
什么是知识图谱?有哪些典型应用?终于有人讲明白了
导读:本文将详细阐述知识图谱的基本概念,包括知识图谱的背景、定义以及典型应用。
01 知识图谱背景
在给出知识图谱的定义之前,我们先分开讨论一下什么是知识,什么是图谱。
1. 什么是知识
首先看一下什么是知识。有读者可能会提出这样的问题,在大数据时代,人类拥有海量的数据,这是不是代表人类可以随时随地利用无穷无尽的知识呢?答案是否定的。
知识是人类在实践中认识客观世界(包括人类自身)的成果,它包括事实、信息、描述以及在教育和实践中获得的技能。知识是人类从各个途径中获得的经过提升、总结与凝炼的系统的认识。
因此,可以这样理解,知识是人类对信息进行处理之后的认识和理解,是对数据和信息的凝炼、总结后的成果。
让我们来看一下Rowley在2007年提出的DIKW体系[1],如图1-3所示,从数据、信息、知识到智慧,是一个不断凝炼的过程。
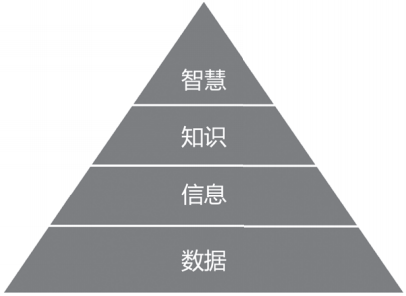
▲图1-3 DIKW体系
举一个简单的例子,226.1厘米,229厘米,都是客观存在的孤立的数据。此时,数据不具有任何意义,仅表达一个客观事实。而“姚明臂展226.1厘米”“姚明身高229厘米”是事实型的陈述,属于信息的范畴。
知识,则是对信息层面的抽象和归纳,把姚明的身高、臂展,及其他属性整合起来,就得到了对于姚明的一个认知,也可以进一步了解到姚明的身高是比普通人高的。对于最后的智慧层面,Zeleny提到的智慧是指知道为什么(Know-Why)[2],感兴趣的读者可以自行了解,本文暂不对此进行深入探讨。
2. 什么是图谱
那么什么是图谱?图谱的英文是Graph,直译过来就是“图”的意思。在图论(数学的一个研究分支)中,图表示一些事物(Object)与另一些事物之间相互连接的结构。
一张图通常由一些结点(Vertice或Node)和连接这些结点的边(Edge)组成。“图”这一名词是由詹姆斯·约瑟夫·西尔维斯特在1878年首次提出的[3]。图1-4是一个非常简单的图,它由6个结点和7条边组成。
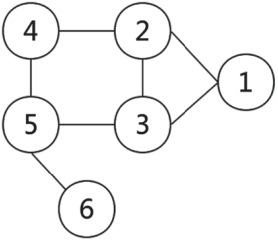
▲图1-4 由6个结点和7条边组成的图示例
从字面上看,知识图谱就是用图的形式将知识表示出来。图中的结点代表语义实体或概念,边代表结点间的各种语义关系。
我们再将姚明的一些基本信息,用计算机所能理解的语言表示出来,构建一个简单的知识图谱。比如,<姚明,国籍,中国>表示姚明的国籍是中国,其中“姚明”和“中国”是两个结点,而结点间的关系是“国籍”。
这是一种常用的基于符号的知识表示方式——资源描述框架(Resource Description Framework,RDF),它把知识表示为一个包含主语(Subject)、谓语(Predicate)和宾语(Object)的三元组<S,P,O>。
02 知识图谱的定义
上一节对知识图谱给出了一个具象的描述,即它是由结点和边组成的语义网络。那么该如何准确定义知识图谱呢?这里我们可以先回顾一下其概念的演化历程。
知识图谱概念的演化历程如图1-5所示。
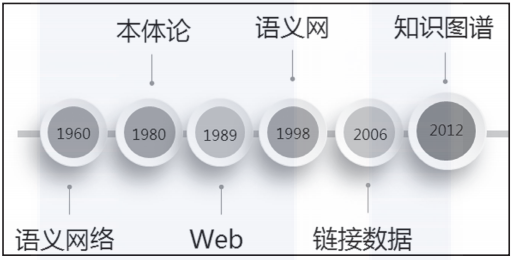
▲图1-5 知识图谱概念的演化历程
语义网络由剑桥语言研究所的Richard H. Richens提出,前文中已经简单介绍了语义网络的含义。它是一种基于图的数据结构,是一种知识表示的手段,可以很方便地将自然语言转化为图来表示和存储,并应用在自然语言处理问题上,例如机器翻译、问答等。
到了20世纪80年代,研究人员将哲学概念本体(Ontology)引入计算机领域,作为“概念和关系的形式化描述”, 后来,Ontology也被用于为知识图谱定义知识体系(Schema)。
而真正对知识图谱产生深远影响的是Web的诞生。Tim Berners-Lee在1989年发表的“Information Management: A Proposal”[4]中提出了Web的愿景, Web应该是一个以“链接”为中心的信息系统(Linked Information System),以图的方式相互关联。
Tim认为“以链接为中心“和“基于图的方式”,相比基于树的固定层次化组织方式更加有用,从而促成了万维网的诞生。我们可以这样理解,在Web中,每一个网页就是一个结点,网页中的超链接就是边。但其局限性是显而易见的,比如,超链接只能说明两个网页是相互关联的,而无法表达更多信息。
1994年,在第一届国际万维网大会上,Tim又指出,人们搜索的并不是页面,而是数据或事物本身,由于机器无法有效地从网页中识别语义信息,因此仅仅建立Web页面之间的链接是不够的,还应该构建对象、概念、事物或数据之间的链接。
随后在1998年,Tim正式提出语义网(Semantic Web)的概念。语义网是一种数据互连的语义网络,它仍然基于图和链接的组织方式,但图中的结点不再是网页,而是实体。
通过为全球信息网上的文档添加“元数据”(Meta Data),让计算机能够轻松理解网页中的语义信息,从而使整个互联网成为一个通用的信息交换媒介。我们可以将语义网理解为知识的互联网(Web of Knowledge)或者事物的互联网(Web of Thing)。
2006年,Tim又提出了链接数据(Linked Data)的概念,进一步强调了数据之间的链接,而不仅仅是文本的数据化。后文还会介绍链接开放数据(Linked Open Data,LOD)项目,它也是为了实现Tim有关链接数据作为语义网的一种实现的设想。
随后在2012年,Google基于语义网中的一些理念进行了商业化实现,其提出的知识图谱概念也沿用至今。
可以看到,知识图谱的概念是和Web、自然语言处理(NLP)、知识表示(KR)、数据库(DB)、人工智能(AI)等密切相关的。所以我们可以从以下几个角度去了解知识图谱。
从Web的角度来看,像建立文本之间的超链接一样,构建知识图谱需要建立数据之间的语义链接,并支持语义搜索,这样就改变了以前的信息检索方式,可以以更适合人类理解的语言来进行检索,并以图形化的形式呈现。
从NLP的角度来看,构建知识图谱需要了解如何从非结构化的文本中抽取语义和结构化数据。
从KR的角度来看,构建知识图谱需要了解如何利用计算机符号来表示和处理知识。
从AI的角度来看,构建知识图谱需要了解如何利用知识库来辅助理解人类语言,包括机器翻译问题的解决。
从DB的角度来看,构建知识图谱需要了解使用何种方式来存储知识。
由此看来,知识图谱技术是一个系统工程,需要综合利用各方面技术。国内的一些知名学者也给出了关于知识图谱的定义。这里简单列举了几个。
电子科技大学的刘峤教授给出的定义是:
知识图谱,是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系,其基本组成单位是“实体–关系–实体”三元组,以及实体及其相关属性–值对,实体之间通过关系相互联结,构成网状的知识结构[5]。
清华大学的李涓子教授给出的定义是:
知识图谱以结构化的方式描述客观世界中概念、实体及其关系,将互联网的信息表示成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力[6]。
浙江大学的陈华钧教授对知识图谱的理解是:
知识图谱旨在建模、识别、发现和推断事物、概念之间的复杂关系,是事物关系的可计算模型,已经被广泛应用于搜索引擎、智能问答、语言理解、视觉场景理解、决策分析等领域。
东南大学的漆桂林教授给出的定义是:
知识图谱本质上是一种叫作语义网络的知识库,即一个具有有向图结构的知识库,其中图的结点代表实体或者概念,而图的边代表实体/概念之间的各种语义关系[7]。
当前,无论是学术界还是工业界,对知识图谱还没有一个唯一的定义,本文的重点也不在于给出理论上的精确定义,而是尝试从工程的角度,讲解如何构建有效的知识图谱。有一些常见概念,这里列举如下。
实体:对应一个语义本体,例如“姚明”“中国”等。
属性:描述一类实体的特性(例如“身高”:姚明的身高是229厘米)。
关系:对应语义本体之间的关系,将实体连接起来(例如“国籍”:姚明的国籍是中国)。
有些学者也将属性定义为关系,属于属性关系的一种。但本文将属性和关系作为两种不同的概念区别对待。
03 知识图谱的典型应用
我们在前文中已经接触到了知识图谱对搜索引擎的成功应用。知识图谱为搜索提供了丰富的结构化结果,体现了信息和知识的关联,可以通过搜索直接得到答案。
除了通用搜索引擎之外,在一些特定领域中,知识图谱也发挥着重要作用,例如同花顺公司的问财系统、文因互联的文因企业搜索等。
1. 医疗领域
在医疗领域,为了降低发现新药的难度,Open Phacts联盟构建了一个发现平台,通过整合来自各种数据源的药理学数据,构建知识图谱,来支持药理学研究和药物发现。
IBM Waston通过构建医疗信息系统,以及一整套的问答和搜索框架,以肿瘤诊断为核心,成功应用于包括慢病、医疗影像、体外检测在内的九大医疗领域。
其第一步商业化运作是打造了一个肿瘤解决方案(Waston for Oncology),通过输入纪念斯隆·凯特琳癌症中心的数千份病例、1500万页医学文献,可以为不同的肿瘤病人提供个性化治疗方案,连同医学证据一起推荐给医生。
2. 金融投资领域
在投资研究领域,成立于2010年的AlphaSense公司打造了一款新的金融知识引擎。
与传统的金融信息数据平台不同,这款知识引擎并不仅仅局限在金融数据的整合和信息平台的范围,而是通过构建知识图谱,加上自然语言处理和语义搜索引擎,让用户可以更方便地获取各种素材并加工再使用。
另外一款非常具有代表性的金融知识引擎是Kensho。它通过从各种数据源搜集信息,构建金融知识图谱,并关注事件和事件之间的依赖,以及对结果的关联和推理,从而可为用户提供自动化语义分析、根据特定行情判断走势等功能。
3. 政府管理和安全领域
在政府管理和安全领域,一个具有代表性的案例是Palantir,因通过大规模知识图谱协助抓住了本·拉登而声名大噪。
其核心技术是整理、分析不同来源的结构化和非结构化数据,为相关人员提供决策支持。例如在军事情报分析系统中,将多源异构信息进行整合,如电子表格、电话、文档、传感器数据、动态视频等,可以对人员、装备、事件进行全方位实时的监控分析,使调度人员第一时间掌握战场态势,并做出预判。
除了协助抓住本·拉登,Palantir的另外一项赫赫有名的成就是协助追回了前纳斯达克主席麦道夫金融欺诈案的数十亿美金。
4. 电商领域
在电商领域,阿里巴巴生态积聚了海量的商品和交易数据,它以商品、产品、品牌和条码为核心,构建了百亿级别的商品知识图谱,可以广泛应用于搜索、导购、平台治理、智能问答等业务,同时保持每天千万级别的恶意攻击拦截量,极大提升了消费者的购物体验。
5. 聊天机器人领域
在聊天机器人领域,具有问答功能的产品,例如Siri、微软小冰、公子小白、琥珀·虚颜、天猫精灵、小米音箱,背后均有大规模知识图谱的支持。
例如在琥珀·虚颜中,除了有通用百科知识图谱——“七律”的支持,还有子领域,例如动漫知识图谱、美食知识图谱、星座知识图谱的支持。图1-13给出了公子小白在多类别知识图谱融合后的一个问答对话示例。

▲图1-13 公子小白对话示例
(欢迎大家加入数据工匠知识星球获取更多资讯。)

扫描二维码关注我们

我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工匠俱乐部
微信号:zgsjgjjlb
专注数据治理,推动大数据发展。