
卡通化-二次元的你长什么样
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:CVPy

文末可以自己尝试下卡通化效果~
CVPR2020收录了一篇卡通化的文章,Xinrui Wang和Jinze Yu的《Learning to Cartoonize Using White-box Cartoon Representations》。可以把人物或者风景画转换为卡通风格的图片,效果非常惊艳。
相比于之前深度学习为人诟病的“黑盒”学习,文章中提出了生成卡通化图片的“白盒”表示法,将图像分解为三种卡通表示,指导网络优化生成卡通照片,三种表示分别是surface表示、structure表示、texture表示。

我个人的理解是,图像的三种表示分别是表示图像的低频特征、中频(结构)特征和高频特征,就像是从远处、不远处和近处的视角分别看同一个人的过程:
低频表示就是图像的整体外观,去掉了所有的纹理和细节。就像是遥望一个人,重点在“遥望”二字。这时只有一个整体的、模糊的观感,能看到这是一个人形生物,只能看到人身上衣服的主色调等信息,人物与周围背景的边界是模糊不清的。近似的人可以摘掉眼镜看看周围,近视700度的我摘了眼镜确认了下,大致就是这种感觉没跑了。 结构表示或者中频表示,就像是更近一点看这个人,但是距离感仍然在,鼻子眼睛等细节还是看不清楚,但是人物轮廓甚至上下衣的轮廓可以看清了,仍然看不清脸。各部分的主色调也更加清晰了。 高频表示就是近看了,细节、纹理和更精细的轮廓等信息都能看到了,这个时候就是所谓“有鼻子有眼”了。
图像被分解为surface表示、structure表示、texture表示之后,卡通化的任务也就比之前端对端的黑盒式学习明确了很多。作者提出用三个独立的模块分别去学习图像的这三种表示,即三个模块分别提取图像的低频、中频和高频的特征。
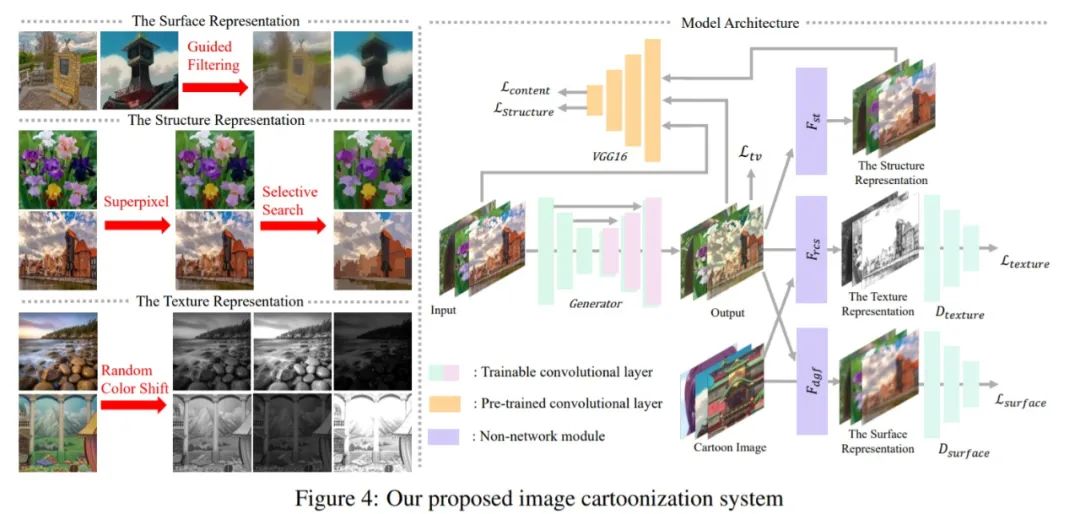
文章提出了一个包含一个生成器G(Generator)和两个判别器Ds(D_surface)和Dt(D_texture)的GAN框架。
Ds用于判别模型从源图像中提取的图像的低频表示与卡通图片(标注)
Dt用于判别模型从源图像中提取的图像的高频表示与卡通图片(标注)
用预训练的VGG网络提取源图像的high-leval特征,并在提取的结构(中频)特征和输出之间以及输入照片和输出之间对全局内容施加空间约束
过程可以理解为,
将输入图像通过导向滤波器处理,得到低频表示; 通过超像素处理,得到中频表示; 通过随机色彩变幻得到高频表示。 卡通图像也一样。
将GAN生成器产生的fake_image分别于上述表示结果做损失。其中
纹理(中频)表示与表面(低频)表示通过判别器得到损失 中频特征比较复杂,fake_image的中频表示与fake_image,输入图像与fake_image,分别通过vgg19网络抽取特征,进行损失的计算。
总损失由以上各种损失加权,可以通过改变损失函数中每个特征loss的权重来调整卡通化结果的样式。
这样处理之后,对于大部分图片的卡通化处理都非常惊艳。来几张图看看效果吧。


想自己试试的小伙伴可以点击右下角阅读原文上传自己的图片尝试。