
无卷积骨干网络:金字塔Transformer,提升目标检测/分割等任务精度(附源代码)
点击上方“小白学视觉”,选择加"星标"或“置顶”


背景
在今天分享的工作中,研究者设计了一个新颖的Transformer模块,针对稠密预测任务的主干网络,利用Transformer架构设计进行了一次创新性的探索,将特征金字塔结构与Transformer进行了一次融合,使其可以更好的输出多尺度特征,进而更方便与其他下游任务相结合。
前言
尽管卷积神经网络 (CNN) 在计算机视觉方面取得了巨大成功,但今天分享的这项工作研究了一种更简单、无卷积的主干网络,可用于许多密集预测任务。
目标检测

语义分割

实例分割
与最近提出的专为图像分类设计的Vision Transformer(ViT)不同,研究者引入了Pyramid Vision Transformer(PVT),它克服了将Transformer移植到各种密集预测任务的困难。与当前的技术状态相比,PVT 有几个优点:
与通常产生低分辨率输出并导致高计算和内存成本的ViT不同,PVT不仅可以在图像的密集分区上进行训练以获得对密集预测很重要的高输出分辨率,而且还使用渐进式收缩金字塔以减少大型特征图的计算;
PVT继承了CNN和Transformer的优点,使其成为各种视觉任务的统一主干,无需卷积,可以直接替代CNN主干;
通过大量实验验证了PVT,表明它提高了许多下游任务的性能,包括对象检测、实例和语义分割。
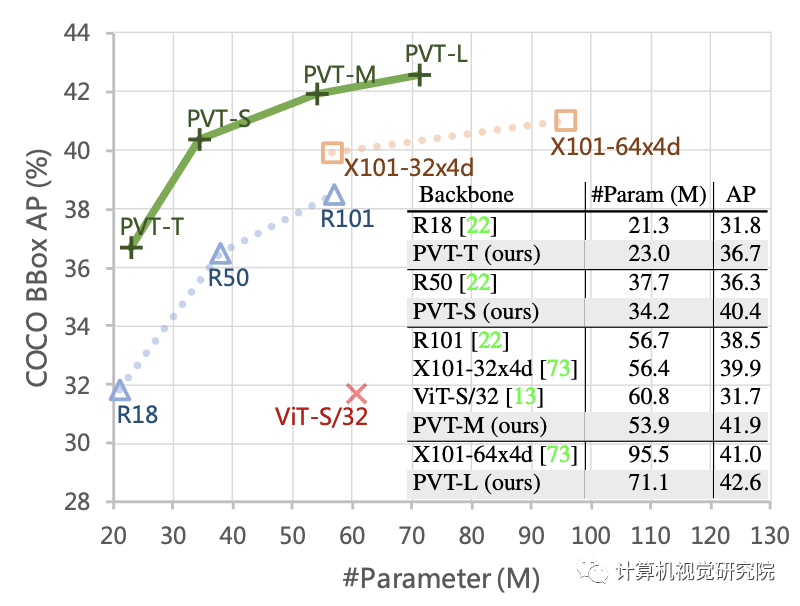
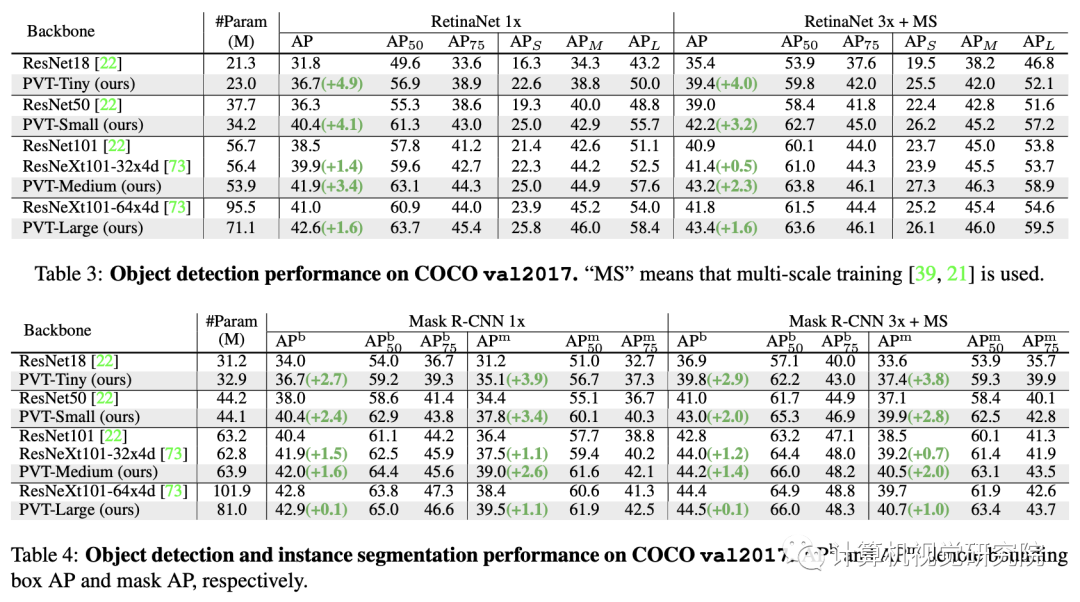
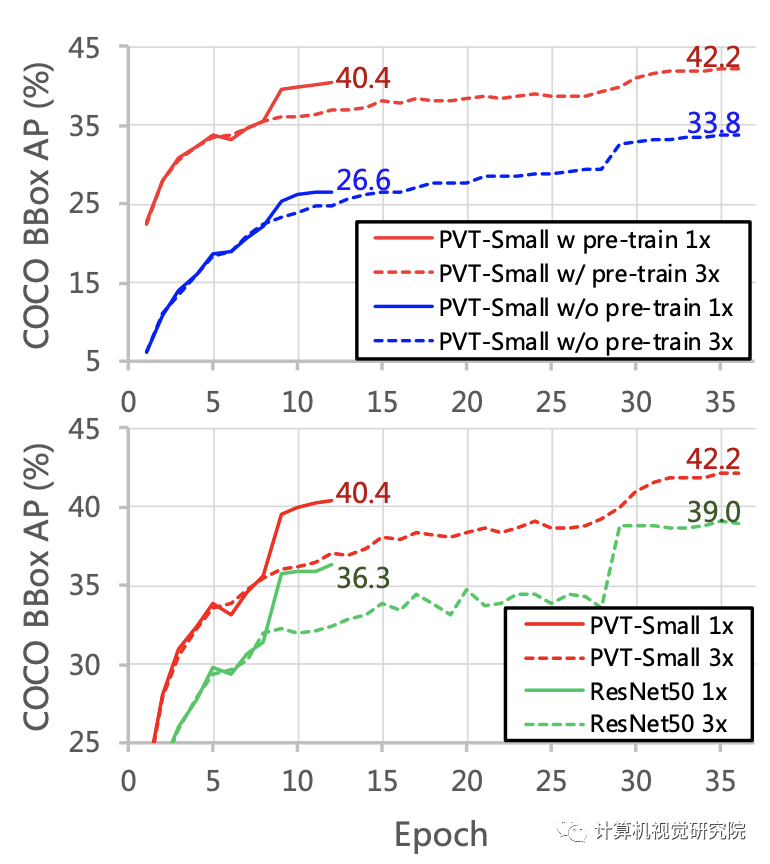
例如,在参数数量相当的情况下,PVT+RetinaNet在COCO数据集上实现了40.4 AP,超过ResNet50+RetinNet(36.3 AP)4.1个绝对AP(见下图)。研究者希望PVT可以作为像素级预测的替代和有用的主干,并促进未来的研究。
基础回顾
CNN Backbones
CNN是视觉识别中深度神经网络的主力军。标准CNN最初是在【Gradient-based learning applied to document recognition】中区分手写数字。该模型包含具有特定感受野的卷积核捕捉有利的视觉环境。为了提供平移等方差,卷积核的权重在整个图像空间中共享。最近,随着计算资源的快速发展(例如,GPU),堆叠卷积块成功在大规模图像分类数据集上训练(例如,ImageNet)已经成为可能。例如,GoogLeNet证明了包含多个内核路径的卷积算子可以实现非常有竞争力的性能。
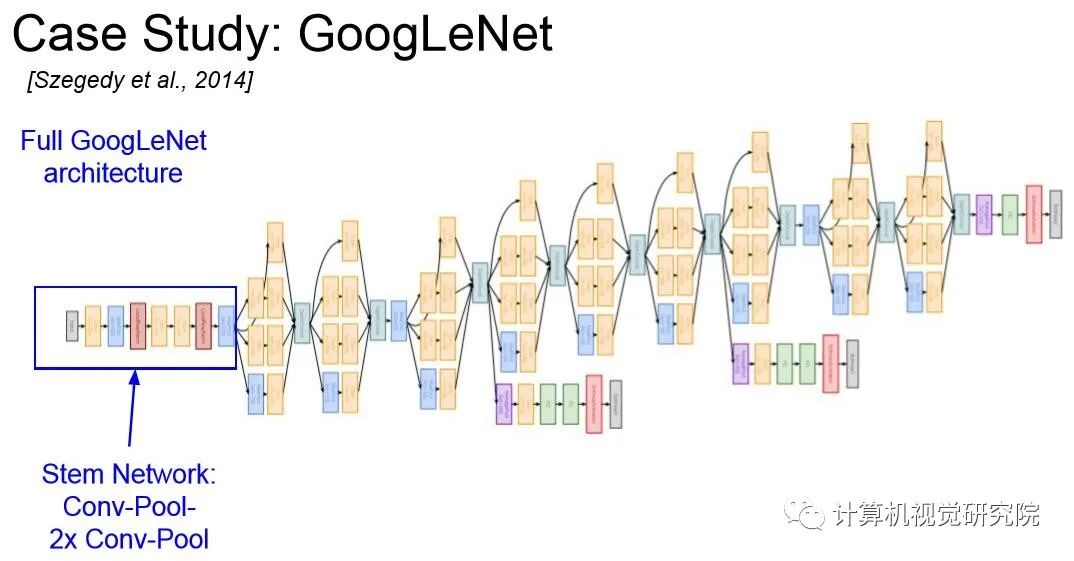
multi-path convolutional block的有效性在Inception系列、ResNeXt、DPN、MixNet和SKNet中得到了进一步验证。此外,ResNet将跳过连接引入到卷积块中,从而可以创建/训练非常深的网络并在计算机视觉领域获得令人印象深刻的结果。DenseNet引入了一个密集连接的拓扑,它将每个卷积块连接到所有先前的块。更多最新进展可以在最近的论文中找到。
新框架
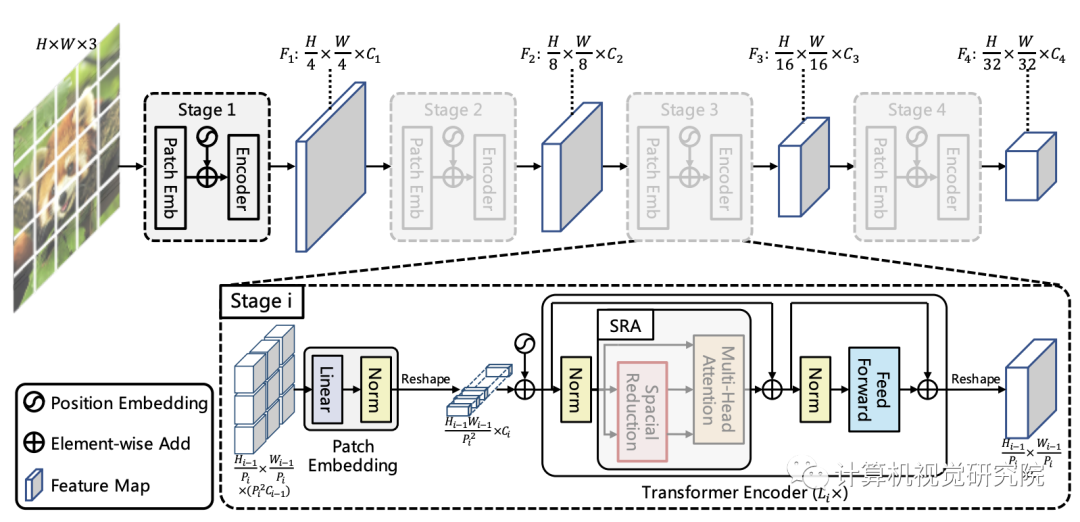
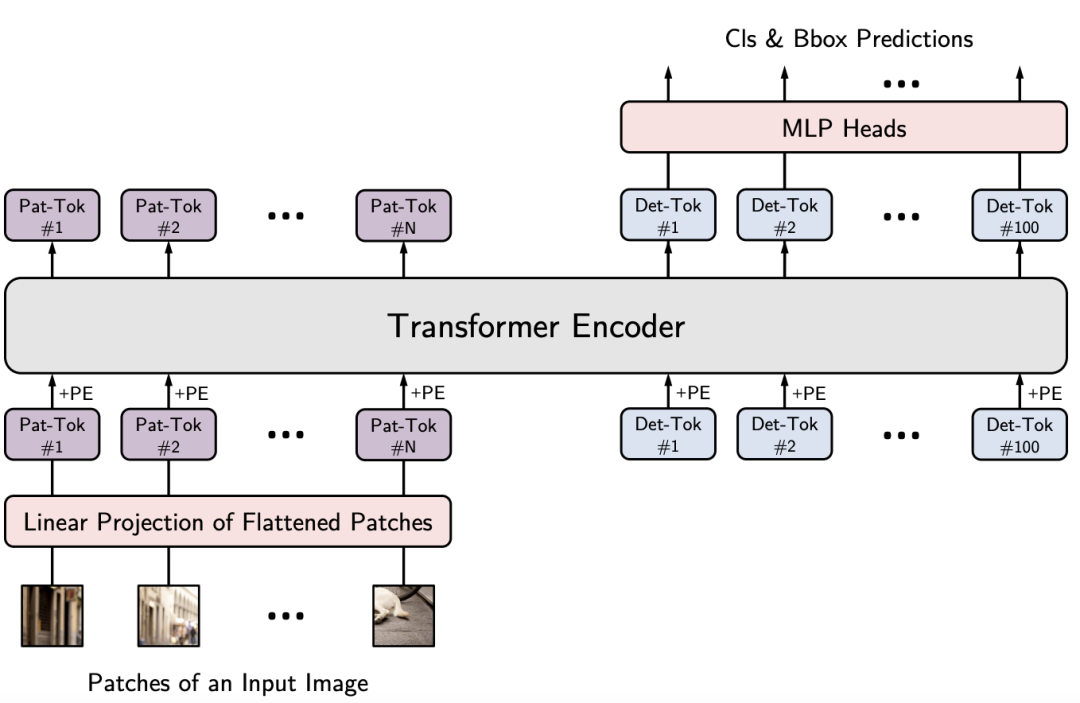
该框架旨在将金字塔结构嵌入到Transformer结构用于生成多尺度特征,并最终用于稠密预测任务。上图给出了所提出的PVT架构示意图,类似与CNN主干结构,PVT同样包含四个阶段用于生成不同尺度的特征,所有阶段具有相类似的结构:Patch Embedding+Transformer Encoder。
在第一个阶段,给定尺寸为H*W*3的输入图像,按照如下流程进行处理:
-
首先,将其划分为HW/4^2的块,每个块的大小为4*4*3;
-
然后,将展开后的块送入到线性投影,得到尺寸为HW/4^2 * C1的嵌入块;
-
其次,将前述嵌入块与位置嵌入信息送入到Transformer的Encoder,其输出将为reshap为H/4 * W/4 * C1。
采用类似的方式,以前一阶段的输出作为输入即可得到特征F2,F3和F4。基于特征金字塔F1、F2、F3、F4,所提方案可以轻易与大部分下游任务(如图像分类、目标检测、语义分割)进行集成。
Feature Pyramid for Transforme
不同于CNN采用stride卷积获得多尺度特征,PVT通过块嵌入按照progressive shrinking策略控制特征的尺度。
假设第i阶段的块尺寸为Pi,在每个阶段的开始,将输入特征均匀的拆分为Hi-1Wi-1/Pi个块,然后每个块展开并投影到Ci维度的嵌入信息,经过线性投影后,嵌入块的尺寸可以视作Hi-1/Pi * Wi-1/Pi * Ci。通过这种方式就可以灵活的调整每个阶段的特征尺寸,使其可以针对Transformer构建特征金字塔。
Transformer Encoder
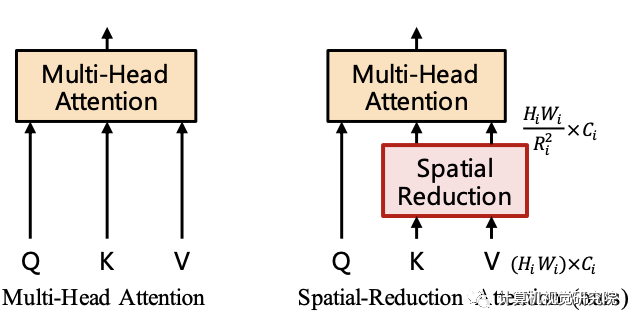
对于Transformer encoder的第i阶段,它具有Li个encoder层,每个encoder层由注意力层与MLP构成。由于所提方法需要处理高分辨率特征,所以提出了一种SRA(spatial-reduction attention)用于替换传统的MHA(multi-head-attention)。
类似于MHA,SRA同样从输入端接收到了Q、K、V作为输入,并输出精炼后特征。SRA与MHA的区别在于:SRA会降低K和V的空间尺度,见下图。
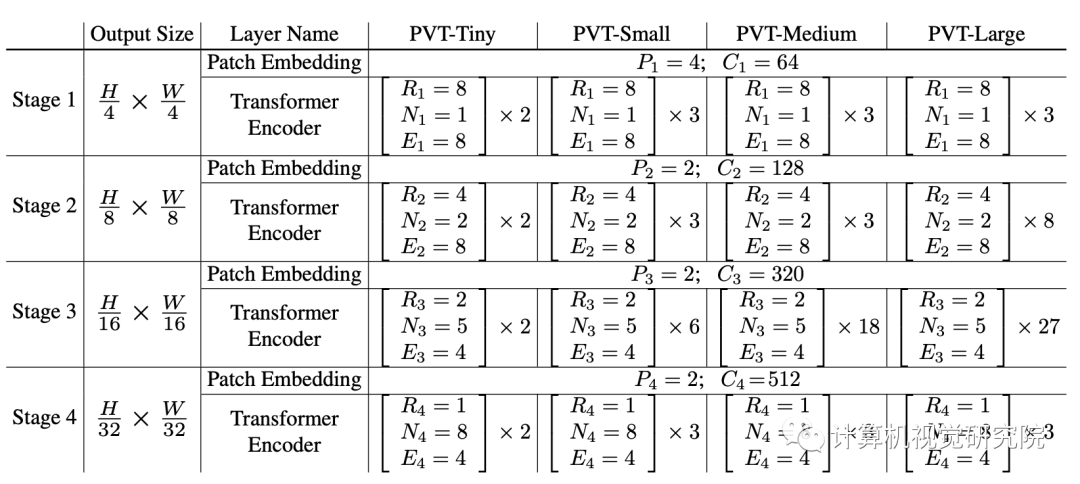
Detailed settings of PVT series
实验
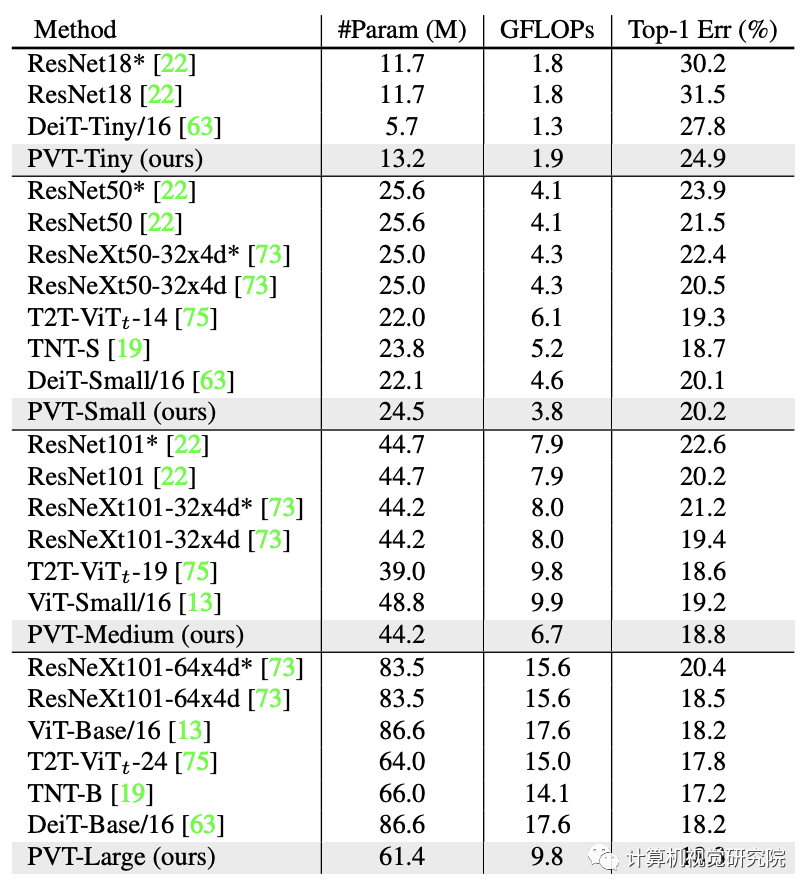
ImageNet数据集上的性能对比,结果见上表。从中可以看到:
-
相比CNN,在同等参数量与计算约束下,PVT-Small达到20.2%的误差率,优于ResNet50的21.5%;
-
相比其他Transformer(如ViT、DeiT),所提PVT以更少的计算量取得了相当的性能。
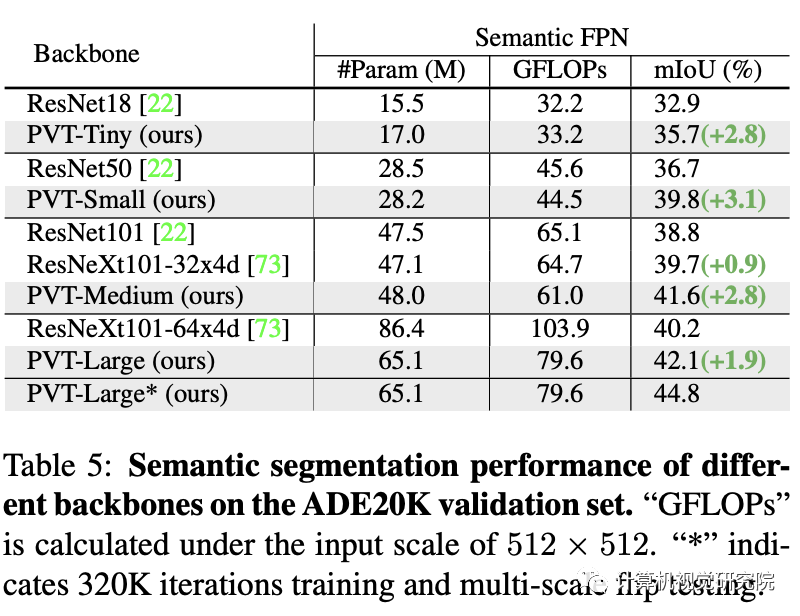
在语义分割中的性能对比,见上表。可以看到:不同参数配置下,PVT均可取得优于ResNet与ResNeXt的性能。这侧面说明:相比CNN,受益于全局注意力机制,PVT可以提取更好的特征用于语义分割。

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~