自然语言处理NLP技术爱好者,别错过

项目背景:
近些年,伴随着抖音的崛起,短视频在内容传播方面发展得如火如荼,但即便如此,文本内容的形式仍然占据重要地位。
而文本内容的传播最重要的一点就是信息的准确性,尤其是一些有着巨大用户群体的流量平台更加注重内容文本的审核,由此,文本自动纠错审核技术便发挥着不可替代的作用。
文本纠错支持短文本、长文本、语音识别结果等多种文本内容,在搜索引擎、人机对话、语音识别、内容审核等方面有广泛的应用,能显著提高这些场景下的语义准确性和用户体验。
应用场景:
文本自动纠错技术在文学创作、搜索引擎、人机对话、语音识别、内容审核等方面有广泛的应用,比如:
作文批改:检查并纠正作文中的拼写问题,大幅度减轻教师压力
写作辅助:在内容写作平台上内嵌纠错模块,可在作者写作时自动检查并提示错别字情况
新闻媒体:辅助媒体、出版社进行文本编辑、校对工作,有效避免常见错误
公文纠错:针对公文写作场景,提供字词、专有名词的检查与纠错,辅助进行公文审阅校对
搜索纠错:用户经常在搜索时输入错误,通过分析搜索query的形式和特征,可自动纠正搜索query并提示用户
asr纠错:将文本纠错嵌入对话系统中,可自动修正语音识别转文本过程中的错别字,向对话理解系统传递纠错后的正确query
课程目标:
1.掌握企业内部算法工程师建模的全流程,包括业务分析、数据处理、问题拆解、模型训练、推理优化和线上部署等环节
2.掌握课程中成分抽取、文本语义建模、语义向量检索和csc文本纠错等每个子任务的建模技术
3.掌握模型优化的一些常见trick,以及一些推理加速的框架和技术
核心技术点:
Bert mlm预训练技术、自定义masking策略、多卡分布式训练
Bert+span双指针网络、对抗训练fgm和pgd的实现
simcse语义相似度建模、faiss语义向量检索
MacBert4csc纠错技术、混合精度训练AMP技术
onnxruntime和tensorrt等常见模型加速技术
Flask/Fastapi等web部署框架技术
课程安排:
本项目适用于通用领域csc文本纠错和任何垂直领域的专有名词纠错,项目拆解可以分为三个子任务,分别为成分抽取任务、语义建模和检索任务、csc文本纠错任务,其中,每一个子任务都可以作为独立的nlp项目,课程讲解按照上述三个任务的顺序依次推进,最后会依次串起来,构建完整的纠错服务系统
部分项目样图:

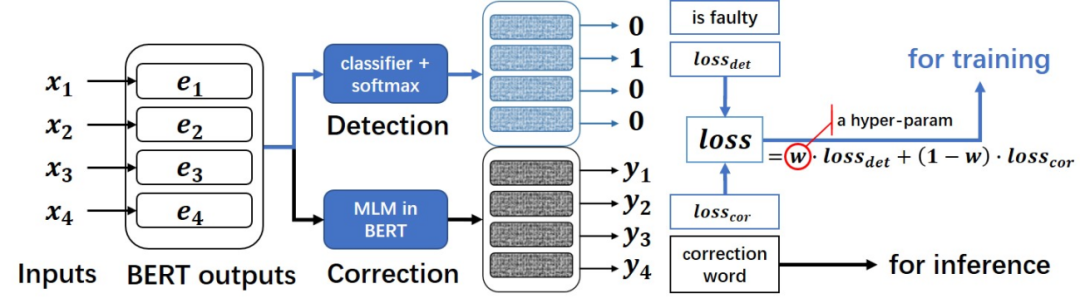
MacBERT4CSC文本纠错模型结构:
本模型是MacBERT改变网络结构的中文文本纠错模型,可支持BERT类模型为backbone
在原生BERT模型上进行了魔改,追加了一个全连接层作为错误检测即detection,MacBERT4CSC训练时用detection层和correction层的loss加权得到最终的loss,预测时用BERT MLM的correction权重即可