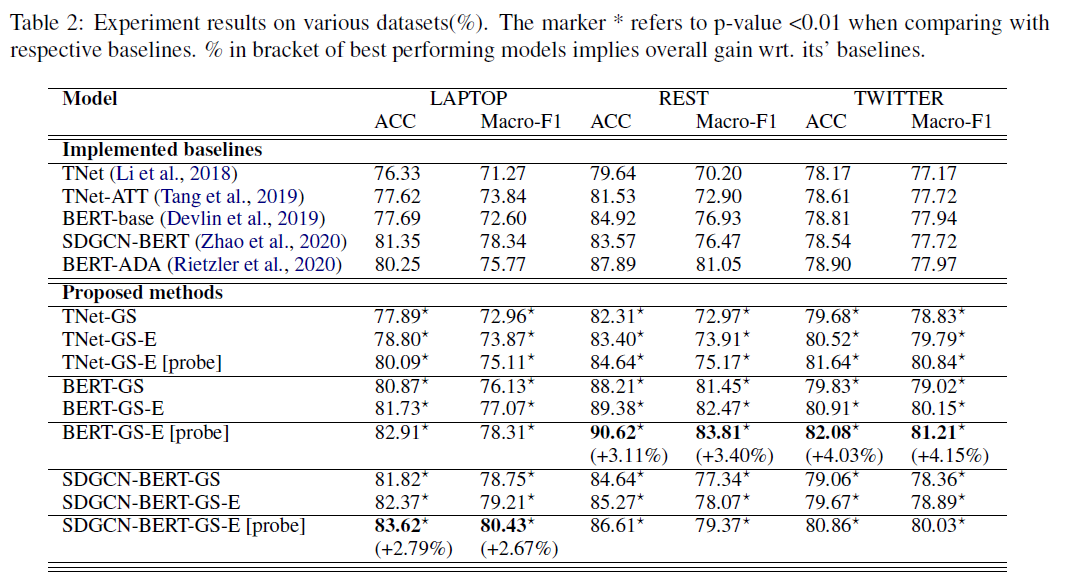
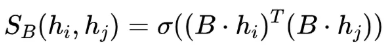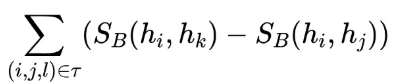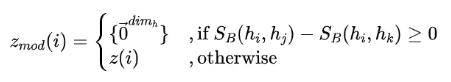NLP的研究者们一直都在尝试,怎么样让模型像人类一样,学会“知识”。而最直观的想法莫过于将人类已经总结出来供机器解读的“知识体系”,及其嵌入表示作为额外的特征添加到NLP模型之中。至少,从直觉上看,将知识融入到模型之中,可以让模型直接“看到”知识体系所带来的“言外之意”,从而与模型本身的统计共现特征形成互补,以补足训练样本中部分知识过于稀疏的问题。比如某一实体A在训练样本中频次很低,则可以用与它相似,且频次较高的实体B的特征来补充A,或者只是样本中的表达比较稀疏,则使用知识体系中的另一种更加常用的表达来补充(例如:OSX vs MacOS,歌神 vs 张学友),从而弥补A的特征过于稀疏的问题;或者可以使用A所在的归类体系中共享的特征来补充A的特征。 然而,模型需要什么样的知识,要以什么方式将知识整合到模型之中,一直是存有争议的问题。例如早几年很多工作尝试,使用知识图谱表示,将实体关系融合到模型中,在一些任务上取得了成效,但其最大的限制之一,则是消歧始终难以做到很高的准确率,其原因在于,知识图谱所收录的绝大多数实体,信息都是稀疏的(SPO密度很低),它们甚至很难参与到实体链指环节之中,所以很多 KGs+NLP 的工作都是在有限的知识图谱内进行的,而难以扩展到广域的知识图谱中。 除知识图谱外,则也有将通用知识引入到模型之中的工作,例如近两年很多将中文的组词应用到 NER 的工作,将实体类别信息应用于关系抽取的工作等,甚至我们可以开更大的脑洞,直接利用预训练语言模型从海量语料中学习到的充分的共现知识,用以表示通用知识,将之应用到基于预训练语言模型的种种方法中。 下面我想要介绍的工作,则是使用大规模知识图谱增强模型,做 aspect-level 的情感识别任务,作者声称,自己的方法相对 baseline 分别有2.5%~4%的提升。 大规模知识图谱增强的 aspect-level 情感识别
论文标题: Scalable End-to-End Training of Knowledge Graph-Enhanced Aspect Embedding for Aspect Level Sentiment Analysis
论文地址: https://arxiv.org/abs/2108.11656
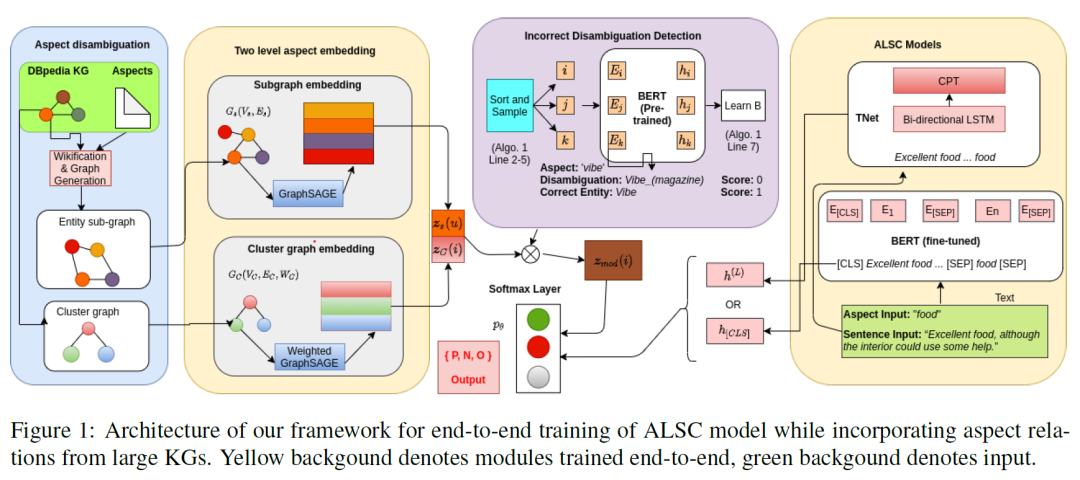
Aspect-level 的情感识别,即输入一段文本,询问该文本对某一个文本中提到的片段是什么样的情感倾向。例如句子:However, I can refute that OSX is "FAST". 中,询问句子中对 OSX 表达了什么样的情感。之前的工作很少将这个任务的分数刷到80分以上,本文作者则一鼓作气,将3个数据集的最终指标都刷到了80+。 Aspect-level 情感分类的难点在于,aspect 有可能是稀疏的,从而导致模型在“观察”文本的时候找不到重点,例如上面的例句,OSX 在对应的训练样本中仅仅出现了7次,非常的稀疏,而与之相似的 Microsoft Windows 则出现了37次。而使用训练样本中相对高频的 aspect 去补充相对低频的,又恰恰是知识增强的动机之一,所以利用知识图谱来增强这个任务,看上去相当的合适。 但是知识图谱增强又存在两个挑战:



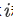 和
和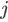 的相似函数为:
的相似函数为: