
隐写术:如何正确保护文章的版权?
阅读本文大概需要 3 分钟。
首先,我们来看一段文字:
一我日是一青技南是我一是个青每南天我更是新青的南栏我目是,青希南望我做是到青在南每我天是几青分南钟我让是你青获南得我提是高青。南
看完以后,你有什么想法?你会不会觉得我是自恋狂?神经病?复读机?脸滚键盘?
很好,那么再看下面这一句话:
一日一技是一个每天更新的栏目,希望做到在每天几分钟让你获得提高。
是不是正常多了?
但是如果我说这两段话,实际上是一样的,你信不信?
现在有4个中文汉字:我是青南,首先介绍Python的ord函数,它可以查询Unicode字符对应的Unicode码
>>> ord('我')
25105
>>> ord('是')
26159
>>> ord('青')
38738
>>> ord('南')
21335
接下来,介绍另一个函数chr。它的作用是把Unicode编码转换为Unicode字符。
例如:
>>> chr(21335)
'南'
>>> chr(38738)
'青'
最后,介绍bin函数,它可以把十进制数字转换为二进制数字:
>>> bin(6)
'0b110'
>>> bin(57)
'0b111001'
以上就是本文涉及到的全部知识。下面,开始转换。
由于Unicode是十进制数字,那么就能进一步转换为二进制数字:
>>> bin(25105)
'0b110001000010001'
把前面的0b去掉:
>>> bin(25105)[2:]
'110001000010001'
那么,我是青南转换为二进制以后,分别为:
>>> for char in '我是青南':
... print(char, bin(ord(char))[2:])
...
我 110001000010001
是 110011000101111
青 1001011101010010
南 101001101010111
那么原来那个看起来很混乱的句子是怎么生成的呢?
from itertools import cycle
signature = '我是青南'
text = '一日一技是一个每天更新的栏目,希望做到在每天几分钟让你获得提高。'
complex_text = ''
for word, sig in zip(text, cycle(signature)):
complex_text = complex_text + word + sig
print(complex_text)
运行效果如下图所示:

那么如果把我是青南先转换为他们对应的二进制字符串,然后再穿插到原文中,效果就会变成这样:
from itertools import cycle
signature_bin_list = ['110001000010001',
'110011000101111',
'1001011101010010',
'101001101010111']
text = '一日一技是一个每天更新的栏目,希望做到在每天几分钟让你获得提高。'
complex_text = ''
for word, sig in zip(text, cycle(signature_bin_list)):
complex_text = complex_text + word + sig
print(complex_text)
运行效果如下:
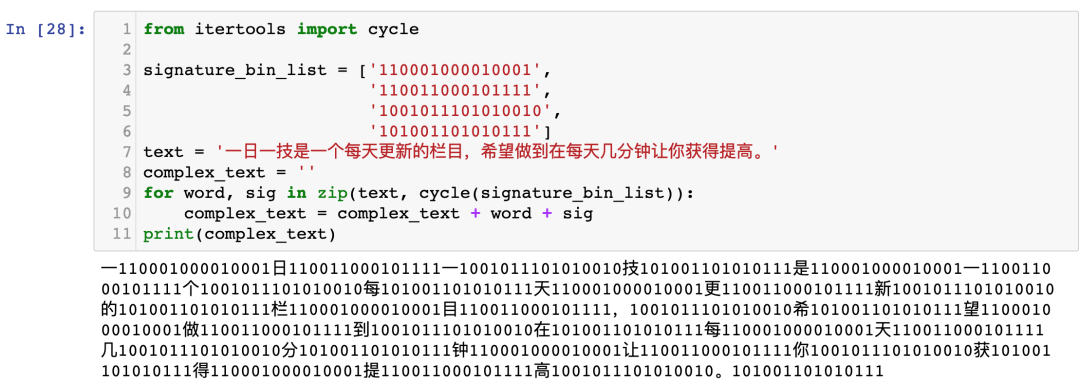
到目前为止,你肯定不知道我在干什么。
下面,我将会介绍两个神奇的数字:
8204
8205
如果我使用chr把这两个数字转换为Unicode字符会怎么样?
我们来试一试:
很奇怪对吧?什么东西都没有?难道这两个数字转换为Unicode字符以后,都是空格??
没事,我们把字符串形式的二进制数字中的1替换为chr(8204),把0替换为chr(8025)
from itertools import cycle
signature_bin_list = ['110001000010001',
'110011000101111',
'1001011101010010',
'101001101010111']
text = '一日一技是一个每天更新的栏目,希望做到在每天几分钟让你获得提高。'
complex_text = ''
for word, sig in zip(text, cycle(signature_bin_list)):
complex_text = complex_text + word + sig.replace('1', chr(8204)).replace('0', chr(8205))
print(complex_text)
运行效果是什么样的?请看下面这张图:

奇奇怪怪的符号没有了,一切都变得干干净净,就像下面这样:
一日一技是一个每天更新的栏目,希望做到在每天几分钟让你获得提高。
现在,你在电脑上把这一段话复制下来,存到记事本里面,效果如下图所示:
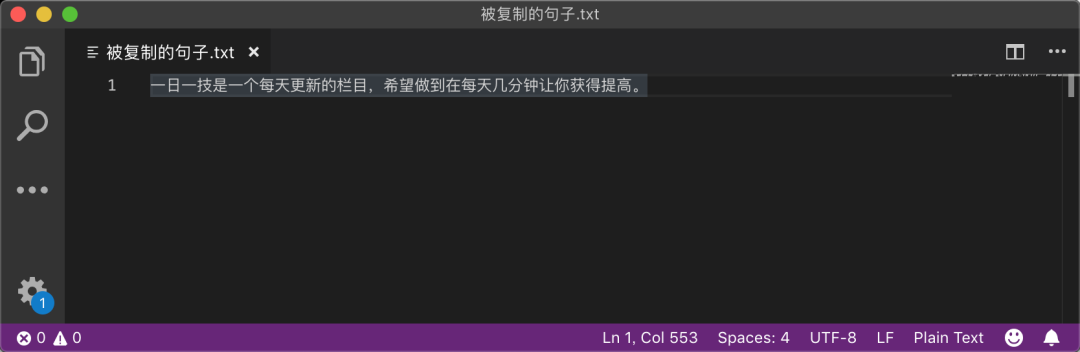
看起来很正常对吧。那么现在,用vim把它打开,你看到的将会是这样的:
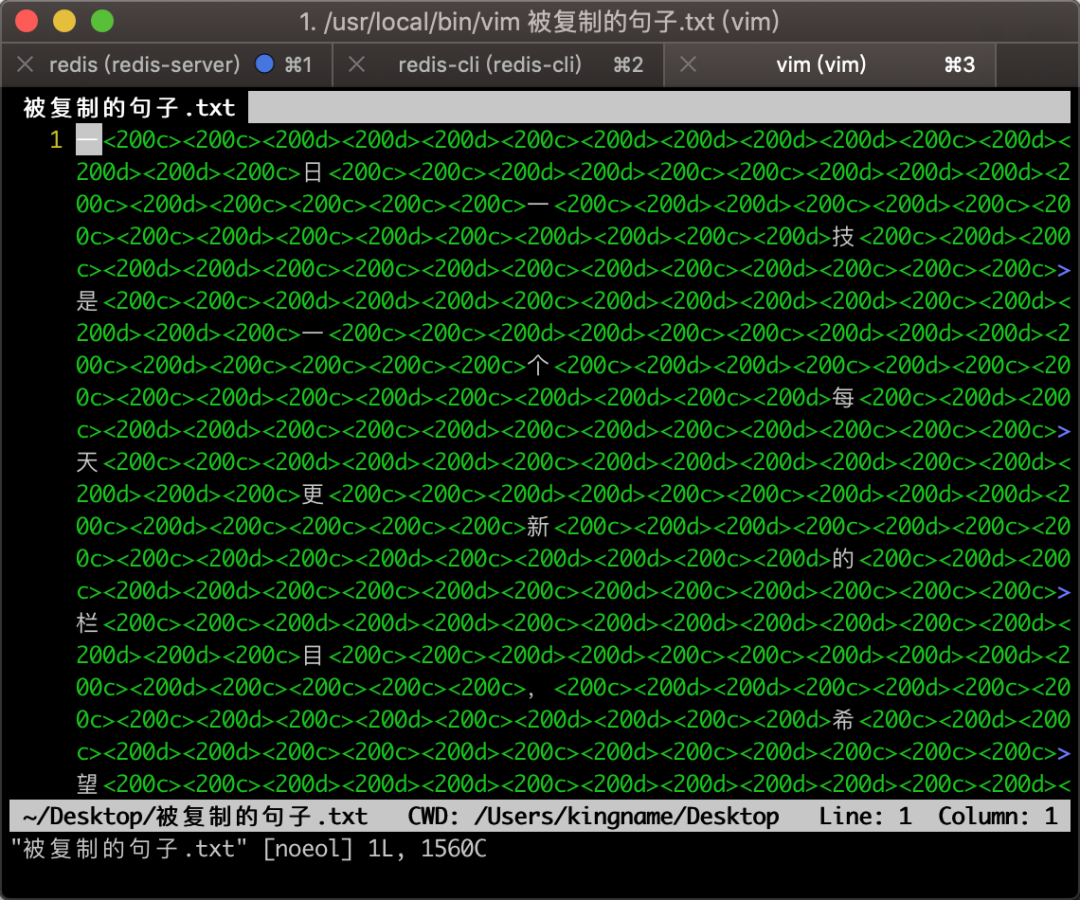
在网页上面,一切都正常,但是一旦有人复制了你的内容,直接转载到了它自己的网站上。那么你可以到法院去起诉他了,因为这些没有宽度的符号,就是证据。
推荐阅读
1
2
3
4