
为什么会有分布式事务?你了解过吗?
对于分布式事务,相信所有人都应该很了解,为什么会有分布式事务?无论是数据量导致的分库,还是现在微服务盛行的场景都是他出现的原因。
这一篇内容还是避免不了俗套,主要的范围无非是XA、2PC、3PC、TCC,再最后到Seata。
但是,我认为这东西,只是适用于面试和理论的了解,你真要说这些方案实际生产中有人用吗?
有,但是会实现的更简单,不会套用理论来实现,大厂有大厂的解决方案,中小公司用框架或者压根就不存在分布式事务的问题。
那,为什么还要写这个?
为了你面试八股文啊,小可爱。
事务
要说分布式事务,首先还是从事务的基本特征说起。
A原子性:在事务的执行过程中,要么全部执行成功,要么都不成功。
C一致性:事务在执行前后,不能破坏数据的完整性。一致性更多的说的是通过AID来达到目的,数据应该符合预先的定义和约束,由应用层面来保证,还有的说法是C是强行为了ACID凑出来的。
I隔离性:多个事务之间是互相隔离的,事务之间不能互相干扰,涉及到不同事务的隔离级别的问题。
D持久性:一旦事务提交,数据库中数据的状态就应该是永久性的。
XA
XA(eXtended Architecture)是指由X/Open 组织提出的分布式事务处理的规范,他是一个规范或者说是协议,定义了事务管理器TM(Transaction Manager),资源管理器RM(Resource Manager),和应用程序。
事务管理器TM就是事务的协调者,资源管理器RM可以认为就是一个数据库。

2PC
XA定义了规范,那么2PC和3PC就是他的具体实现方式。
2PC叫做二阶段提交,分为投票阶段和执行阶段两个阶段。
投票阶段
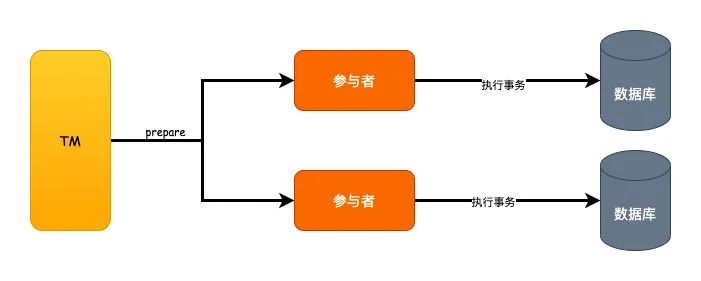
TM向所有的参与者发送prepare请求,询问是否可以执行事务,等待各个参与者的响应。
这个阶段可以认为只是执行了事务的SQL语句,但是还没有提交。
如果都执行成功了就返回YES,否则返回NO。
执行阶段
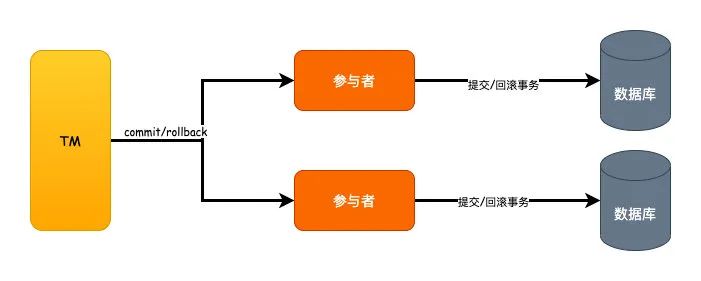
执行阶段就是真正的事务提交的阶段,但是要考虑到失败的情况。
如果所有的参与者都返回YES,那么就执行发送commit命令,参与者收到之后执行提交事务。
反之,只要有任意一个参与者返回的是NO的话,就发送rollback命令,然后执行回滚的操作。
2PC的缺陷
同步阻塞,可以看到,在执行事务的过程当中,所有数据库的资源都被锁定,如果这时候有其他人来访问这些资源,将会被阻塞,这是一个很大的性能问题。 TM单点问题,只要一个TM,一旦TM宕机,那么整个流程无法继续完成。 数据不一致,如果在执行阶段,参与者脑裂或者其他故障导致没有收到commit请求,部分提交事务,部分未提交,那么数据不一致的问题就产生了。
3PC
既然2PC有这么多问题,所以就衍生出了3PC的概念,也叫做三阶段提交,他把整个流程分成了CanCommit、PreCommit、DoCommit三个步骤,相比2PC,增加的就是CanCommit阶段。
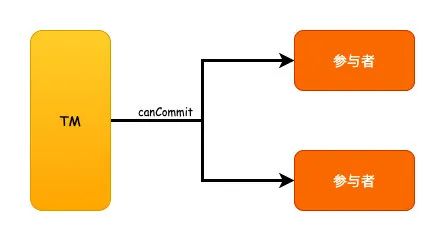
CanCommit
这个阶段就是先询问数据库是否执行事务,发送一个canCommit的请求去询问,如果可以的话就返回YES,反之返回NO。
PreCommit
这个阶段就等同于2PC的投票阶段了,发送preCommit命令,然后去执行SQL事务,成功就返回YES,反之返回NO。
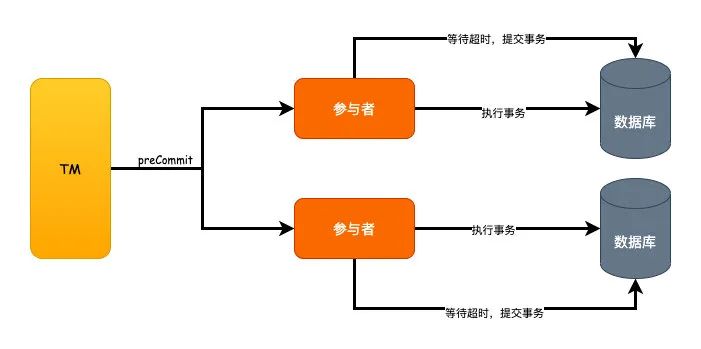
但是,这个地方的区别在于参与者有了超时机制,如果参与者超时未收到doCommit命令的话,将会默认去提交事务。
DoCommit
DoCommit阶段对应到2PC的执行阶段,如果上一个阶段都是收到YES的话,那么就发送doCommit命令去提交事务,反之则会发送abort命令去中断事务的执行。
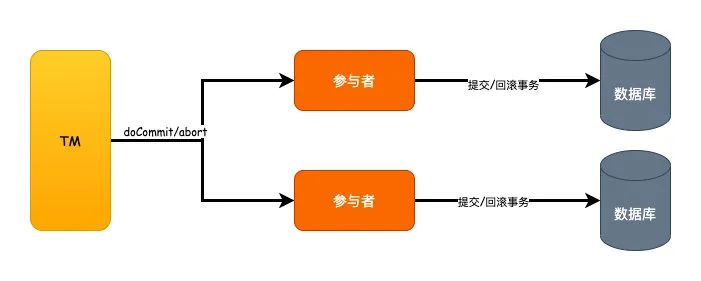
相比2PC的改进
对于2PC的同步阻塞的问题,我们可以看到因为3PC加入了参与者的超时机制,所以原来2PC的如果某个参与者故障导致的同步阻塞的问题时间缩短了,这是一个优化,但是并没有完全避免。
第二个单点故障的问题,同样因为超时机制的引入,一定程度上也算是优化了。
但是数据不一致的问题,这个始终没有得到解决。
举个栗子:
在PreCommit阶段,某个参与者发生脑裂,无法收到TM的请求,这时候其他参与者执行abort事务回滚,而脑裂的参与者超时之后继续提交事务,还是有可能发生数据不一致的问题。
那么,为什么要加入DoCommit这个阶段呢?就是为了引入超时机制,事先我们先确认数据库是否都可以执行事务,如果都OK,那么才会进入后面的步骤,所以既然都可以执行,那么超时之后说明发生了问题,就自动提交事务。
TCC
TCC的模式叫做Try、Confirm、Cancel,实际上也就是2PC的一个变种而已。
实现这个模式,一个事务的接口需要拆分成3个,也就是Try预占、Confirm确认提交、最后Cancel回滚。
对于TCC来说,实际生产我基本上就没看见过有人用,考虑到原因,首先是程序员的本身素质参差不齐,多个团队协作你很难去约束别人按照你的规则来实现,另外一点就是太过于复杂。
如果说有简单的应用的话,库存的应用或许可以算做是一个。
一般库存的操作,很多实现方案里面都会会在下单的时候先预占库存,下单成功之后再实际去扣减库存,最终如果发生了异常再回退。
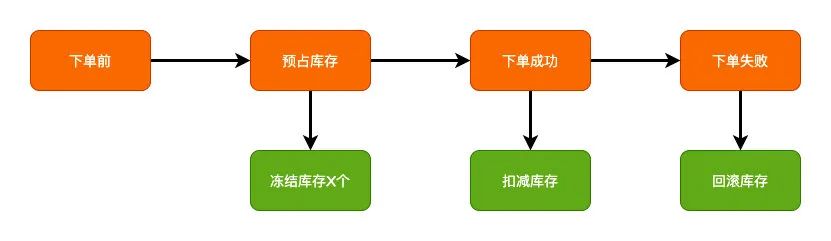
冻结、预占库存就是2PC的准备阶段,真正下单成功去扣减库存就是2PC的提交阶段,回滚就是某个发生异常的回滚操作,只不过在应用层面来实现了2PC的机制而已。
SAGA
Saga源于1987 年普林斯顿大学的 Hecto 和 Kenneth 发表的如何处理 long lived transaction(长活事务)论文。
主要思想就是将长事务拆分成多个本地短事务。
如果全部执行成功,就正常完成了,反之,则会按照相反的顺序依次调用补偿。
SAGA模式有两种恢复策略:
向前恢复,这个模式偏向于一定要成功的场景,失败则会进行重试 向后恢复,也就是发生异常的子事务依次回滚补偿
由于这个模式在国内基本没看见有谁用的,不在赘述。
消息队列
基于消息队列来实现最终一致性的方案,这个相比前面的我个人认为还稍微靠谱一点,那些都是理论啊,正常生产的实现很少看见应用。
基于消息队列的可能真正在应用的还稍微多一点。
一般来说有两种方式,基于本地消息表和依赖MQ本身的事务消息。
本地消息表的这个方案其实更复杂,实际上我也没看到过真正谁来用。这里我以RocketMQ的事务消息来举例,这个方式相比本地消息表则更完全依赖MQ本身的特性做了解耦,释放了业务开发的复杂工作量。
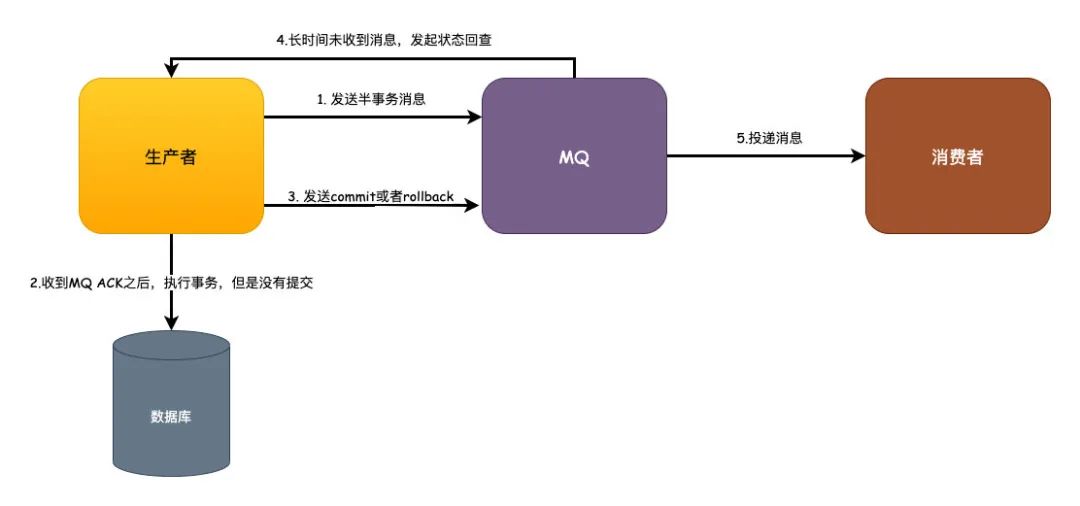
业务发起方,调用远程接口,向MQ发送一条半事务消息,MQ收到消息之后会返回给生产者一个ACK 生产者收到ACK之后,去执行事务,但是事务还没有提交。 生产者会根据事务的执行结果来决定发送commit提交或者rollback回滚到MQ 这一点是发生异常的情况,比如生产者宕机或者其他异常导致MQ长时间没有收到commit或者rollback的消息,这时候MQ会发起状态回查。 MQ如果收到的是commit的话就会去投递消息,消费者正常消费消息即可。如果是rollback的话,则会在设置的固定时间期限内去删除消息。
这个方案基于MQ来保证消息事务的最终一致性,还算是一个比较合理的解决方案,只要保证MQ的可靠性就可以正常实施应用,业务消费方根据本身的消息重试达到最终一致性。
框架
以上说的都是理论和自己实现的方式,那么分布式事务就没有框架来解决我们的问题吗?
有,其实还不少,但是没有能扛旗者出现,要说有,阿里的开源框架Seata还有阿里云的GTS。
GTS(Global Transaction Service 全局事务服务)是阿里云的中间件产品,只要你用阿里云,付钱就可以用GTS。
Seata(Simple Extensible Autonomous Transaction Architecture)则是开源的分布式事务框架,提供了对TCC、XA、Saga以及AT模式的支持。
那么,GTS和Seata有什么关系呢?
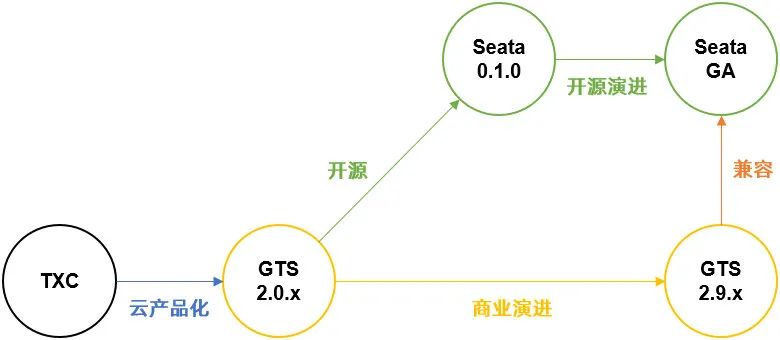
实际上最开始的时候他们都是基于阿里内部的TXC(Taobao Transaction Constructor)分布式中间件产品,然后TXC经过改造上了阿里云就叫做GTS。
之后阿里的中间件团队基于TXC和GTS做出了开源的Seata,其中AT(Automatic Transaction)模式就是GTS原创的方案。
至于现在的版本,可以大致认为他们就是一样的就行了,到2020年,GTS已经全面兼容了Seata的 GA 版本。
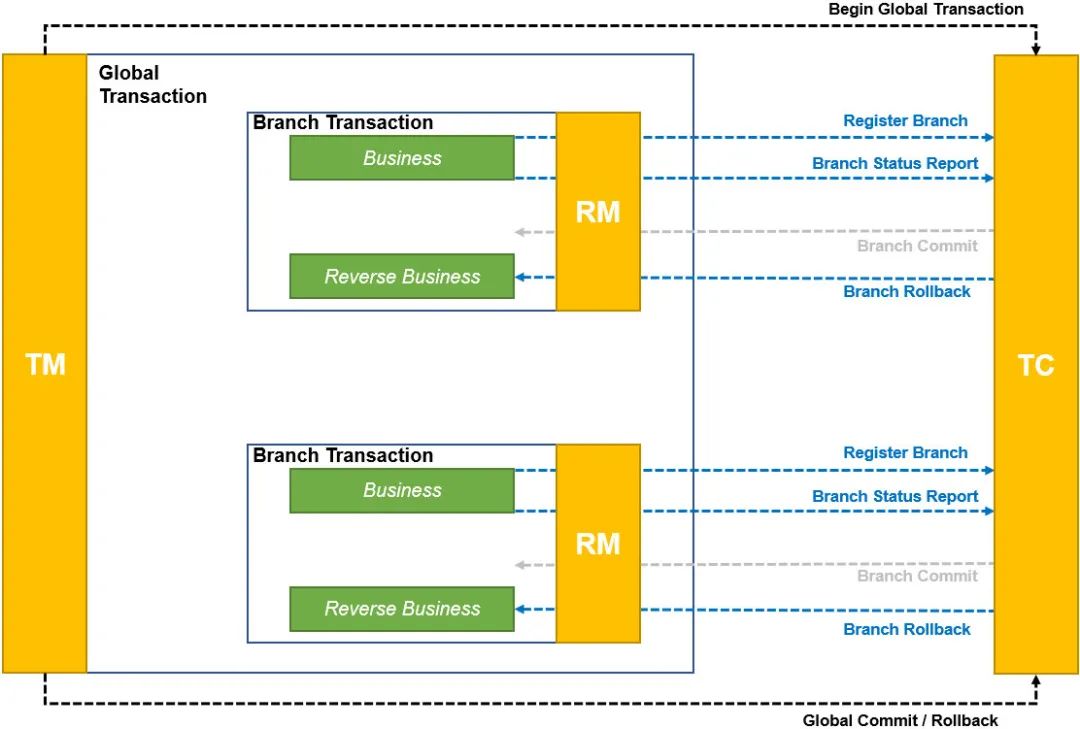
整个GTS或者Seata包含以下几个核心组件:
Transaction Coordinator(TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。 Transaction Manager(TM):控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。 Resource Manager(RM):控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
无论对于TCC还是原创的AT模式的支持,整个分布式事务的原理其实相对来说还是比较容易理解。
事务开启时,TM向TC注册全局事务,并且获得全局事务XID 这时候多个微服务的接口发生调用,XID就会传播到各个微服务中,每个微服务执行事务也会向TC注册分支事务。 之后TM就可以管理针对每个XID的事务全局提交和回滚,RM完成分支的提交或者回滚。
AT模式
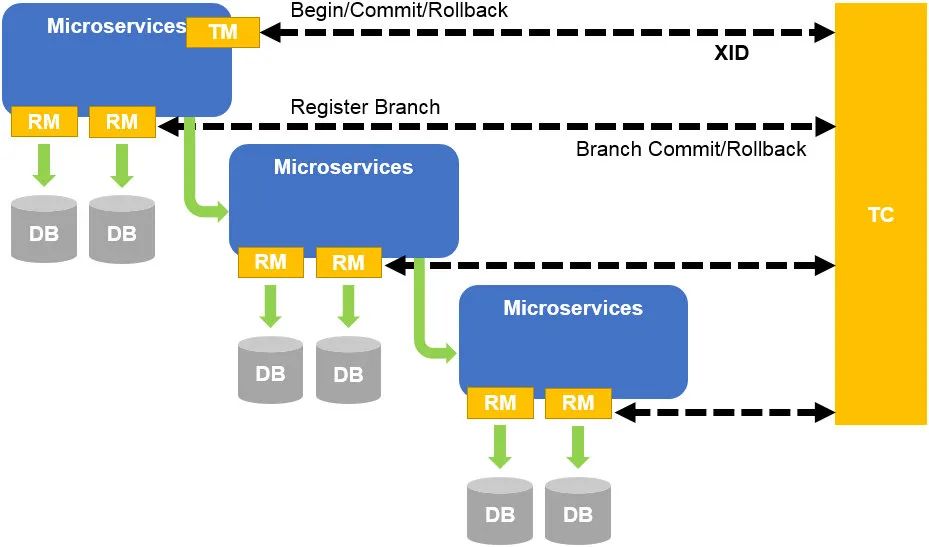
原创的AT模式相比起TCC的方案来说,无需自己实现多个接口,通过代理数据源的形式生成更新前后的UNDO_LOG,依靠UNDO_LOG来实现回滚的操作。
执行的流程如下:
TM向TC注册全局事务,获得XID RM则会去代理JDBC数据源,生成镜像的SQL,形成UNDO_LOG,然后向TC注册分支事务,把数据更新和UNDO_LOG在本地事务中一起提交 TC如果收到commit请求,则会异步去删除对应分支的UNDO_LOG,如果是rollback,就去查询对应分支的UNDO_LOG,通过UNDO_LOG来执行回滚
TCC模式
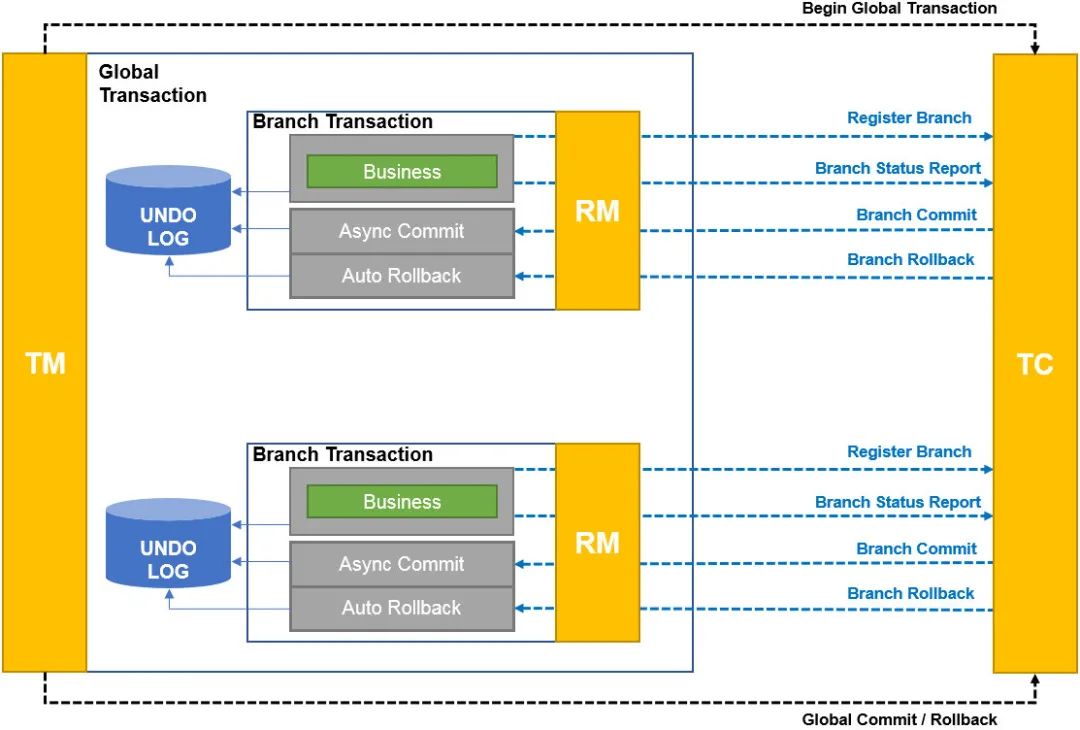
相比AT模式代理JDBC数据源生成UNDO_LOG来生成逆向SQL回滚的方式,TCC就更简单一点了。
TM向TC注册全局事务,获得XID RM向TC注册分支事务,然后执行Try方法,同时上报Try方法执行情况 然后如果收到TC的commit请求就执行Confirm方法,收到rollback则执行Cancel
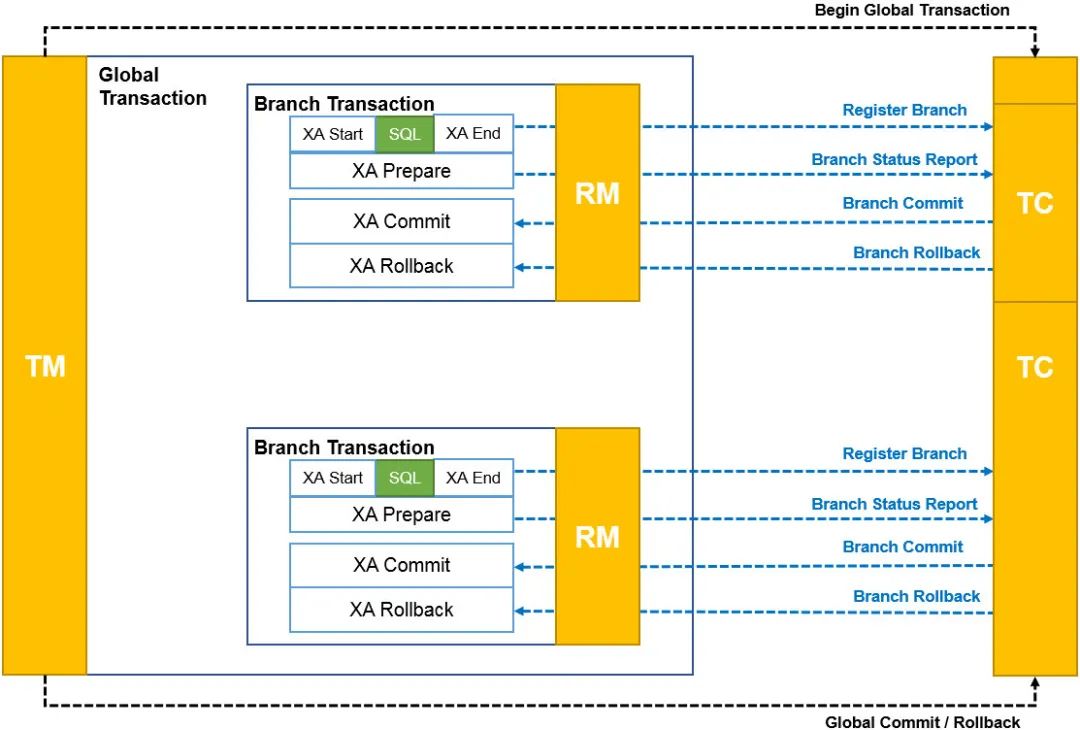
XA模式
TM向TC注册全局事务,获得XID RM向TC注册分支事务,XA Start,执行SQL,XA END,XA Prepare,然后上报分支执行情况 然后如果收到TC的commit请求就执行Confirm方法,收到rollback则执行Cancel
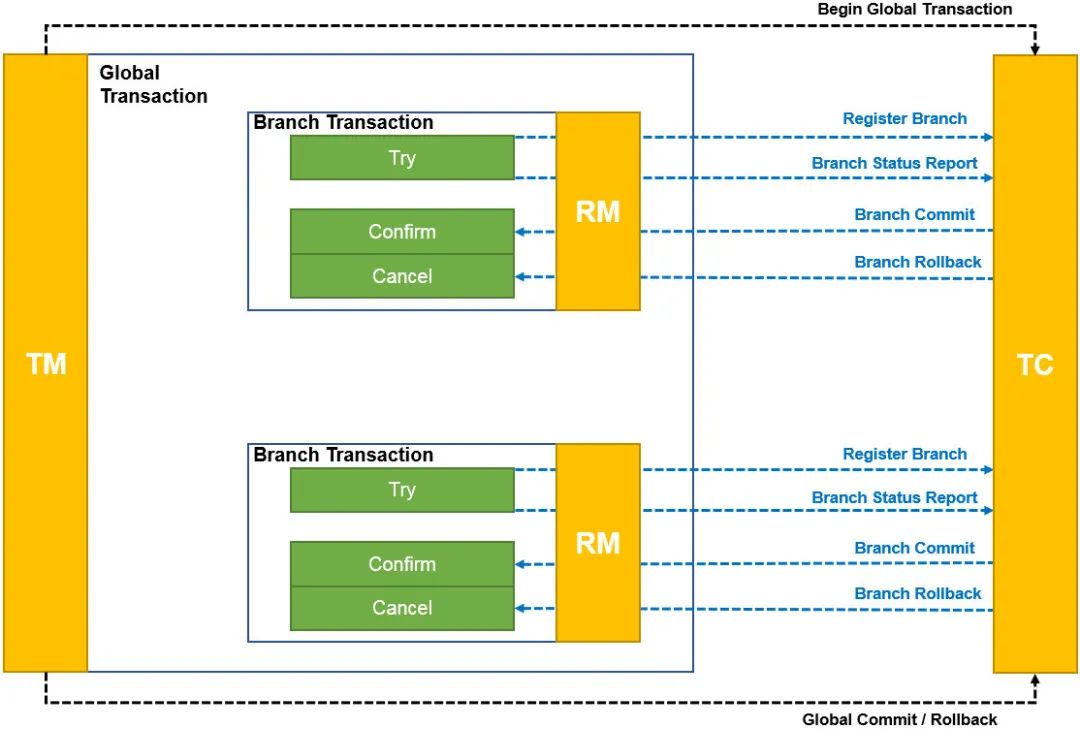
SAGA模式
TM向TC注册全局事务,获得XID RM向TC注册分支事务,然后执行业务方法,并且上报分支执行情况 RM收到分支回滚,执行对应的业务回滚方法
总结
这里从事务的ACID开始,向大家先说了XA是分布式事务处理的规范,之后谈到2PC和3PC,2PC有同步阻塞、单点故障和数据不一致的问题,3PC在一定程度上解决了同步阻塞和单点故障的问题,但是还是没有完全解决数据不一致的问题。
之后说到TCC、SAGA、消息队列的最终一致性的方案,TCC由于实现过于麻烦和复杂,业务很少应用,SAGA了解即可,国内也很少有应用到的,消息队列提供了解耦的实现方式,对于中小公司来说可能是较为低成本的实现方式。
最后再说目前国内的实现框架,云端阿里云的GTS兼容Seata,非云端使用Seata,它提供了XA、TCC、AT、SAGA的解决方案,可以说是目前的主流选择。
往期精选
围观
热文
热文
热文
长按二维码关注我
有趣的灵魂在等你
喜欢分享的程序员