
YOLOS:通过目标检测重新思考Transformer(附源代码)
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

1

2

ViT-FRCNN是第一个使用预训练的ViT作为R-CNN目标检测器的主干。然而,这种设计无法摆脱对卷积神经网络(CNN)和强2D归纳偏差的依赖,因为ViT-FRCNN将ViT的输出序列重新解释为2D空间特征图,并依赖于区域池化操作(即RoIPool或RoIAlign)以及基于区域的CNN架构来解码ViT特征以实现目标级感知。受现代CNN设计的启发,最近的一些工作将金字塔特征层次结构和局部性引入Vision Transformer设计,这在很大程度上提高了包括目标检测在内的密集预测任务的性能。然而,这些架构是面向性能的。另一系列工作,DEtection TRansformer(DETR)系列,使用随机初始化的Transformer对CNN特征进行编码和解码,这并未揭示预训练Transformer在目标检测中的可迁移性。
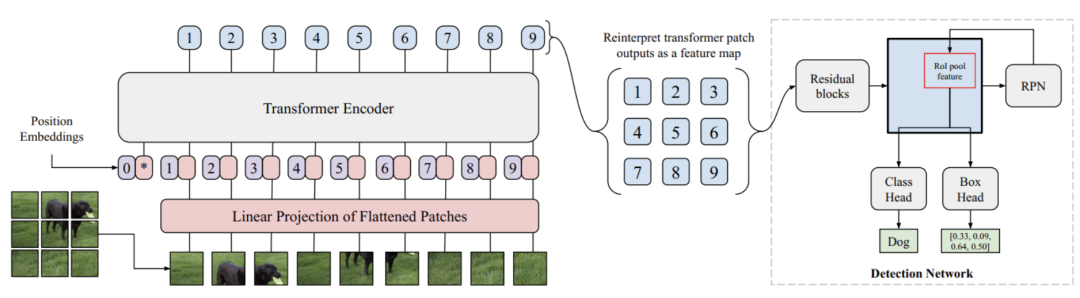
为了解决上面涉及的问题,有研究者展示了You Only Look at One Sequence (YOLOS),这是一系列基于规范ViT架构的目标检测模型,具有尽可能少的修改以及注入的归纳偏置。从ViT到YOLOS检测器的变化很简单:
YOLOS在ViT中删除[CLS]标记,并将一百个可学习的[DET]标记附加到输入序列以进行目标检测;
YOLOS将ViT中的图像分类损失替换为bipartite
matching loss,以遵循Carion等人【End-to-end object detection with transformers】的一套预测方式进行目标检测。这可以避免将ViT的输出序列重新解释为2D特征图,并防止在标签分配期间手动注入启发式和对象2D空间结构的先验知识。
3
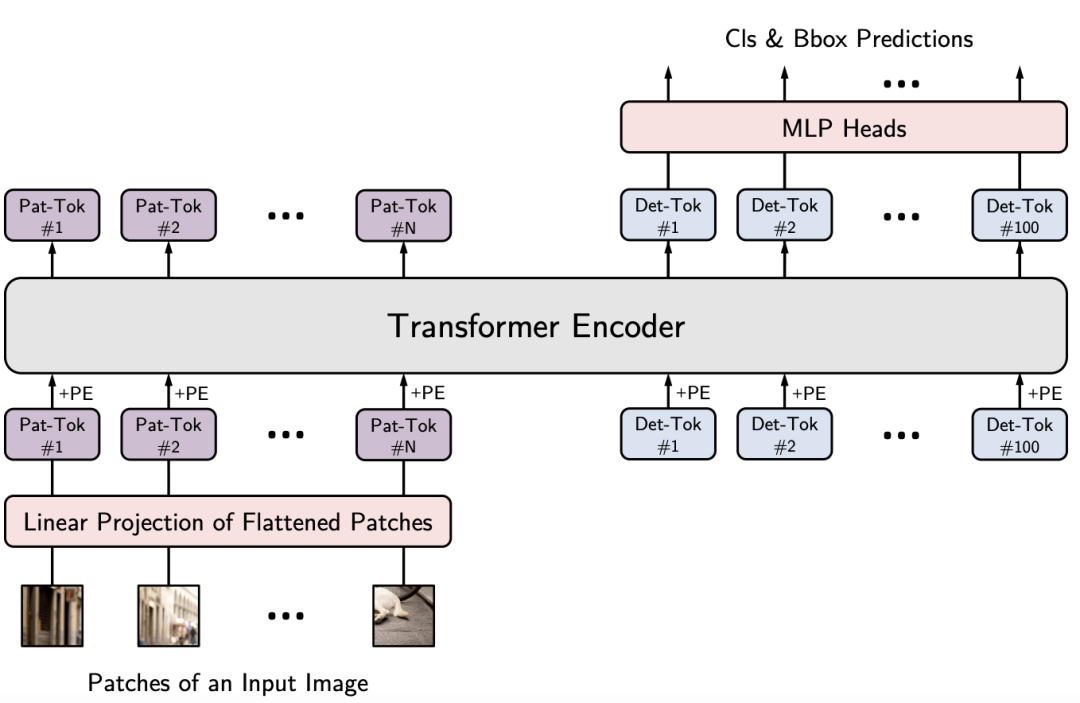
YOLOS删除用于图像分类的[CLS]标记,并将一百个随机初始化的检测标记([DET] 标记)附加到输入补丁嵌入序列以进行目标检测。
在训练过程中,YOLOS将ViT中的图像分类损失替换为bipartite matching loss,这里重点介绍YOLOS的设计方法论。

4
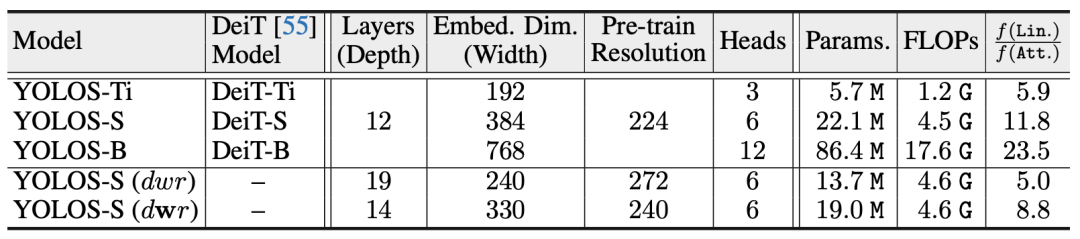
YOLOS的不同版本的结果
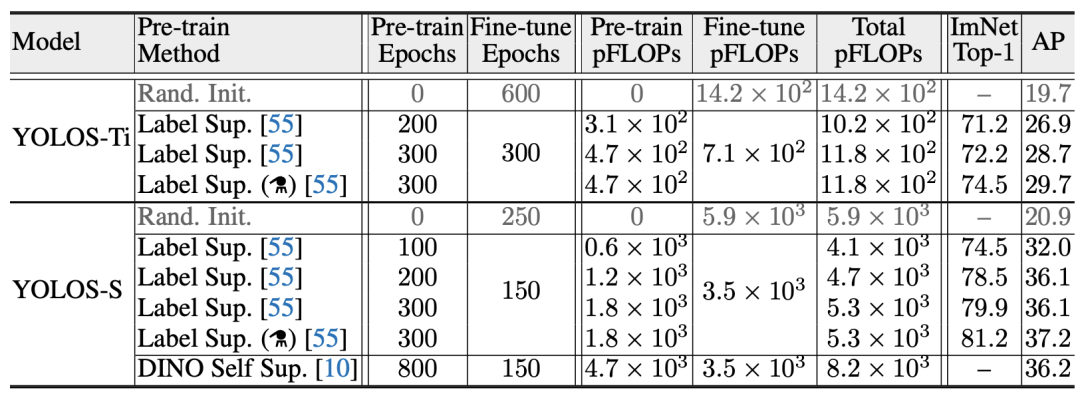
与训练的效果
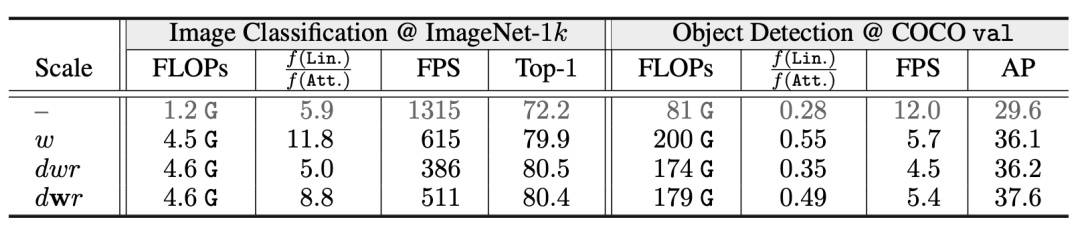
不同尺度模型的预训练和迁移学习性能
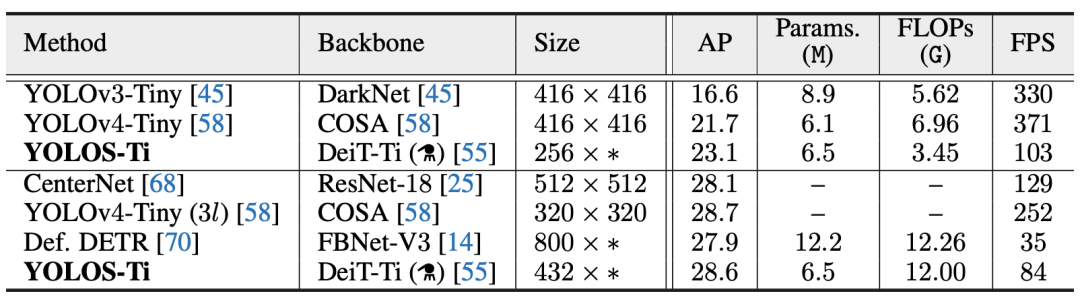
与一些小型CNN检测器的比较

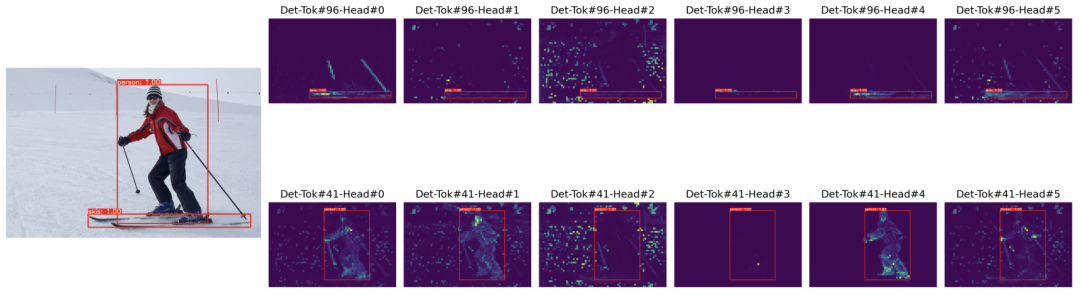
对于给定的YOLOS模型,不同的自注意力头关注不同的模式和不同的位置。一些可视化是可解释的,而另一些则不是。
我们研究了两个YOLOS模型的注意力图差异,即200 epochs ImageNet-1k预训练YOLOS-S和300 epochs ImageNet-1k预训练YOLOS-S。注意这两个模型的AP是一样的(AP=36.1)。从可视化中,我们得出结论,对于给定的预测对象,相应的[DET]标记以及注意力图模式通常对于不同的模型是不同的。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
