
什么是YARN?跟HBase和Spark比优势在哪?终于有人讲明白了

导读:HBase没有资源什么事情也做不了,Spark占用了资源却没有事情可做?YARN了解一下。

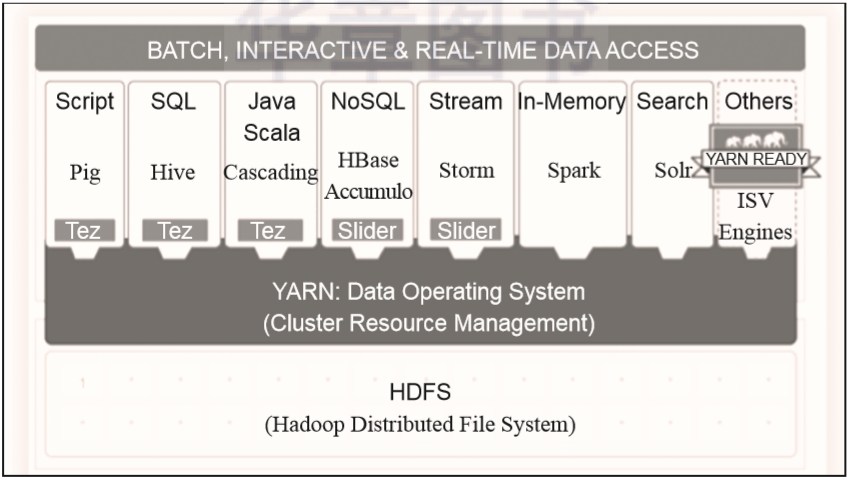

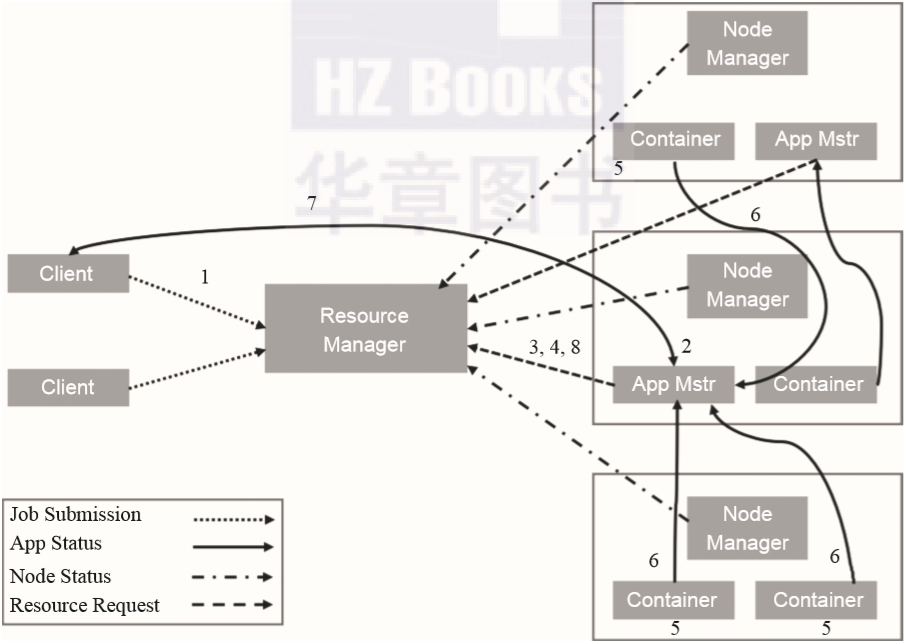
用户向YARN中提交应用程序。 ResourceManager为该应用程找到一个可用的NodeManager并分配第一个Container,然后在这个Container中启动应用程序的ApplicationMaster。 ApplicationMaster向ResourceManager进行注册,这样用户就可以通过ResourceManager查看应用程序的运行状态并对任务进行监控。 ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。 ApplicationMaster申请到资源后与对应的NodeManager通信,要求它启动Container并为任务设置好运行环境。 应用程序的任务开始在启动的Container中运行,各个任务向ApplicationMaster汇报自己的状态和进度,以便ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。 应用在运行的过程中,客户端通过轮询的方式主动与ApplicationMaster通信以获得应用的运行状态、执行进度等信息。 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。

评论