
神奇的 SQL 之性能优化,让 SQL 飞起来

写在前面
下文将尽量介绍一些不依赖具体数据库实现,使 SQL 执行速度更快、消耗内存更少的优化技巧,只需调整 SQL 语句就能实现的通用的优化 Tips

说句很重要的心里话:祝大家在 2021 年,健康好运,平安幸福!

环境准备
DROP TABLE IF EXISTS tbl_customer;
CREATE TABLE tbl_customer (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
name VARCHAR(50) NOT NULL COMMENT '顾客姓名',
age TINYINT(3) NOT NULL COMMENT '年龄',
id_card CHAR(18) NOT NULL COMMENT '身份证',
phone_number CHAR(11) NOT NULL COMMENT '手机号码',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='顾客表';
INSERT INTO tbl_customer(name, age,id_card,phone_number) VALUES
('张三',19,'430682198109129210','15174480311'),
('李四',21,'430682198109129211','15174480312'),
('王五',22,'430682198109129212','15174480313'),
('六一',23,'430682198109129213','15174480314'),
('六二',25,'430682198109129214','15174480315'),
('六三',27,'430682198109129215','15174480316'),
('六四',29,'430682198109129216','15174480317');
DROP TABLE IF EXISTS tbl_recharge_record;
CREATE TABLE tbl_recharge_record (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
customer_id INT(11) NOT NULL COMMENT '顾客ID',
recharge_type TINYINT(2) NOT NULL COMMENT '充值方式 1:支付宝, 2:微信,3:QQ,4:京东,5:银联,6:信用卡,7:其他',
recharge_amount DECIMAL(15,2) NOT NULL COMMENT '充值金额, 单位元',
recharge_time DATETIME NOT NULL COMMENT '充值时间',
remark VARCHAR(500) NOT NULL DEFAULT 'remark' COMMENT '备注',
PRIMARY KEY (id),
KEY idx_c_id(customer_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='顾客充值记录表';
INSERT INTO tbl_recharge_record(customer_id,recharge_type,recharge_amount,recharge_time) VALUES
(1,1,10000,NOW()),
(2,2,20000,NOW()),
(1,2,10000,NOW()),
(1,3,10000,NOW()),
(2,7,20000,NOW()),
(3,3,15000,NOW()),
(4,1,10000,NOW()),
(5,1,10000,NOW()),
(6,1,10000,NOW()),
(7,1,10000,NOW()),
(7,1,10000,NOW()),
(6,1,10000,NOW()),
(5,1,10000,NOW()),
(4,1,10000,NOW()),
(3,1,10000,NOW()),
(2,1,10000,NOW()),
(1,1,10000,NOW()),
(2,1,10000,NOW()),
(3,1,10000,NOW()),
(2,1,10000,NOW()),
(3,1,10000,NOW()),
(4,1,10000,NOW()),
(2,1,10000,NOW()),
(2,1,10000,NOW()),
(1,1,10000,NOW());
神奇的 SQL 之 MySQL 执行计划 → EXPLAIN,让我们了解 SQL 的执行过程! cnblogs.com/youzhibing/p/11909681.html
使用高效的查询
使用 EXISTS 代替 IN
IN 使用起来确实简单,也非常好理解;我们来看下它的执行计划

我们再来看看 EXISTS 的执行计划:

通常来讲,EXISTS 比 IN 更快的原因有两个
1、如果连接列(customer_id)上建立了索引,那么查询 tbl_recharge_record 时可以通过索引查询,而不是全表查询
其实有很多数据库也尝试着改善了 IN 的性能
Oracle 数据库中,如果我们在有索引的列上使用 IN, 也会先扫描索引
PostgreSQL 从版 本 7.4 起也改善了使用子查询作为 IN 谓词参数时的查询速度
神奇的 SQL 之谓词 → 难理解的 EXISTS
cnblogs.com/youzhibing/p/11385136.html
使用连接代替 IN
回到问题:查询有充值记录的顾客信息,如果用连接来实现,SQL 改如何写?

避免排序
但是,除了 ORDER BY 显示的排序,数据库内部还有很多运算在暗中进行排序;会进行排序的代表性的运算有下面这些

灵活使用集合运算符的 ALL 可选项
默认情况下,这些运算符会为了排除掉重复数据而进行排序
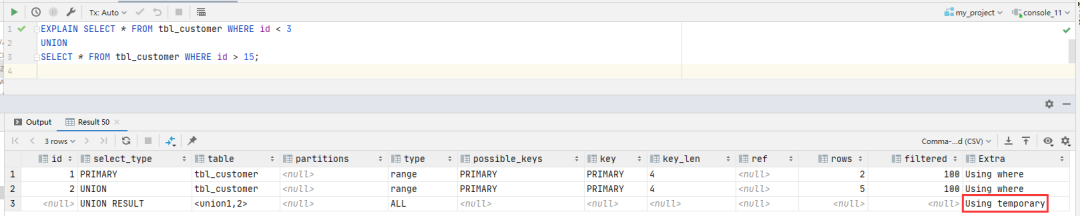
如果我们不在乎结果中是否有重复数据,或者事先知道不会有重复数据,可以使用 UNION ALL 代替 UNION

加上 ALL 可选项是一个非常有效的优化手段,但各个数据库对它的实现情况却是参差不齐,如下图所示

使用 EXISTS 代替 DISTINCT
会发现执行计划中有个 Using temporary ,表示用到了排序运算


在极值函数中使用索引
SQL 语言里有两个极值函数:MAX 和 MIN ,使用这两个函数时都会进行排序
例如:SELECT MAX(recharge_amount) FROM tbl_recharge_record
但是如果参数字段上建有索引,则只需要扫描索引,不需要扫描整张表
例如:SELECT MAX(customer_id) FROM tbl_recharge_record;
减少排序的数据量
有效利用索引
在 GROUP BY 子句和 ORDER BY 子句中使用索引
使用索引
减少临时表
但是,频繁使用临时表会带来两个问题
1、临时表相当于原表数据的一份备份,会耗费内存资源
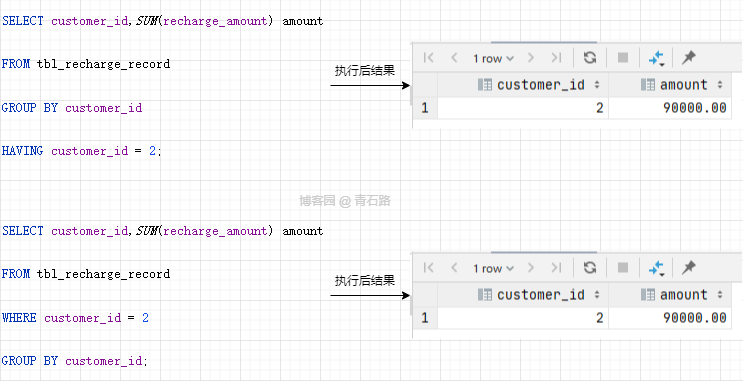
灵活使用 HAVING 子句
但是如果对 HAVING 不熟,我们往往找出替代它的方式来实现,就像这样

然而,对聚合结果指定筛选条件时不需要专门生成中间表,像下面这样使用 HAVING 子句就可以

需要对多个字段使用 IN 谓词时,将它们汇总到一处
我们来看一个示例,多个字段使用 IN 谓词
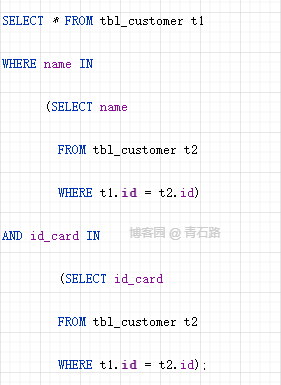
这段代码中用到了两个子查询,我们可以进行列汇总优化,把逻辑写在一起

还可以进一步简化,在 IN 中写多个字段的组合

先进行连接再进行聚合
合理地使用视图
特别是视图的定义语句中包含以下运算的时候,SQL 会非常低效,执行速度也会变得非常慢

总结
小结下文中的 Tips
1、参数是子查询时,使用 EXISTS 或者 JOIN 代替 IN
2、在 SQL 中,很多运算都会暗中进行排序,尽量规避这些运算
3、SQL 的书写,尽量往索引上靠,避免用不上索引的情况
参考
来源:cnblogs.com/youzhibing/p/11909821.html
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
