
【NLP】到目前为止,机器学习与自然语言处理相遇的那些事

导读
在过去的十年中,自然语言处理(NLP)有了长足的发展。本文将尝试指出和总结直到现在的NLP领域中最关键和最重要的突破,同时还将重点放在仍然存在和新出现的挑战上。
NLP应用程序的记录甚至可以在20世纪早期之前找到,当时人们曾尝试使用机器翻译将文本从一种语言翻译成另一种语言。同时,语言学和计算机科学之间存在一些矛盾的观点,声称语言本质上是生成性的,不能用数学概念来描述。
在1950年,艾伦·图灵(Alan Turing)充分的回答“机器可以思考吗?”这个问题,通过引入“模仿游戏”的研究,计算机在不显着改变结果的情况下进行动作和回答的模拟过程。因此,只要与机器的对话与人的对话无法区分,就认为该机器是“思考的”。实现这一目标的第一个成功尝试是ELIZA,这是麻省理工学院数学与计算项目(“ MAC项目”)中的一个简单程序,成功的让人们误以为它是心理学家,通过把问题转向演讲者来反思问题。另一个程序是PARRY(Colby,1975)模仿一个偏执型精神分裂症患者。多年来,程序变得越来越“智能”,例如Eugene Goostman 或Cleverbot ,它们对真实对话的大型数据库进行统计分析,以确定最佳响应。缺点是无法保持一致性和跟上新主题。图灵测试有很多变体或替代品,例如,当人类不得不向计算机证明其非机器性质时(例如验证码),或者当我们使用AI创作原创艺术时。

在过去的十年中,NLP迅速发展,并开发了下一代应用程序,例如Siri或Alexa等虚拟助手。使用神经网络或无监督学习开发了新的方法,以获取Word2Vec或GloVe等单词的向量表示。这一发展的最新里程碑是引入了基于注意力的模型,该模型使用了一种理解单词和短语之间的上下文关联的机制。
NLP作为AI的一个子领域,检查并检测数据中的模式,并将其用于更好地理解和生成自然语言。NLP有多种应用程序,其中一些是:

NLP将人类语言从原始文本数据的形式转换为结构化数据(计算机可理解的),但是在此之前,它需要通过称为自然语言理解(NLU)的过程来基于语法、上下文感知数据并确定意图和实体。另一方面,自然语言生成(NLG)是将计算机生成的数据转换为人类可以理解的文本的过程。该系统通过代表人类所需的句子,使用文档计划(document-planning),微观计划(micro-planning)和实现(realization)来生成结构良好的动态文档。
本文认知基于的文献积累,是从最近10年以来Google学术搜索获得的最高引用结果开始,同时还跟踪引用和反向引用。搜索包括每个组中的至少一个关键字:机器学习(Machine Learning,
Transformer, CNN, Neural Network, Recurrent, GRU, Deep Learning, Recursive,
LSTM, ML)和NLP(Natural Language, NLP, NLU, NLG)。
显然,在“Transformers”的提出之后,有关该组合主题的论文数量一直在稳步增长,并发表了转移学习的衍生模型和方法(见下图)。
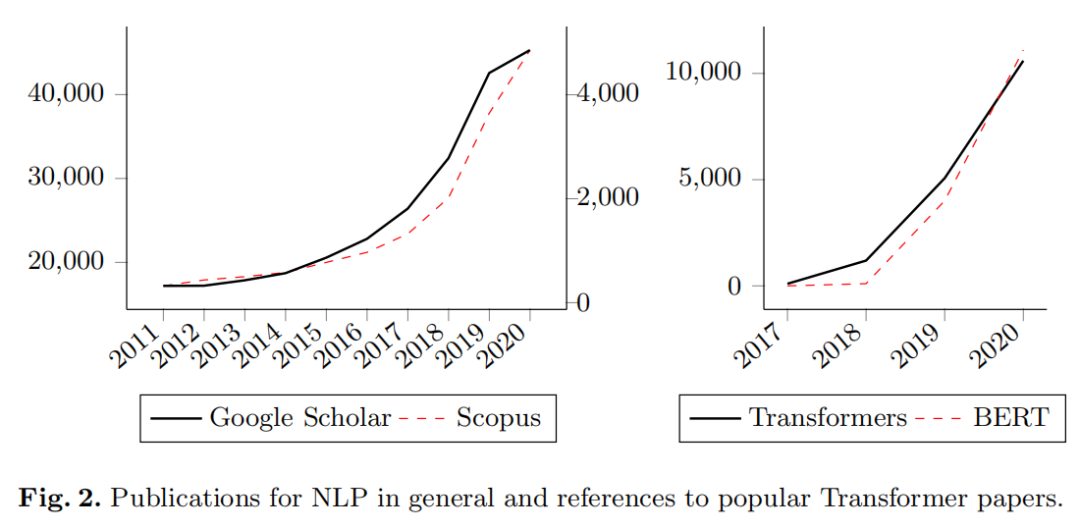
词嵌入在过去十年中占有很强的地位,词嵌入是一个具有相同含义的词具有相似的表示形式的词的术语。2013年,Mikolov引入了两种不同的文本向量化技术:Skip Gram和Common Bag of Words(CBOW)。它们都以一个单独的名称“ Word2Vec”在库中发布,并于同年晚些时候提出了对它们进行一些改进的尝试,以纠正多义性。不久之前,2011年,同一位作者还介绍了一种递归神经网络语言模型(RNNLM),其效率是过去方法的15倍。
2014年,Pennington提出了一种用于检索单词的向量表示的无监督学习算法,称为GloVe 。递归网络和LSTM是ML的有趣的最新发展,Sutskever提出了序列到序列(seq2seq)模型。同样在同一年,卡尔希布伦纳(Kalchbrenner)提出了动态卷积神经网络(DCNN),金(Kim)探索了各种分类任务。
Dong在2015年引入了多列卷积神经网络(MCCNN),以从多个方面分析问题并创建其表示。Yin提出了CNN和RNN之间NLP的比较研究,总结了直到那时的进展。Upadhyay在2017年引入了一种新的方法来管理单词嵌入中的多义性。彼得斯(Peters)在2018年建议了语言模型的嵌入。同年,Chen推出了新的LSTM,其性能优于以前的所有有关自然语言推理的模型。
介绍注意力:Transformers的时代
Bahdanau基于先前提出的编码器-解码器体系结构,引入了术语“注意力”:基于解码器的先前隐藏状态和句子的当前输入状态,每个输入单词的对齐分数。使用此分数,解码器可以决定输入句子的哪些部分最重要,而不必将所有输入句子编码为固定长度的向量。
遵循这个概念,Vaswani 提出了一个相当大胆的提议,导致了Transformers体系结构:在编码器-解码器模型中用多头的自注意层替换了昂贵的RNN,从而显着提高了它们的性能,设定了各种任务的新SOTA。基于这个想法,出现了全新的模型类别(下图)。后来建议使用Transformer XL,以尝试解决原始Transformer输入的有限长度问题。
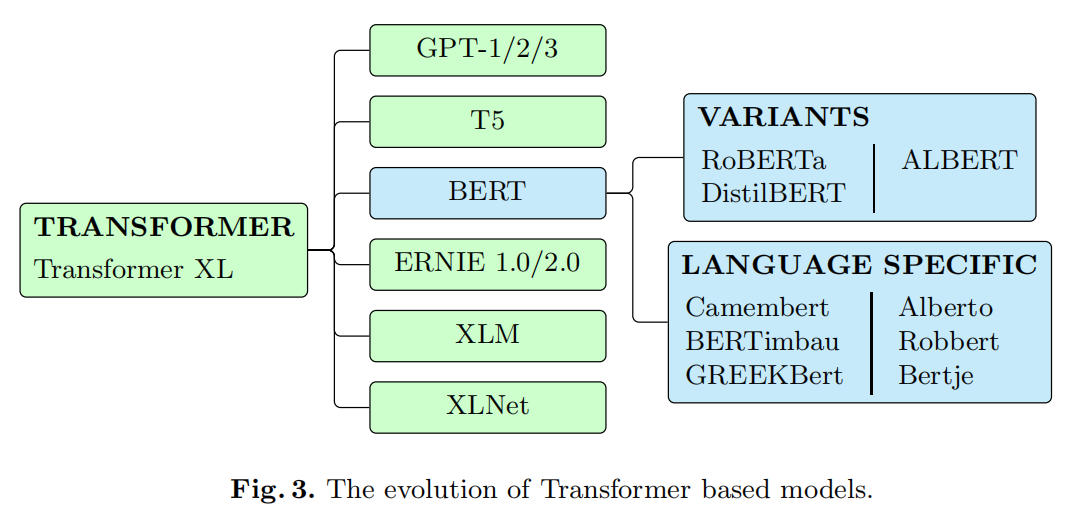
迁移学习和预训练是另一个重要的进步。Howard 和Ruder 在2018年提出了通用语言模型微调(ULMFiT),这是一种可以应用于NLP中任何任务的迁移学习方法,包括3个阶段:训练大量文本以捕获一般特征, 通过区分性微调和倾斜的三角形学习率对当前任务进行微调,最后添加和微调分类器层。判别性微调允许以不同的学习速率来调整每一层,而倾斜的三角形学习速率最初会线性增加学习率,然后线性降低然后再降低。
通过将这种新的Transformer架构的编码器部分进行预训练和分离的思想结合起来,并根据需要进行多次堆叠,OpenAI的团队(Radford ,Brown )创建了3个版本的生成性预训练模型(又名GPT-1 / 2/3)。每个版本都具有大量参数和在更大语料库中进行预训练,从而为诸如文本生成和每个版本的问题解答之类的任务提供了新的最新SOTA。尽管第三版仍未公开可用,但第二版已发布了具有1.17亿参数的较小模型。
Devlin 引入了来自transformer的双向编码器表示(BERT)技术,其架构类似于GPT。顾名思义,它与GPT的基本区别之一是双向性,这有助于更好地理解上下文,从而使其比其他模型具有关键优势。通过发布基本模型和(更大)模型,BERT在问答和文本分类等任务中实现了最先进的性能,并且只需微调一个很小的模型就可以将其用于多种其他NLP任务。在特定于任务的语料库上进行微调。
各种发布从最初的BERT版本中衍生出来,试图对其进行改进或提供针对其缺点的解决方案。RoBERTa 被认为是一种更好的预训练方法,而DistilBERT 和ALBERT 则更小,更快的替代方案与训练速度和降低的内存消耗。
Yang提出了XLNet ,这是一种自回归(AR)模型,试图修复BERT的MLM任务中的差异,其中掩蔽的输入token之间的相关性被忽略了。为了实现这一目标,它使用了一种排列语言建模的目标-意味着所有token都是可以预测的,而不是仅BERT掩蔽token的15%。尽管AR模型通常可以在一个方向上访问上下文,但是排列允许它是双向的。在20个任务上,XLNet的性能有时甚至会大大优于BERT。
百度的Sun于2019年初通过kNowledge IntEgration引入了增强表示(ERNIE),它是一种基于字符的模型,与BERT对抗,适用于当前的最新技术,其掩蔽策略略有不同-多阶段而不是随机的。后来,在2020年,百度发布了ERNIE的第二版,该版本引入了“持续预训练”以及针对词法、句法和语义分析的多项训练任务,声称不仅在中文方面而且在英语方面都优于BERT和XLNet。(请参阅下表)。

通用语言理解评估(GLUE)基准是一种流行的工具,它评估了分析自然语言理解系统的能力,它有自己的排行榜。一年后,它的第二版(SuperGLUE)问世,它具有更多而艰巨的任务,可以对不断发展的NLP模型进行更准确的评估。GLUE由11个任务和它们同等的测试数据集汇编组成,而SuperGLUE还有10个任务。
Common Crawl 是一个包含大量Web爬虫数据的存储库,用作许多模型的预训练材料。它可能很大,但是由于它是一个网络数据集,因此很可能需要大量的预处理才能真正使用。预先训练的模型之间其他常见的数据来源是Wikipedia页面-许多多语言和非英语模型的主要来源-以及Reddit,IMDB或Twitter网站的已解析子集。Kaggle 是拥有大量用户提交的数据集的另一个很好的来源,尽管由于尺寸小得多,它们可能更适合于微调,而不是实际的预训练。
在下表中,总结了流行的开源NLP工具。 Github仓库星标被用作流行程度的指标,同时还确保了该项目在最新/频繁发布的版本中仍处于活动状态。此外,Huggingface自2019年以来一直维护精心策划的git存储库,其中包含许多针对PyTorch和Tensorflow的最新预训练的Transformers,从而可以快速测试这些模型中的任何一个并将原型制作变得轻而易举。
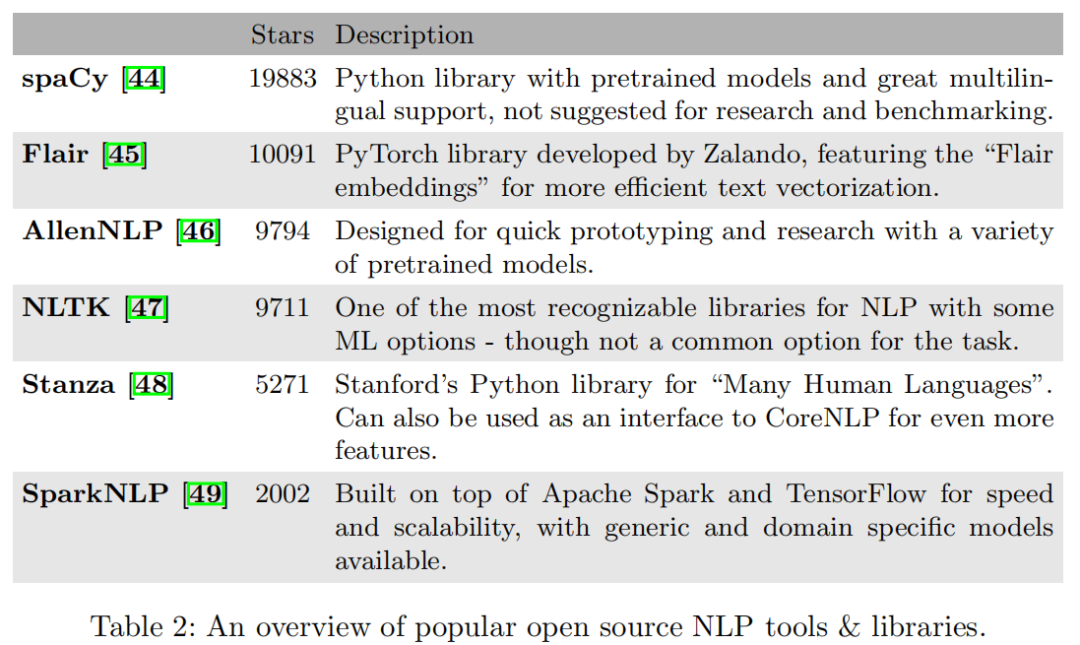
正如人们容易看到的那样,这里有很多选择-每个选择都有其自身的优点和缺点。例如,AllenNLP更注重研究/教育,而spaCy可能是生产的更好选择,而NLTK可能更难使用。最后,一切都取决于应用程序的要求以及开发团队的个人喜好。
尽管NLP在过去几年中发展了很多,但仍然存在一些挑战。为了理解基于语法和上下文的预期含义和实体,所有非结构化上下文都需要转换为有意义的定义数据。
从数据收集开始,通过构建语料库,文本挖掘用于识别文本数据中的非平凡模式,数据预处理使用标记化、规范化和替换的子过程来处理和操作语料库。大多数原始数据对于定义特征通常没有用,这些特征通常包含很多噪声,因此ML模型往往变得无效且难以训练。最初的目标是从带有文本的数据块到清理的token列表,然后进行数据探索和可视化,并在构建模型之前拥有一个更好的数据集。通过将文本拆分为句子、单词并将其转换为标准形式(如扩展构造并将其设置为基本样式),非结构化数据将转换为有用的文本。
单词、歧义、语法甚至俚语的语义含义是需要处理的。在下图中,我们引用了NLP的一些主要挑战。

歧义
如上所示,歧义存在于语言学的各个层面。在自然语言中,这是很常见的,单词根据句子的上下文(上下文单词)具有多种含义。相反,不同的词可以具有相同的含义(同义词)。Irony、sarcasm和humor可能会使用具有特定状态的词语,但实际上却相反。其他一些主要的歧义类型是:词义歧义,其中单个记号可以表示为动词、名词或形容词;语义歧义是指具有多种解释的句子中描述的概念性情况,并且当句子中的双重含义和语言的语法原则不被允许时会发生语法歧义。此外,错误、错别字、俚语和不一致会使翻译复杂化。句子中的很多时候,实际含义和所写内容之间存在差异。语用学是处理这种情况的研究。
当输入数据不是文本而是语音时,会出现另一个歧义问题。语音学(Phonetics)和音系学(phonology)是指token听起来的方式。语音学处理的是声音的特性和感知,这意味着它们是如何产生的,音系学处理的是一种语言中彼此之间的表达关系。
更大的参数(也或许不是?)
随着每一次新的发布,每个团队都在争夺更多参数(参见下图),最终获得了具有数十亿参数的模型。尽管这可能会改善实际结果,但对财务和时间方面的训练成本都将产生巨大的影响,即使只需要进行微调,在某些情况下也使得许多最新架构无法用于某些单个GPU甚至整个GPU集群。除了可能带来的任何环境后果外,这还阻碍了它们在现实世界中的使用。
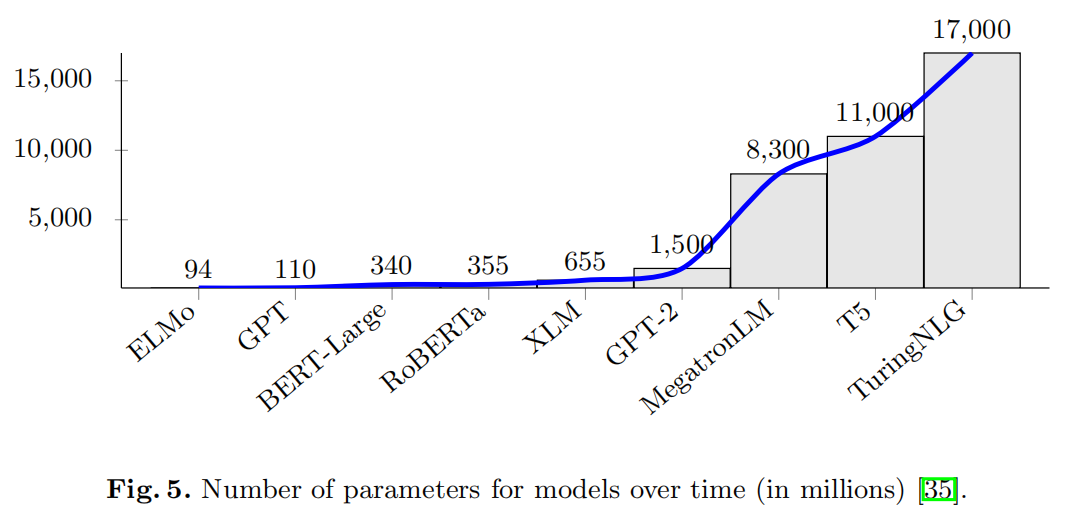
上下文分段和文本重复
原始的Transformer架构以及流行的派生模型都具有预定义的最大输入序列长度-在某些情况下是由模型本身(例如BERT和GPT-1中的512,GPT-2中的1024)或整体硬件限制(即有效内存)。在某些边际情况下,这可能会导致上下文丢失,在这种情况下,输入会分成一个部分,其中的内容与其下一个或以前的内容相关。尽管在实践中通常不会出现问题,但还是有一些建议,例如上述的Transformer XL可以提供帮助。
此外,对于问答(QA)任务或需要实际生成文本的任何其他任务,输出在某些情况下可能是重复的,甚至是不相关的。尽管有时这是由于模型本身或训练不足所致,但在某些情况下,原因是这种上下文分散或缺少足够大/足够多的数据集。
翻译迷失(Lost in Translation)
如今,大多数经过预训练的模型都将重点放在英语上,有些方法则将重点放在基于字符的语言上,例如中文或阿拉伯语。因此,极少数的多语言选项是针对具有单语言模型的本地语言的BERT或GPT的稀疏预训练尝试(见下图)。经过Wikipedia语料库训练的BERT(或m-BERT)的多语言版本是另一个这样的选择,它支持104种不同的语言。但是仍然缺少足够大、高质量、多语言的数据集,因为即使在Wikipedia中,许多语言的页面数量也比英语要少得多(有时太少,甚至无法考虑)。
XLM模型尝试通过添加字节对编码并一次以两种语言训练BERT,同时将“掩盖语言建模”目标更改为“翻译语言建模”,同时屏蔽两种语言中的token,从而尝试进一步提高多语言能力。尽管创建了可以胜过m-BERT的多语言模型,但它却使数据可用性变得更加困难,因为现在同时需要两种语言的相同内容。XLM-R 是XLM的后继产品,它使用更大的数据集并以可以针对一种语言进行微调然后用于跨语言任务的规模来提高性能。
尽管上述所有方法的确取得了有趣的结果,但英语和其他语言之间在问答(QA)等任务之间仍然存在巨大差距。例如,对于MLQA问答基准,英语的F1 / EM(完全匹配)分数为80.6 / 67.8,德语的分数为68.5 / 53.6。
在过去的十年中,无论是整体改进还是针对特定任务,NLP领域均取得了巨大进步。它从向量化革命开始,在每个NLP pipeline的核心都针对最重要的任务提出了新的建议,直到最近推出的Transformers和迁移学习标志着“黄金时代”的开始。
在此期间,越来越多的公司开始采用Chatbot技术。从简单的模式匹配支持代理开始,他们变得越来越复杂,逐渐开始采用机器学习技术和模型,使它们更像人类,并转向实际的学习,远离模式。
机器翻译也在稳步发展。作为Encoder-Decoder模型及其Transformer后续产品的主要任务之一,如今的自动翻译应用程序比以往任何时候都更加准确。随着文本生成模型的发展,自动化的文章生成应用程序开始出现,并且虚拟文案撰写者与人类无法区分,这可能很快就会成为现实。
但是,尽管NLP已经走了这么远,但仍有许多事情要做。多语言支持模型还有很长的路要走,最近的模型将需要进行大量的优化和缩小规模,或者更广泛地采用有效的硬件,然后才能在实际应用中真正使用它们。下一件大事还有待观察,而Transfoemers目前正在引领潮流。
参考资料:
[1]https://arxiv.org/pdf/2104.10213.pdf

END
往期精彩回顾 本站qq群851320808,加入微信群请扫码: