
目标检测Trick | SEA方法轻松抹平One-Stage与Two-Stage目标检测之间的差距


作者重新讨论了单阶段和两阶段的检测器蒸馏任务,并提出了一个简单而有效的语义感知框架来填补它们之间的空白。作者通过设计类别Anchor来生成每个类别的代表性模式,并规范像素级的拓扑距离和类别Anchor之间的拓扑距离,以进一步加强它们的语义联系,从而解决像素级的语义失衡问题。
作者将本文的方法命名为SEA(SEmantic-aware Alignment)蒸馏,因为通过语义依赖提取密集的细粒度信息的本质,以很好地促进蒸馏效果。
SEA很好地适用于两种检测管道,并在单阶段和两阶段检测器上的具有挑战性的COCO目标检测任务上取得了新的最先进的结果。其在实例分割上的优越性能进一步体现了其泛化能力。2x-distilled RetinaNet和使用ResNet50-FPN的FCOS均优于相应的3x ResNet101-FPN教师,分别达到40.64和43.06 AP。
1、简介
在目标检测中,设计良好的骨干网络为强大的目标检测器提供了强大的支持,以解决具有挑战性的任务。延迟和准确性之间的平衡是目标检测中不可避免的权衡,特别是当在移动设备上部署模型时。与改变原始模型权重和存储位的剪枝和量化不同,知识蒸馏通过将知识从训练有素的教师模型转移到相对较小的学生模型来保持目标模型的完整,这现在成为模型加速的常见做法。
近年来,由于没有专门设计的算子,单阶段检测器有利于移动应用。然而,单阶段检测器的蒸馏性能仍落后于两阶段检测器。其原因是大多数用于目标检测的蒸馏方法主要是为两阶段检测器设计的。例如,DSIG将两阶段检测器提高了2%以上。但当应用于FCOS时,其性能降低了0.8%。
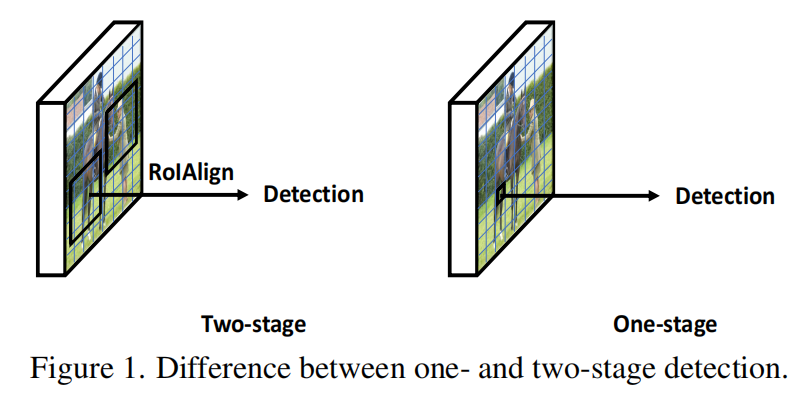
这种不一致性主要来自于单阶段和两阶段检测管道之间的差异(图1)。在两阶段管道中,先前的proposals由Region Proposal Network生成,以提取感兴趣区域(RoI)特征,使预测来自像素集合。而在没有建议的单阶段检测器(也称为密集检测器)中,密集特征映射是通过连续卷积处理的。单个像素被直接用于产生预测。
在单阶段检测器中存在的一个潜在问题是,“感兴趣的区域”(即选定的单个像素)与密集检测器中真正感兴趣的区域(即边界框)不对齐。相比之下,在两阶段设计中采用的区域建议自然适合于实例级的框预测。此外,在单阶段教师和学生模型之间的像素到像素蒸馏过程中,对不重要或错误像素的预测可能会引入不必要的噪声,从而导致基于关系的方法可能错误地利用元素之间的相关性,从而导致性能推断。
为了解决这个问题,作者提出了一个新的视角来理解密集检测器的知识蒸馏。如前所述,密集检测器由多个层的特征图组成,其中像素级训练样本极不平衡,并且不能从密集特征图中利用任何显式实例级关系。此外,密集检测器还有另一个并行分支来处理定位信息,这可以被更好地利用。
1、解决不平衡问题
不同于将前景(FG)样本与背景(BG)样本的比例正规化的两阶段检测器,只有单阶段的检测器。这导致了FG和BG之间更高水平的不平衡,甚至是不同类别的前景之间的不平衡。Two stage oriented distillers倾向于将FG与BG分离,并以不同的方式调整其损失重量。
在单阶段检测器中,FG和BG很难在密集的特征图上进行分割和调谐。如果施加正则化,剧烈的不平衡会使蒸馏的效果降低。为了解决这个问题,作者编码了一种名为类别Anchor的新知识表示,它被设计为每个现有类别的通用模式。它还可以作为场景图像的密集特征图的语义摘要。当涉及到提取类别锚时,类别之间的不平衡(包括BG)得到了缓和。
2、在像素级中挖掘稀疏关系
两阶段风格的实例级关系很难转移到单阶段管道中。 uniformly-sampled dense relation distillation甚至降低了检测性能。这说明需要更好地定义每个语义像素内的丰富信息之间的关系。此外,如果能筛选出不相关的密集关系,那将会更好。
为此,作者将空间像素表示映射到一个单位超球体中,其中保留了与附近元素的空间局部相似性,而不失去对那些具有明显特征的元素的识别能力。这里不是测量所有元素之间的关系,而是只量化这些元素和类别Anchor之间的距离。它允许大量毫无意义的关系被丢弃,并自动完成稀疏化。作者将这种策略命名为拓扑距离蒸馏法(Topological Distance Distillation)。
3、解纠缠分支中的不同语义
分类和边界框回归在经验上并不是互补的。因此,它们是由两个独立的分支独立完成的,以解开特征,并使它们专注于优化自己的任务。此外,实验结果(表5)表明,仅仅通过边界框分支中的MSE损失来匹配像素并不利于其性能。
如图4所示,高激活通常聚集在分支中的对象周围,用于回归边界框,而分类分支的激活更有可能从对象区域开始广泛传播。考虑到这种差异,作者没有采用简单的像素-像素匹配,而是开发了定位分布对齐法来通过概率分布匹配学生和教师之间的相对定位回归。这样就避免了提取每个激活图的绝对值,并找到了另一种方法来建模空间域中相对位置的信息。
主要贡献:
解决了上述问题,并提出了很少研究的单阶段检测器蒸馏的最终解决方案。为了在多个尺度和层次中利用密集的特征映射,作者设计了一个合适的知识表示类别Anchor来总结场景中的一般语义模式。在此基础上,引入了拓扑距离来保持像素级样本中的语义联系。最后,将定位蒸馏作为一个分布对齐问题,以有效地传递定位信息的知识。作者将本文的方法命名为语义感知的对齐蒸馏,这涉及到从语义感知的角度利用细粒度知识的本质。
本文的方法在COCO检测任务上的性能大大优于之前所有最先进的目标检测蒸馏器,并显示了其在COCO实例分割任务上的通用性。此外,我们在两阶段检测器上取得了与最先进水平相当的强大性能。
虽然两阶段和一阶段的检测器采用不同的处理方案,但它们都有一个共同点:大部分参数都用于生成高级语义特征图,作为后续任务的基础。在这个交叉点上蒸馏是弥合它们之间差距的关键。在消融研究中分析了每个组件的影响,并测试了超参数的敏感性。
本文的方法是稳定的训练,并不引入额外的参数来进行蒸馏训练。据作者描述,这是第一次尝试实现单阶段目标检测器蒸馏。
2、相关方法
2.1 目标检测
基于深度学习的目标检测器分为两种,即两阶段检测器和单阶段检测器。前者生成提取区域特征的prior proposals,而后者在没有先验的情况下完成目标检测。
两阶段的方法主要源于R-CNN,在下一步工作进一步细化R-CNN管道,以生成更精确的proposals并保证实时性。还有许多优秀的方法来进一步改进两阶段检测器。它们都按区域包围提取的特征,并将其视为分类和定位中的实例。
在没有生成proposals的情况下,单阶段检测器设计为低延迟,同时保持高精度。YOLO最初引入Anchor来从特征图中预测类和边界框。为了缓解密集检测中的前景背景不平衡问题,RetinaNet提出了Focal Loss来减轻分类良好的简单示例的权重。
此外,ATSS改进了标签分配算法,GFL提出了优化的Focal Loss和box distribution loss。也有Anchor-free检测器丢弃先前的边界框,例如FCOS,它仅从点进行检测。在本文中对这些检测器进行了实验,包括两阶段、单阶段 Anchor -based和Anchor-free 的检测器。
2.2 知识蒸馏
知识蒸馏将知识从大的教师模型转移到轻量级的学生模型。Hinton等人首先将输出层的soft logits视为需要提炼的知识表示。此外,中间特征表示和注意力映射也被于匹配学生和教师。最近,一些知识蒸馏框架进一步挖掘了这种潜力,如Mutual Learning、Noisy Student 和TAKD。
目标检测从知识蒸馏中获益很多,因为它以更低的推理成本和内存占用实现了相当大的准确性。这里将检测蒸馏方法分为4组:
Region-based
Chen等人首先提出了一个用于两阶段检测器的检测知识蒸馏框架,并专门重新设计了用于检测的logits distillation loss。Wang等人从GT中生成细粒度Mask以提取特征图中选定的近目标区域。Sun等人提出了一种高斯Mask以增加对目标中心附近区域的关注,并采用学习率衰减策略来提高泛化性。最近,Guo等人将这些特征分为前景和背景,处理方式不同。这些方法都首先提取注意力区域,然后对这些选定的像素进行蒸馏。
Relation-based
Chen等和Dai等在检测中利用实例关系将学生与教师相结合。这些方法还使用先前的区域(即建议和GT框)来选择区域特征作为元素,以建立关系,以进行进一步的蒸馏。
Backbone-based
Zhang等人利用了注意力模块,并生成了一个level的注意力图,用于在检测器中进行主干蒸馏。但是,它没有使用以下的检测头,它也包含了足够的信息。
Segmentation-based
Liu等人提出了一种结构化的方法来转移规则像素块之间的关系。请注意,在检测中,这种关系由于背景的比例较高而带来了很大的噪声。Shu等人提取的通道信息-检测器的激活图与分割的不同。
3、语义感知对齐蒸馏
在本节中介绍了整体蒸馏管道,该管道由类别Anchor蒸馏、拓扑距离蒸馏和定位分布对齐组成。类别Anchor表示从多尺度特征图中挖掘的全局类别信息。它描述了语义原型和单个像素之间的分布,而不会受到类间不平衡的不利影响。因此,在潜在嵌入空间中可以更好地说明拓扑距离。定位分布对齐有效地利用分布匹配损失来提取从教师到学生的回归特征图,其中像素在空间相对位置上表现出语义。
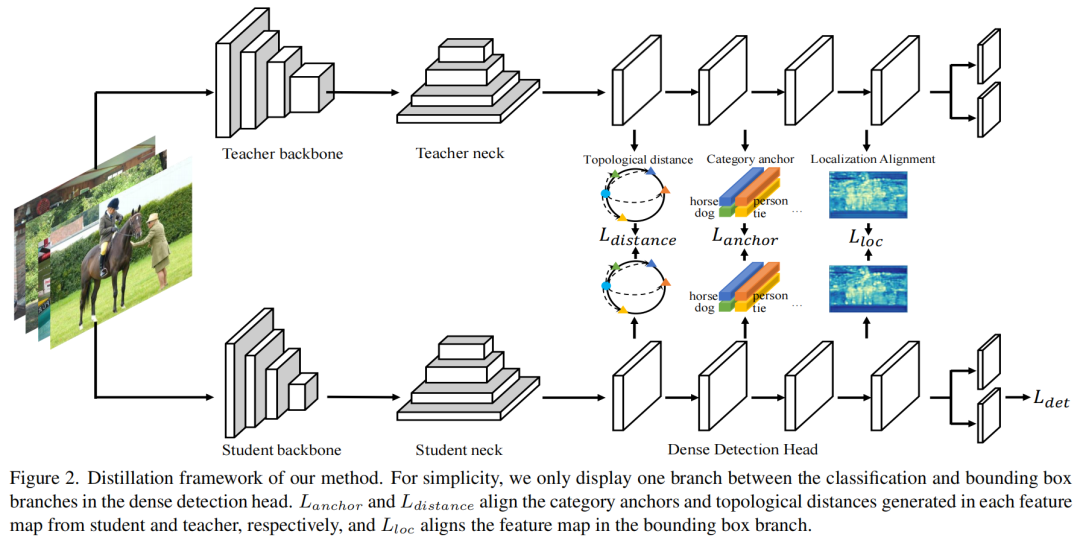
如图2所示在密集的检测器头(卷积分支)上应用了一组蒸馏损失,这不会引入额外的参数,也会带来少量的额外的训练开销。在管道中,单类别的Anchor首先从特征映射中生成。在此基础上,计算了各像素与Anchor之间的拓扑距离。利用学生和教师Anchor和拓扑距离,将Anchor Loss 和拓扑距离损失应用于学生训练。实验位置分布对齐损失规范化边界框分支。
3.1 Category Anchor Distillation
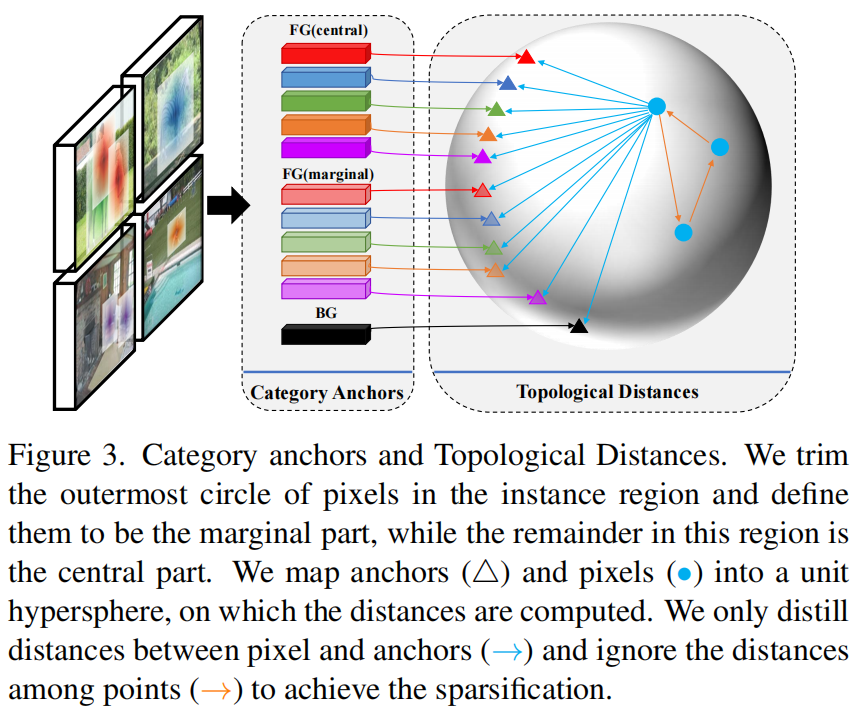
为了避免来自密集像素匹配的一系列卷积层的不平衡信息,作者设计了类别Anchor作为一个图像批处理中现有实例的分类摘要(图3)。 categorical summary functions类似于两阶段检测器,它提取感兴趣的区域以辅助检测。作者选择了使用注意力像素来建立类别Anchor,而不是像素级模仿,而是对类别区域进行学生和教师模型之间的模仿。
考虑到正方形的边框并不代表真实物体的实际形状,作者将边框分为中心部分和边缘部分。因此,每个类别都拥有两个类别Anchor,它们收集了整个图像批处理中属于分类区域的所有像素。
具体来说,在一个batch图像批特征图由层,类别Anchor可以表示为,其中,索引不同类别除了这批的背景,,这里分别表示中央类别Anchor,边缘类别Anchor类别。请注意,这里不会丢弃属于背景的像素,而是为背景生成一个Anchor。
类别Anchor将通过以下步骤生成:
初始化全零类别Mask 。对于中属于类别的每个实例,将其划分为中心部分和边缘部分,并将、上对应区域的值分别设置为1。最后的类别Mask原来是 ,其中。 对于第p个类别Anchor,特征图上的相关区域被所掩盖。 对于第p个类别Anchor,掩蔽特征图通过空间平均池化向量化为类别Anchor,如。
采用FPN中提出的特征融合检测方案,具有连续卷积层的网络也可以产生多尺度特征图。因此,在本文蒸馏框架中,最终的类别Anchor被表示为,其中是由卷积特征图的第k个尺度级的第m个conv生成的类别Anchor。
Multi-level Anchor Matching
不同level的Anchor集中了从多分辨率特征图中收集到的信息。提取学生和教师Anchor在所有level的特征图:
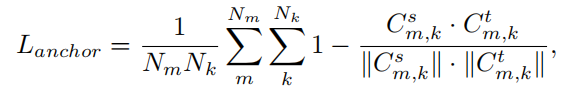
其中,和分别代表学生和教师的Anchor。的目标是使学生的各个类别与教师的类别保持一致。从多尺度的角度保证了对一般类别原型的优化。这里将它应用于分类框分支和边界框分支。
3.2 Topological Distance Distillation
在起始点检测框架中,我们将每个像素视为一个单独的样本,其中每个像素都拥有足够的信息来支持以下分类和定位回归任务。同样,样本在嵌入空间中分散,且与Structured knowledge distillation之间存在相关性。这里不是建模所有像素之间的密集相关性,而是测量像素和类别Anchor之间的距离。这些距离构建了一个拓扑结构,用于根据Anchor来校准单个样本。训练有素的教师对距离有更精确的测量方法。因此,它规范了学生的拓扑结构。作者设计了学生和教师之间的拓扑距离蒸馏损失为:
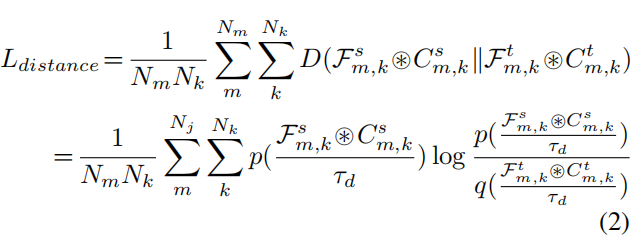
其中, 表示计算距离的余弦相似度,表示温度。
3.3 Localization Distribution Alignment
根据经验观察到,检测器中的边界框分支的行为与分类分支不同。值得注意的是,分类分支中的像素在GT实例的边缘更容易被激活,揭示了高度显著的语义。然而,对于每个像素的内容与类信息不相关的边界框(bbox)分支,它对场景理解的语义敏感度较低,因为它预测了从Anchor或指向GT框的。
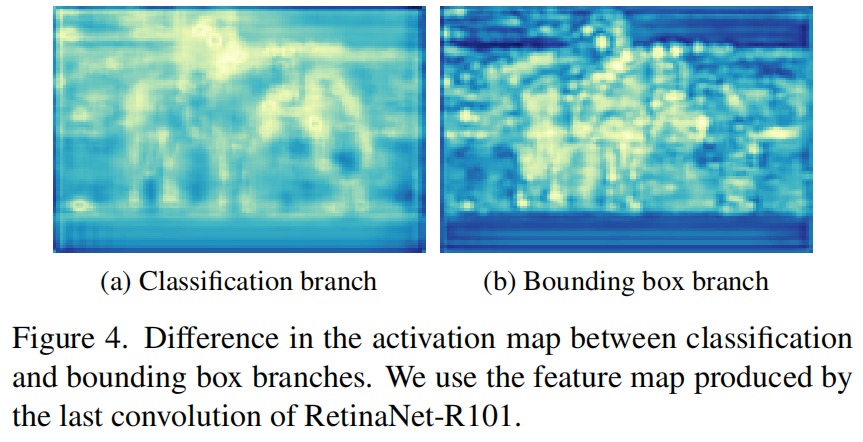
如图4所示,bbox特征图在图像中具有更被激活的像素,这实际上表明了它自身和GT中心之间的相对位置。受此发现的启发在空间域建立了分布对齐模型,并有效KL散度损失将bbox层提取为:
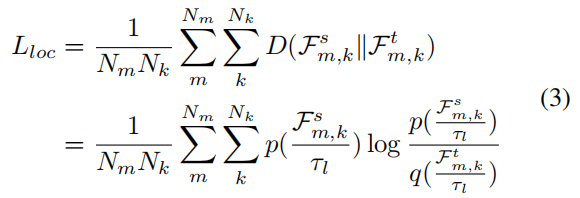
其中,表示第m个尺度,第k个bbox分支特征图。是logit的温度。
3.4 Overall Distillation Loss
将上述三种蒸馏损失纳入到检测损失中,得到的蒸馏损失为:
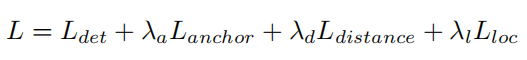
其中,为学生检测器的原始检测损失,包括分类和定位损失,每种类型的检测器的设计都不同。、和分别表示、和的惩罚系数。根据经验将设置为。
4、实验
4.1 消融实验
1、组件分析

Anchor Loss
实现给学生基线带来了2.31 AP提升,而直接像素-像素匹配仅达到1.42 AP。这意味着当密集的像素负责预测任务时,有必要总结所有像素之间的分类信息,而不是模拟全局特征图。通过对的蒸馏,大型特征图中的信息以一种不平衡的方式避免了蒸馏,因为它集中在类别Anchor 上。
Distance Loss
距离损失比基线高出约1.05 AP,这意味着在密集的检测器中,像素之间的相关性对形成密集的拓扑空间很重要。没有建模密集关系,而是限制了像素本身与学生和教师的每个类别Anchor 之间的距离,这使学生更好地正则化。
Location Distribution Alignment
添加可以将FCOS-ResNet50提高到42.52 AP。它确实有助于对齐学生和教师的定位信息,这表明边界框层中的像素符合一种分布。此外,在边界框层上应用L2损失对性能没有好处,这表明匹配边界框层中的分布比直接的像素-像素蒸馏更有效。
2、超参数灵敏度
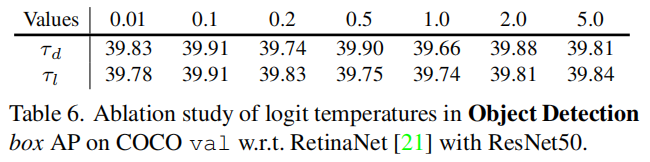
Loss penalty coefficients
测试了等式中3个损失惩罚系数、和的敏感性(4)(详见图5)。结果表明,这些系数在较大范围内具有鲁棒性,验证了该方法的稳定性。
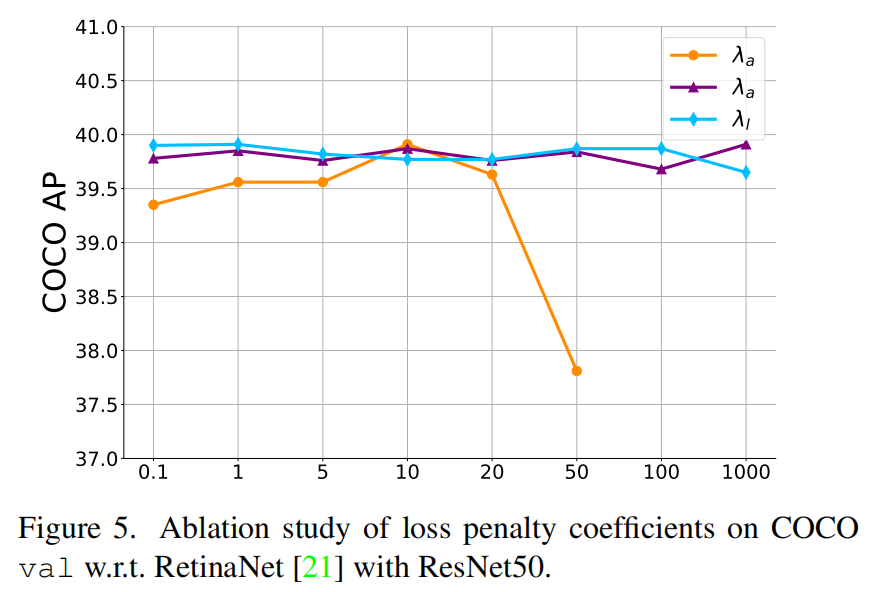
Temperatures
测试了方程式中KLD损失的logit温度和。其结果如表6所示。该性能在0.01和5.0的范围内非常稳健。
4.2 主要实验
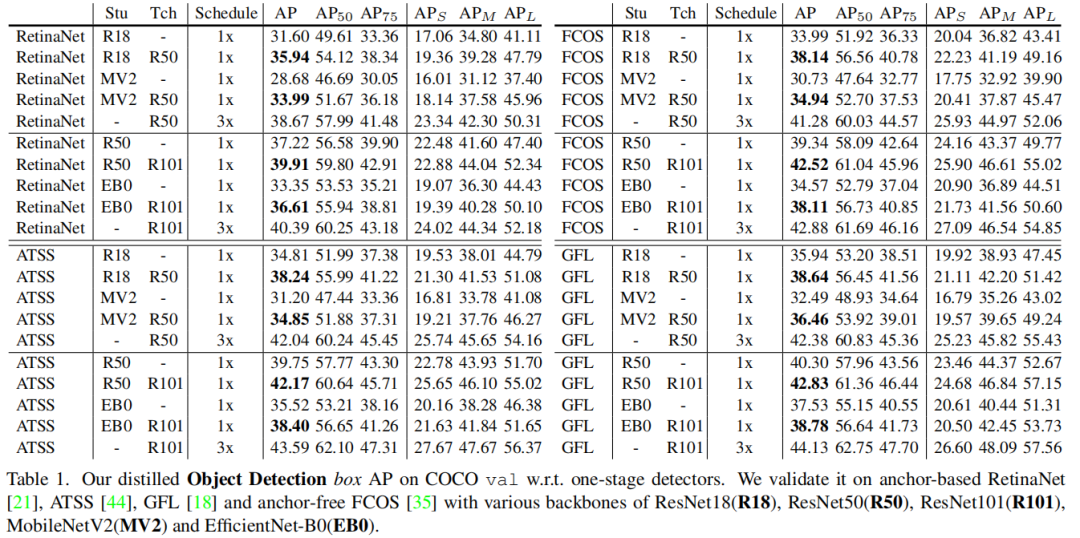
4.3 Faster RCNN与Cascade R-CNN
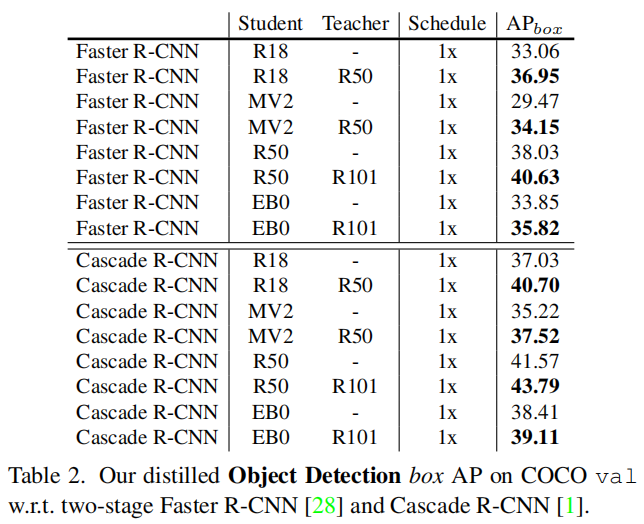
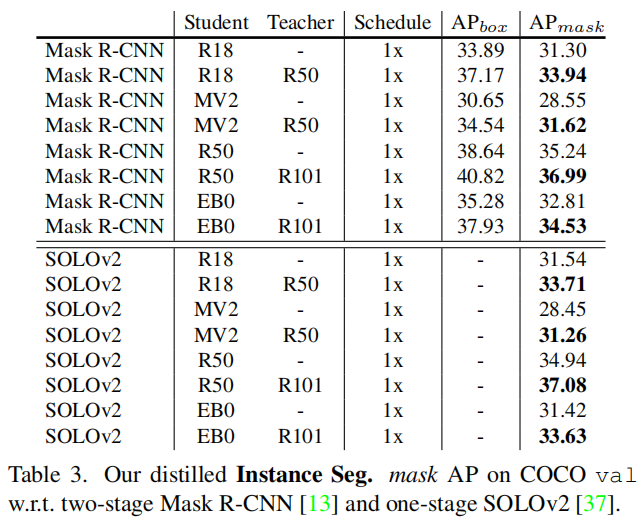
4.4 Mask RCNN与SOLOv2
5 局限与总结
5.1 局限
一般的限制在于提炼的本质,教师模型不可避免地需要将其知识传递给学生模型。虽然蒸馏主要是针对小的学生模型,但对于大的学生模型很难找到合适的教师模型。
5.2 总结
在本文中提出了用于目标探测器的SEA(SEmantic-Aware Alignment)蒸馏方法。为了弥合单阶段和两阶段检测器蒸馏之间的差距,SEA将每个像素作为实例,设计类别Anchor来总结场景图像中的分类信息,处理密集像素中的剧烈不平衡。在此基础上,对语义关系进行建模,并对其进行稀疏化,使蒸馏更加结构化和完整。此外,还有效地对齐了学生和教师之间的未被充分研究的边界框分支中的定位分布。大量的实验证明了SEA方法在目标检测和实例分割蒸馏任务方面的有效性和鲁棒性。
6、参考文献
[1]. SEA: Bridging the Gap Between One- and Two-stage Detector Distillation via SEmantic-aware Alignment.
7、推荐阅读
书童改进 | YOLOv5之架构改进、样本匹配升级、量化部署、剪枝、自蒸馏以及异构蒸馏
量化部署必卷 | EasyQuant量化通过Scale优化轻松超越TensorRT量化
量化部署篇 | Vision Transformer应该如何进行PTQ量化?这个方法或许可以参考!
扫描上方二维码可联系小书童加入交流群~
想要了解更多前沿AI视觉感知全栈知识【分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF】、行业技术方案【AI安防、AI医疗、AI自动驾驶】、AI模型部署落地实战【CUDA、TensorRT、NCNN、OpenVINO、MNN、ONNXRuntime以及地平线框架等】,欢迎扫描下方二维码,加入集智书童知识星球,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!