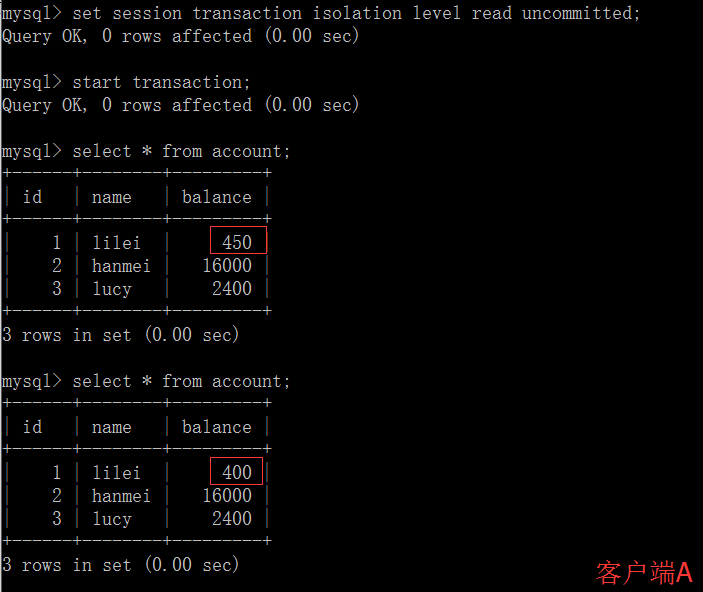
(4)一旦客户端B的事务因为某种原因回滚,所有的操作都将会被撤销,那客户端A查询到的数据其实就是脏数据。
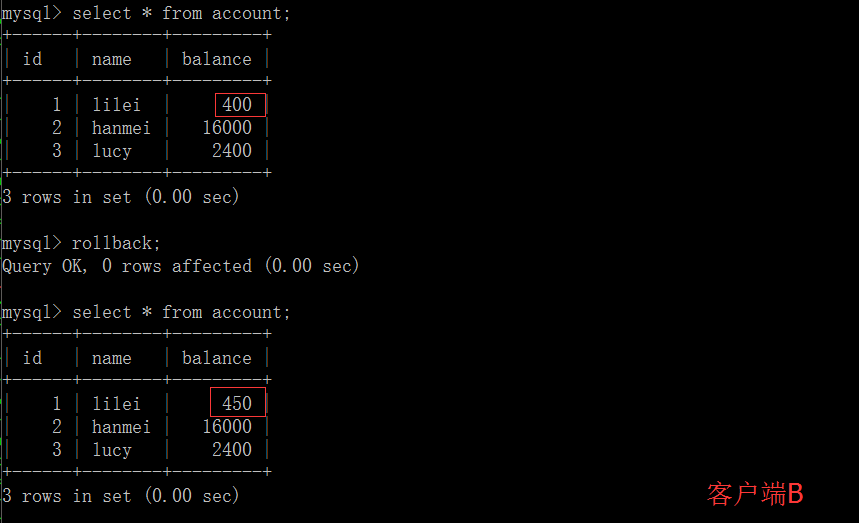
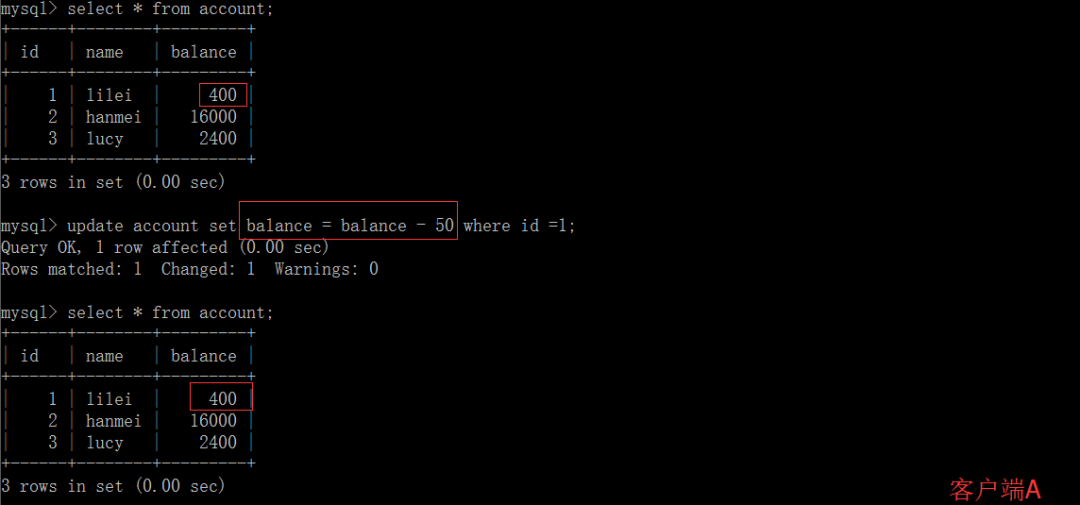
2、读已提交
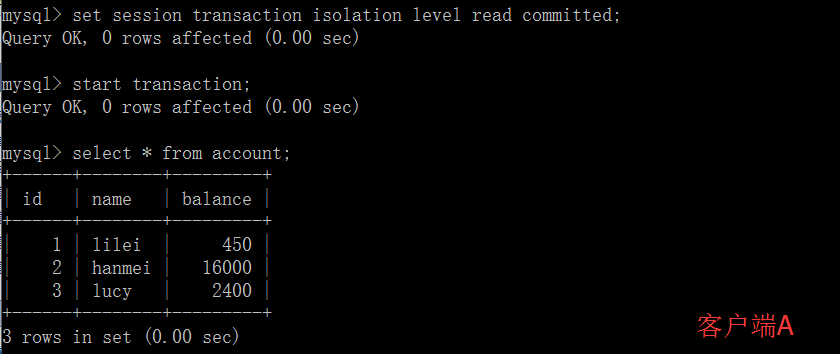
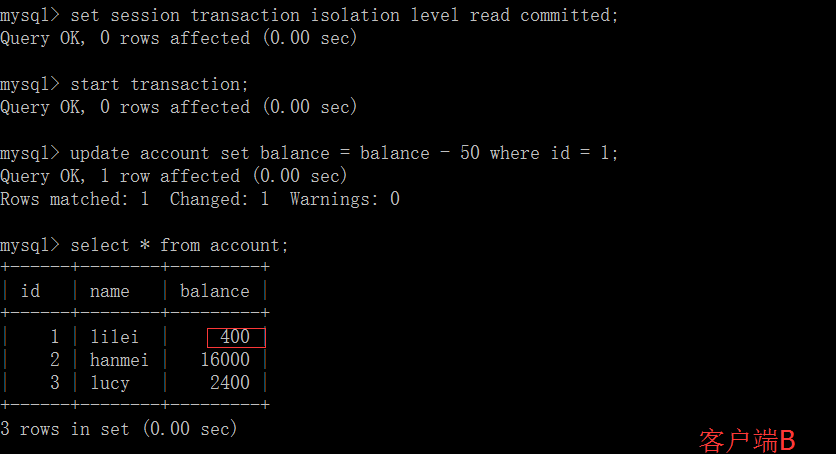
(3)这时,客户端B的事务还没提交,客户端A不能查询到B已经更新的数据,解决了脏读问题。

(4)客户端B的事务提交
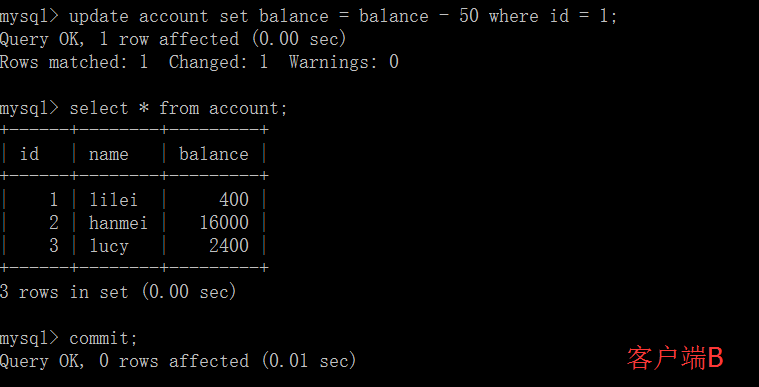
(5) 客户端A执行与上一步相同的查询,结果 与上一步不一致,即产生了不可重复读的问题。

3、可重复读
(1)打开一个客户端A,并设置当前事务模式为repeatable read,查询account表中id为4的记录。
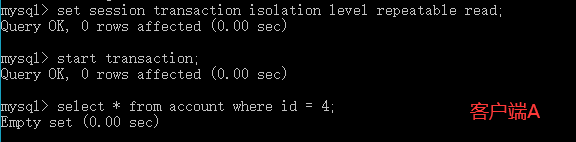
(2)在客户端A的事务提交之前,打开另一个客户端B,向account表中插入一条记录,并提交。
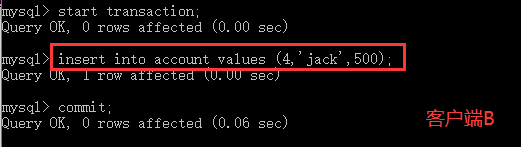
(3)在客户端B提交之后,同样地,客户端A向account表中插入id为4的记录并再次查询id为4的记录,发现主键重复但又读取不到数据,感觉像自己读过一样,这就造成了幻读。

1.微服务实战系列
4.中间件等
更多信息请关注公众号:「软件老王」,关注不迷路,软件老王和他的IT朋友们,分享一些他们的技术见解和生活故事。