
面经 | 滴滴数据分析岗试题分享
(给机器学习算法与Python实战加星标,提升AI技能)

1
2
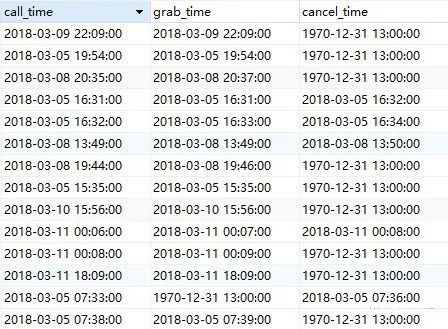
订单的应答率、完单率分别是多少?
呼叫应答时间多长?
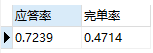
从这一周的数据来看,呼叫量最高的是哪一个小时(当地时间)?呼叫量最少的是哪一个小时(当地时间)?
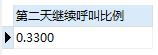
呼叫订单第二天继续呼叫的比例有多少?
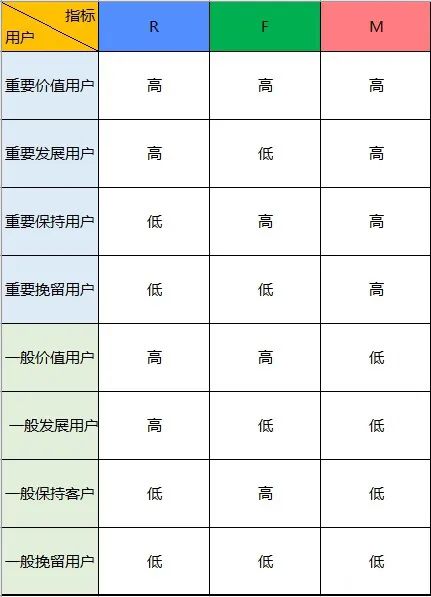
如果要对表中乘客进行分类,你认为需要参考哪一些因素?
3
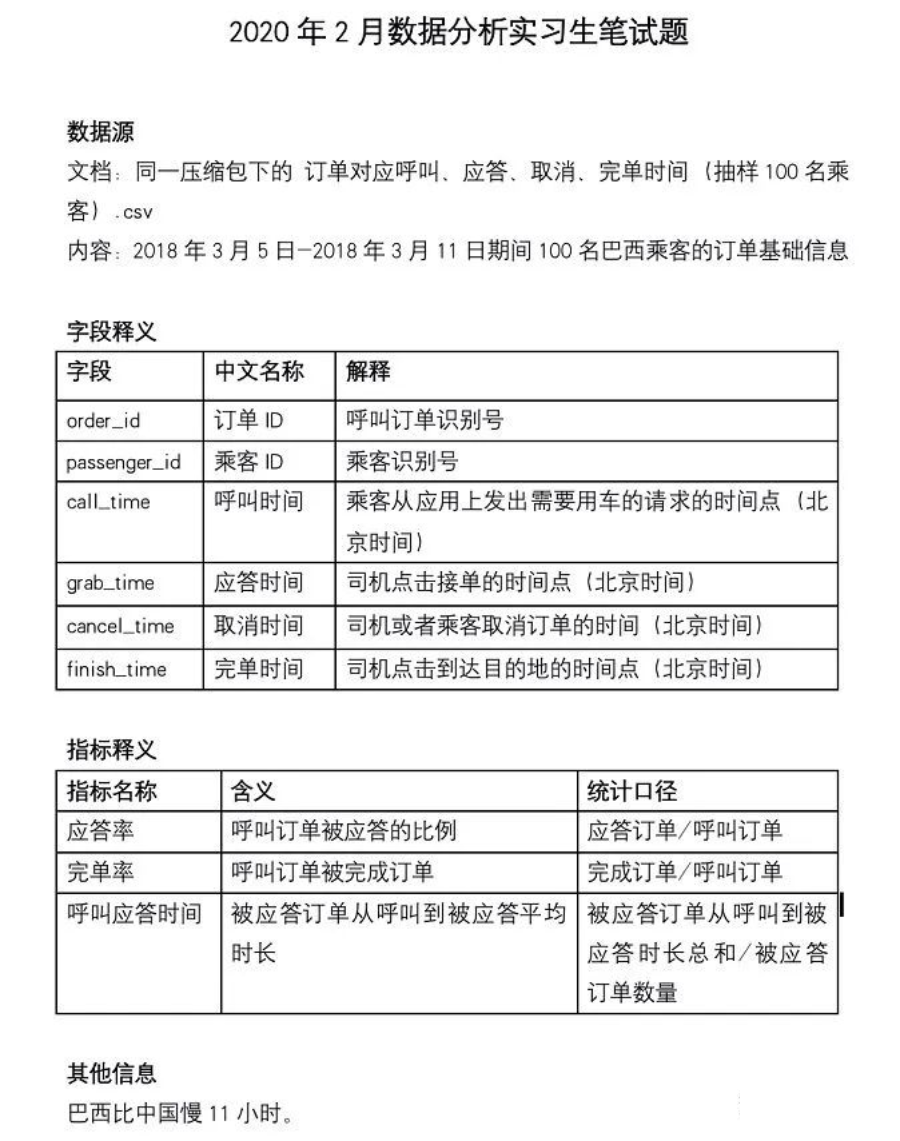
将时间相关列转换格式
按巴西比中国慢11小时,将表中北京时间转换为巴西时间
-- 利用cast函数转换成日期数据update didi setcall_time = cast(call_time as datetime),grab_time = cast(grab_time as datetime),cancel_time = cast(cancel_time as datetime),finish_time = cast(finish_time as datetime);
-- 将北京时间调整为巴西时间,date_sub函数update didi setcall_time = date_sub(call_time,interval 11 hour ),grab_time = date_sub(grab_time,interval 11 hour ),cancel_time = date_sub(cancel_time,interval 11 hour ),finish_time = date_sub(finish_time,interval 11 hour );
应答率 = 应答订单数 / 呼叫订单数
完单率 = 完成订单数 / 呼叫订单数
select sum(if(year(grab_time)<>1970,1,0))/count(call_time)as '应答率',sum(if(year(finish_time)<>1970,1,0))/count(call_time)as '完单率'from didi

-- 使用timestampdiff函数,计算应答时间与呼叫时间之间的时长
select sum(TIMESTAMPDIFF(MINUTE,call_time,grab_time))/count(grab_time)as '呼叫应答时间'
from didi
where year(grab_time)<>1970;
-- 新增一列alter table didi add column call_time_hour VARCHAR(255);-- 使用substr函数做字符串截取,为新列赋值update didi set call_time_hour = SUBSTR(call_time from 12 for 2);-- 方法2:使用date_format函数转换格式update didi set call_time_hour = DATE_FORMAT(call_time,'%k')
-- 找出呼叫量最高的小时,显示2行防止出现重复值。select call_time_hour,count(call_time)as'呼叫量'from didiGROUP BY call_time_hourORDER BY count(call_time) desclimit 2;
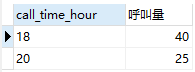
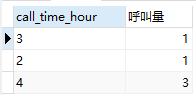
-- 找出呼叫量最少的小时,显示3行确认是否有第三个相等值。select call_time_hour,count(call_time)as'呼叫量'from didiGROUP BY call_time_hourORDER BY count(call_time) asclimit 3;
select count(DISTINCT a.order_id)/(select count(DISTINCT order_id) from didi)as'第二天继续呼叫比例'from didi a join didi bon a.passenger_id = b.passenger_idwhere datediff(a.call_time,b.call_time)=1;
R:乘客上一次打车距离3月11日的时间间隔
F:乘客在数据期间的打车频率
M:打车消费金额(表中无打车金额,可以用完成订单总时长代替)
请后台回复【入群】
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论