
Python 基于直方图的梯度提升集成方法

基于直方图的梯度增强是一种用于训练梯度增强集成中使用的更快决策树的技术。 如何在 scikit-learn库中使用基于直方图的梯度增强的实验实现。如何将基于直方图的梯度增强与 XGBoost和LightGBM第三方库结合使用。
直方图梯度提升 Scikit-Learn直方图梯度增强 XGBoost直方图梯度增强 LightGBM的直方图梯度增强
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.HistGradientBoostingClassifier.html)和HistGradientBoostingRegressor(https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.HistGradientBoostingRegressor.html)类中提供。为了使用这些类,必须在项目中添加额外的一行,以表明您很高兴使用这些实验技术,并且它们的行为可能随库的后续发行版而改变。# explicitly require this experimental feature
from sklearn.experimental import enable_hist_gradient_boosting
bin,可以通过“ max_bins”参数进行设置。将此值设置为较小的值(例如50或100)可能会进一步提高效率,尽管可能会牺牲一些模型技能。可以通过“ max_iter”参数设置树的数量,默认为100。# define the model
model = HistGradientBoostingClassifier(max_bins=255, max_iter=100)
# evaluate sklearn histogram gradient boosting algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
# define dataset
X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1)
# define the model
model = HistGradientBoostingClassifier(max_bins=255, max_iter=100)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model and collect the scores
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Accuracy: 0.943 (0.007)
# compare number of bins for sklearn histogram gradient boosting
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in [10, 50, 100, 150, 200, 255]:
models[str(i)] = HistGradientBoostingClassifier(max_bins=i, max_iter=100)
return models
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model and collect the scores
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
# evaluate the model and collect the scores
scores = evaluate_model(model, X, y)
# stores the results
results.append(scores)
names.append(name)
# report performance along the way
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
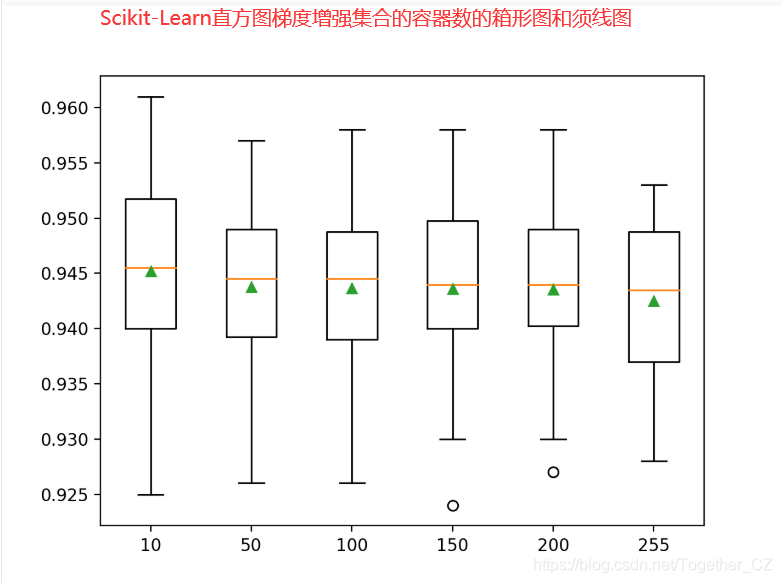
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
>10 0.945 (0.009)
>50 0.944 (0.007)
>100 0.944 (0.008)
>150 0.944 (0.008)
>200 0.944 (0.007)
>255 0.943 (0.007)
pip install xgboost
“ tree_method”参数设置为“ approx”,可以将训练算法配置为使用直方图方法,并且可以通过“ max_bin”参数设置箱数。# define the model
model = XGBClassifier(tree_method='approx', max_bin=255, n_estimators=100)
# evaluate xgboost histogram gradient boosting algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from xgboost import XGBClassifier
# define dataset
X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1)
# define the model
model = XGBClassifier(tree_method='approx', max_bin=255, n_estimators=100)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model and collect the scores
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Accuracy: 0.957 (0.007)
pip install lightgbm
# define the model
model = LGBMClassifier(max_bin=255, n_estimators=100)
# evaluate lightgbm histogram gradient boosting algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=10000, n_features=100, n_informative=50, n_redundant=50, random_state=1)
# define the model
model = LGBMClassifier(max_bin=255, n_estimators=100)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate the model and collect the scores
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Accuracy: 0.942 (0.006)
sklearn.ensemble.HistGradientBoostingClassifier API.
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.HistGradientBoostingClassifier.html
sklearn.ensemble.HistGradientBoostingRegressor API.
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.HistGradientBoostingRegressor.html
XGBoost, Fast Histogram Optimized Grower, 8x to 10x Speedup
https://github.com/dmlc/xgboost/issues/1950
xgboost.XGBClassifier API.
https://xgboost.readthedocs.io/en/latest/python/python_api.html#xgboost.XGBClassifier
xgboost.XGBRegressor API.
https://xgboost.readthedocs.io/en/latest/python/python_api.html#xgboost.XGBRegressor
lightgbm.LGBMClassifier API.
https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMClassifier.html
lightgbm.LGBMRegressor API.
https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMRegressor.html
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者

更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论